1. 简介
1.1. 翻译(说明)
由[分享牛Flowable中国社区] 翻译,任何意见建议,欢迎联系QQ:3152981878。 如果想一起成为开源代码贡献人员,欢迎大家加入qq交流群为社区贡献添砖加瓦。qq贡献群:1023773998
1.2. 协议
Flowable在Apache V2 协议下发布。
1.4. 源码
Flowable的发布包里包含了大部分源码,以JAR文件方式提供。Flowable的源码也可以通过以下链接获得: https://github.com/flowable/flowable-engine
1.5. 必要的软件
1.5.1. JDK 8+
运行Flowable需要JDK 8或以上版本。可以访问 Oracle Java SE downloads页面 点击“Download JDK”按钮获取。该页面上也有安装指导。安装完成后,可以执行 java -version 。能看到JDK的版本信息就说明安装成功了。
1.5.2. IDE
可以自行选择用于Flowable开发的IDE。如果想要使用Flowable Designer,则需要Eclipse Mars或Neon。
到 Eclipse下载页面选择Eclipse版本并下载。解压下载的文件,
然后执行eclipse文件夹下的eclipse文件。手册后续有专门一章介绍如何安装我们的Eclipse Designer插件。
1.7. 实验性功能
标记有[实验性]的章节介绍的功能还不够稳定。
.impl.包下的类都是内部实现类,不保证稳定。但是,在用户手册中作为配置参数介绍的类则是被官方支持的,可以保证稳定。
1.8. 内部实现类
在JAR文件中,所有.impl.包下的类(比如org.flowable.engine.impl.db)都是实现类,只应在内部使用。实现类中的所有类或接口都不保证稳定。
1.9. 版本策略
使用三个整数的形式标记版本:MAJOR.MINOR.MICRO。其中 MAJOR版本代表核心引擎的演进。MINOR版本代表新功能与新API。MICRO版本代表bug修复与改进。
总的来说,Flowable希望在MINOR与MICRO版本中,对所有非内部实现类保持“源代码兼容性”,即应用可以正确构建,且不改变语义。Flowable也希望在MINOR与MICRO版本中,保持“二进制兼容性”,即用新版本的Flowable直接替换老版本的Jar文件,仍然可以正常工作。
如果在MINOR版本中修改了API,将保留原有版本,并使用@Deprecated注解。这种废弃的API将在两个MINOR版本之后移除。
2. 开始
2.1. Flowable是什么?
Flowable是一个使用Java编写的轻量级业务流程引擎。Flowable流程引擎可用于部署BPMN 2.0流程定义(用于定义流程的行业XML标准), 创建这些流程定义的流程实例,进行查询,访问运行中或历史的流程实例与相关数据,等等。这个章节将用一个可以在你自己的开发环境中使用的例子,逐步介绍各种概念与API。
Flowable可以十分灵活地加入你的应用/服务/构架。可以将JAR形式发布的Flowable库加入应用或服务,来嵌入引擎。 以JAR形式发布使Flowable可以轻易加入任何Java环境:Java SE;Tomcat、Jetty或Spring之类的servlet容器;JBoss或WebSphere之类的Java EE服务器,等等。 另外,也可以使用Flowable REST API进行HTTP调用。也有许多Flowable应用(Flowable Modeler, Flowable Admin, Flowable IDM 与 Flowable Task),提供了直接可用的UI示例,可以使用流程与任务。
所有使用Flowable方法的共同点是核心引擎。核心引擎是一组服务的集合,并提供管理与执行业务流程的API。 下面的教程从设置与使用核心引擎的介绍开始。后续章节都建立在之前章节中获取的知识之上。
-
第一节展示了以最简单的方式运行Flowable的方法:只使用Java SE的标准Java main方法。这里也会介绍许多核心概念与API。
-
Flowable REST API章节展示了如何通过REST运行及使用相同的API。
-
Flowable APP章节将介绍直接可用的Flowable UI示例的基本方法。
2.2. Flowable与Activiti
Flowable是Activiti(Alfresco持有的注册商标)的fork。在下面的章节中,你会注意到包名,配置文件等等,都使用flowable。
2.3. 构建命令行程序
2.3.1. 创建流程引擎
在这个初步教程中,将构建一个简单的例子,以展示如何创建一个Flowable流程引擎,介绍一些核心概念,并展示如何使用API。 截图时使用的是Eclipse,但实际上可以使用任何IDE。我们使用Maven获取Flowable依赖及管理构建,但是类似的任何其它方法也都可以使用(Gradle,Ivy,等等)。
我们将构建的例子是一个简单的请假(holiday request)流程:
-
雇员(employee)申请几天的假期
-
经理(manager)批准或驳回申请
-
我们会模拟将申请注册到某个外部系统,并给雇员发送结果邮件
首先,通过File → New → Other → Maven Project创建一个新的Maven项目
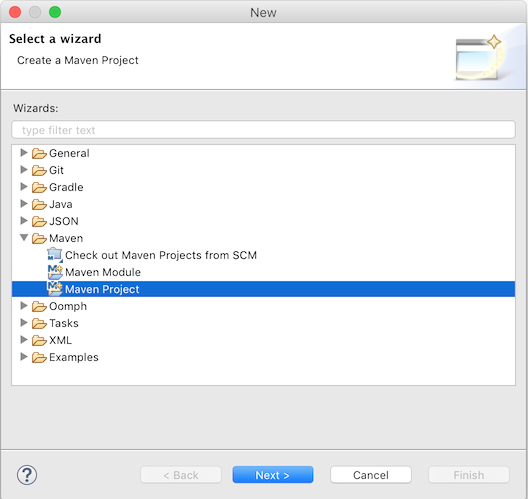
在下一界面中,选中'create a simple project (skip archetype selection)'
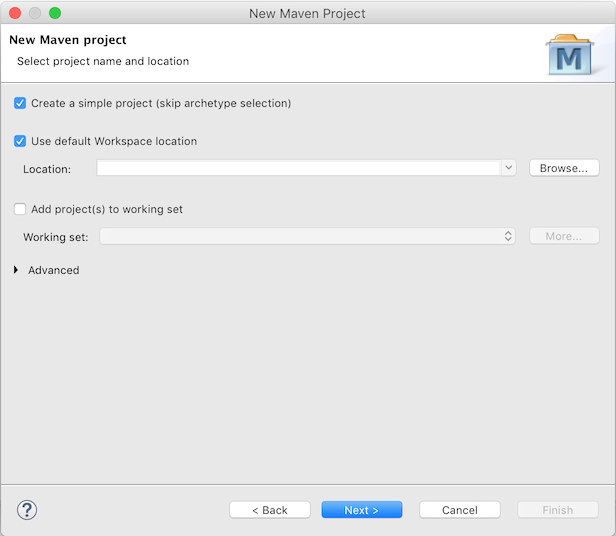
填入'Group Id'与'Artifact id':
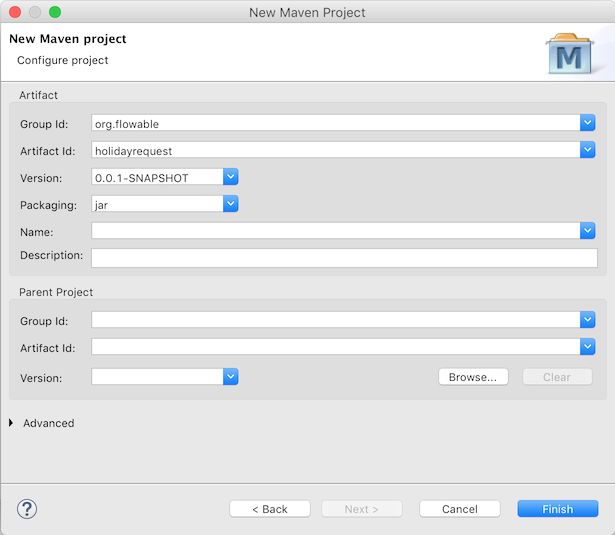
这样就建立了空的Maven项目,然后添加两个依赖:
-
Flowable流程引擎。使我们可以创建一个ProcessEngine流程引擎对象,并访问Flowable API。
-
一个内存数据库。本例中为H2,因为Flowable引擎在运行流程实例时,需要使用数据库来存储执行与历史数据。 请注意H2依赖包含了数据库及驱动。如果使用其他数据库(例如PostgreSQL,MySQL等),需要添加对应的数据库驱动依赖。
在pom.xml文件中添加下列行:
<dependencies>
<dependency>
<groupId>org.flowable</groupId>
<artifactId>flowable-engine</artifactId>
<version>6.5.0.event-SNAPSHOT</version>
</dependency>
<dependency>
<groupId>com.h2database</groupId>
<artifactId>h2</artifactId>
<version>1.3.176</version>
</dependency>
</dependencies>如果由于某些原因,依赖JAR无法自动获取,可以右键点击项目,并选择'Maven → Update Project'以强制手动刷新(一般不会需要这么操作)。 在这个项目中的'Maven Dependencies'下,可以看到flowable-engine与许多其他(传递的)依赖。
创建一个新的Java类,并添加标准的Java main方法:
package org.flowable;
public class HolidayRequest {
public static void main(String[] args) {
}
}首先要做的是初始化ProcessEngine流程引擎实例。这是一个线程安全的对象,因此通常只需要在一个应用中初始化一次。 ProcessEngine由ProcessEngineConfiguration实例创建。该实例可以配置与调整流程引擎的设置。 通常使用一个配置XML文件创建ProcessEngineConfiguration,但是(像在这里做的一样)也可以编程方式创建它。 ProcessEngineConfiguration所需的最小配置,是数据库JDBC连接:
package org.flowable;
import org.flowable.engine.ProcessEngine;
import org.flowable.engine.ProcessEngineConfiguration;
import org.flowable.engine.impl.cfg.StandaloneProcessEngineConfiguration;
public class HolidayRequest {
public static void main(String[] args) {
ProcessEngineConfiguration cfg = new StandaloneProcessEngineConfiguration()
.setJdbcUrl("jdbc:h2:mem:flowable;DB_CLOSE_DELAY=-1")
.setJdbcUsername("sa")
.setJdbcPassword("")
.setJdbcDriver("org.h2.Driver")
.setDatabaseSchemaUpdate(ProcessEngineConfiguration.DB_SCHEMA_UPDATE_TRUE);
ProcessEngine processEngine = cfg.buildProcessEngine();
}
}在上面的代码中,第10行创建了一个独立(standalone)配置对象。这里的'独立'指的是引擎是完全独立创建及使用的(而不是在Spring环境中使用,这时需要使用SpringProcessEngineConfiguration类代替)。第11至14行中,传递了一个内存H2数据库实例的JDBC连接参数。 重要:请注意这样的数据库在JVM重启后会消失。如果需要永久保存数据,需要切换为持久化数据库,并相应切换连接参数。 第15行中,设置了true,确保在JDBC参数连接的数据库中,数据库表结构不存在时,会创建相应的表结构。 另外,Flowable也提供了一组SQL文件,可用于手动创建所有表的数据库表结构。
然后使用这个配置创建ProcessEngine对象(第17行)。
这样就可以运行了。在Eclipse中最简单的方法是右键点击类文件,选择Run As → Java Application :
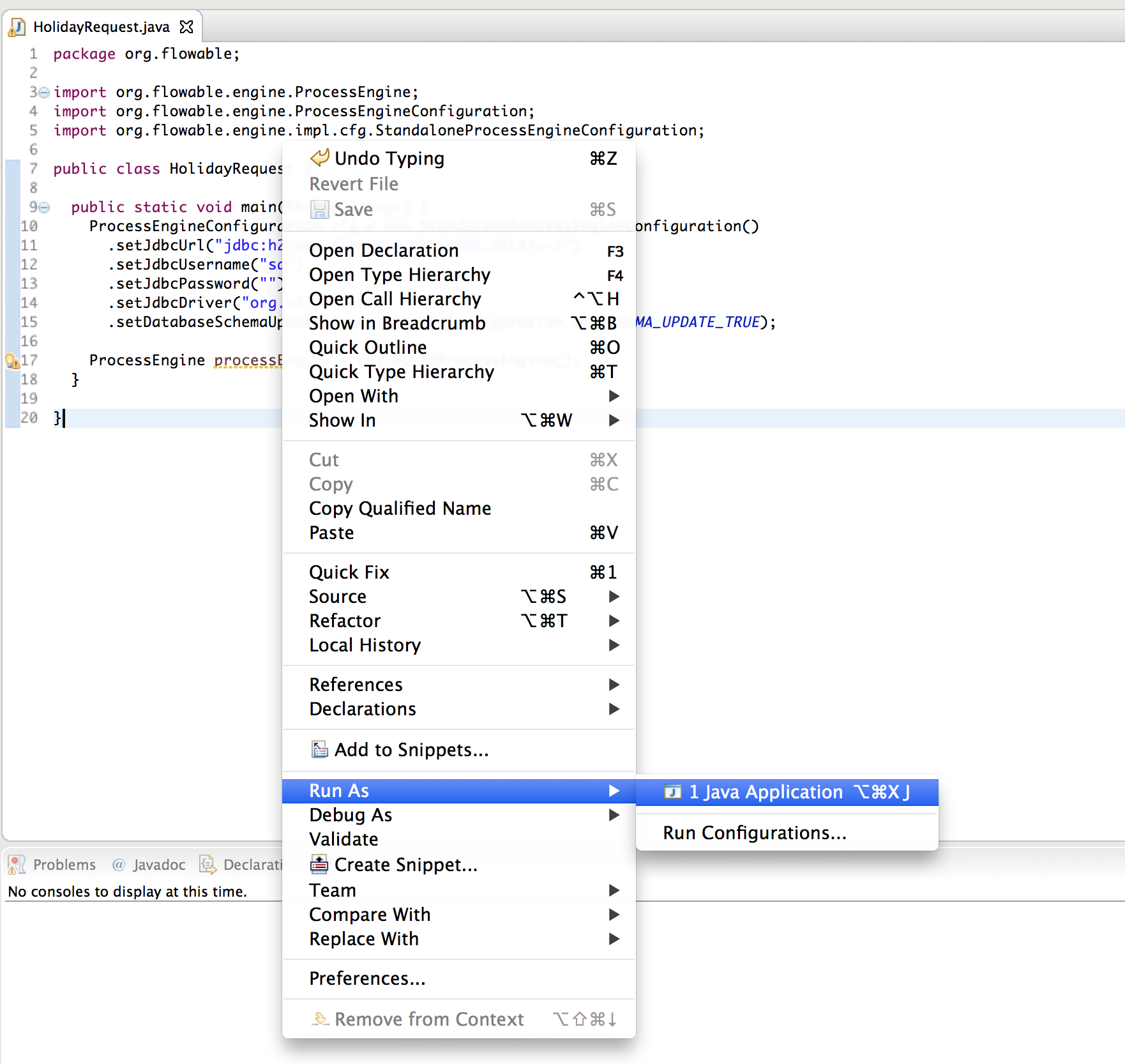
应用运行没有问题,但也没有在控制台提供有用的信息,只有一条消息提示日志没有正确配置:
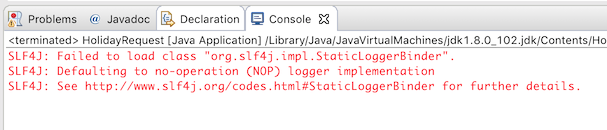
Flowable使用SLF4J作为内部日志框架。在这个例子中,我们使用log4j作为SLF4J的实现。因此在pom.xml文件中添加下列依赖:
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.21</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.21</version>
</dependency>Log4j需要一个配置文件。在src/main/resources文件夹下添加log4j.properties文件,并写入下列内容:
log4j.rootLogger=DEBUG, CA
log4j.appender.CA=org.apache.log4j.ConsoleAppender
log4j.appender.CA.layout=org.apache.log4j.PatternLayout
log4j.appender.CA.layout.ConversionPattern= %d{hh:mm:ss,SSS} [%t] %-5p %c %x - %m%n
重新运行应用。应该可以看到关于引擎启动与创建数据库表结构的提示日志:
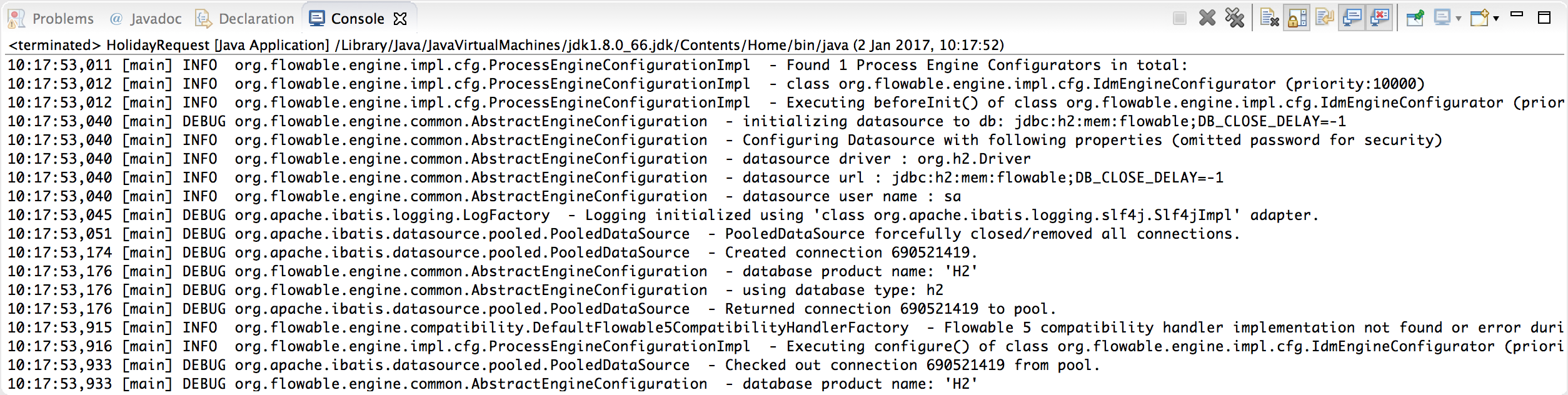
这样就得到了一个启动可用的流程引擎。接下来为它提供一个流程!
2.3.2. 部署流程定义
我们要构建的流程是一个非常简单的请假流程。Flowable引擎需要流程定义为BPMN 2.0格式,这是一个业界广泛接受的XML标准。 在Flowable术语中,我们将其称为一个流程定义(process definition)。一个流程定义可以启动多个流程实例(process instance)。流程定义可以看做是重复执行流程的蓝图。 在这个例子中,流程定义定义了请假的各个步骤,而一个流程实例对应某个雇员提出的一个请假申请。
BPMN 2.0存储为XML,并包含可视化的部分:使用标准方式定义了每个步骤类型(人工任务,自动服务调用,等等)如何呈现,以及如何互相连接。这样BPMN 2.0标准使技术人员与业务人员能用双方都能理解的方式交流业务流程。
我们要使用的流程定义为:
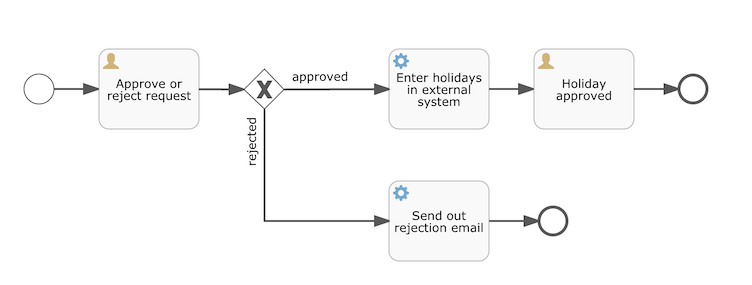
这个流程应该已经十分自我解释了。但为了明确起见,说明一下几个要点:
-
我们假定启动流程需要提供一些信息,例如雇员名字、请假时长以及说明。当然,这些可以单独建模为流程中的第一步。 但是如果将它们作为流程的“输入信息”,就能保证只有在实际请求时才会建立一个流程实例。否则(将提交作为流程的第一步),用户可能在提交之前改变主意并取消,但流程实例已经创建了。 在某些场景中,就可能影响重要的指标(例如启动了多少申请,但还未完成),取决于业务目标。
-
左侧的圆圈叫做启动事件(start event)。这是一个流程实例的起点。
-
第一个矩形是一个用户任务(user task)。这是流程中人类用户操作的步骤。在这个例子中,经理需要批准或驳回申请。
-
取决于经理的决定,排他网关(exclusive gateway) (带叉的菱形)会将流程实例路由至批准或驳回路径。
-
如果批准,则需要将申请注册至某个外部系统,并跟着另一个用户任务,将经理的决定通知给申请人。当然也可以改为发送邮件。
-
如果驳回,则为雇员发送一封邮件通知他。
一般来说,这样的流程定义使用可视化建模工具建立,如Flowable Designer(Eclipse)或Flowable Web Modeler(Web应用)。
但在这里我们直接撰写XML,以熟悉BPMN 2.0及其概念。
与上面展示的流程图对应的BPMN 2.0 XML在下面显示。请注意这只包含了“流程部分”。如果使用图形化建模工具,实际的XML文件还将包含“可视化部分”,用于描述图形信息,如流程定义中各个元素的坐标(所有的图形化信息包含在XML的BPMNDiagram标签中,作为definitions标签的子元素)。
将下面的XML保存在src/main/resources文件夹下名为holiday-request.bpmn20.xml的文件中。
<?xml version="1.0" encoding="UTF-8"?>
<definitions xmlns="http://www.omg.org/spec/BPMN/20100524/MODEL"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:xsd="http://www.w3.org/2001/XMLSchema"
xmlns:bpmndi="http://www.omg.org/spec/BPMN/20100524/DI"
xmlns:omgdc="http://www.omg.org/spec/DD/20100524/DC"
xmlns:omgdi="http://www.omg.org/spec/DD/20100524/DI"
xmlns:flowable="http://flowable.org/bpmn"
typeLanguage="http://www.w3.org/2001/XMLSchema"
expressionLanguage="http://www.w3.org/1999/XPath"
targetNamespace="http://www.flowable.org/processdef">
<process id="holidayRequest" name="Holiday Request" isExecutable="true">
<startEvent id="startEvent"/>
<sequenceFlow sourceRef="startEvent" targetRef="approveTask"/>
<userTask id="approveTask" name="Approve or reject request"/>
<sequenceFlow sourceRef="approveTask" targetRef="decision"/>
<exclusiveGateway id="decision"/>
<sequenceFlow sourceRef="decision" targetRef="externalSystemCall">
<conditionExpression xsi:type="tFormalExpression">
<![CDATA[
${approved}
]]>
</conditionExpression>
</sequenceFlow>
<sequenceFlow sourceRef="decision" targetRef="sendRejectionMail">
<conditionExpression xsi:type="tFormalExpression">
<![CDATA[
${!approved}
]]>
</conditionExpression>
</sequenceFlow>
<serviceTask id="externalSystemCall" name="Enter holidays in external system"
flowable:class="org.flowable.CallExternalSystemDelegate"/>
<sequenceFlow sourceRef="externalSystemCall" targetRef="holidayApprovedTask"/>
<userTask id="holidayApprovedTask" name="Holiday approved"/>
<sequenceFlow sourceRef="holidayApprovedTask" targetRef="approveEnd"/>
<serviceTask id="sendRejectionMail" name="Send out rejection email"
flowable:class="org.flowable.SendRejectionMail"/>
<sequenceFlow sourceRef="sendRejectionMail" targetRef="rejectEnd"/>
<endEvent id="approveEnd"/>
<endEvent id="rejectEnd"/>
</process>
</definitions>第2至11行看起来挺吓人,但其实在大多数的流程定义中都是一样的。这是一种样板文件,需要与BPMN 2.0标准规范完全一致。
每一个步骤(在BPMN 2.0术语中称作活动(activity))都有一个id属性,为其提供一个在XML文件中唯一的标识符。所有的活动都可以设置一个名字,以提高流程图的可读性。
活动之间通过顺序流(sequence flow)连接,在流程图中是一个有向箭头。在执行流程实例时,执行(execution)会从启动事件沿着顺序流流向下一个活动。
离开排他网关(带有X的菱形)的顺序流很特别:都以表达式(expression)的形式定义了条件(condition) (见第25至32行)。当流程实例的执行到达这个网关时,会计算条件,并使用第一个计算为true的顺序流。这就是排他的含义:只选择一个。当然如果需要不同的路由策略,可以使用其他类型的网关。
这里用作条件的表达式为${approved},这是${approved == true}的简写。变量’approved’被称作流程变量(process variable)。流程变量是持久化的数据,与流程实例存储在一起,并可以在流程实例的生命周期中使用。在这个例子里,我们需要在特定的地方(当经理用户任务提交时,或者以Flowable的术语来说,完成(complete)时)设置这个流程变量,因为这不是流程实例启动时就能获取的数据。
现在我们已经有了流程BPMN 2.0 XML文件,下来需要将它部署(deploy)到引擎中。部署一个流程定义意味着:
-
流程引擎会将XML文件存储在数据库中,这样可以在需要的时候获取它。
-
流程定义转换为内部的、可执行的对象模型,这样使用它就可以启动流程实例。
将流程定义部署至Flowable引擎,需要使用RepositoryService,其可以从ProcessEngine对象获取。使用RepositoryService,可以通过XML文件的路径创建一个新的部署(Deployment),并调用deploy()方法实际执行:
RepositoryService repositoryService = processEngine.getRepositoryService();
Deployment deployment = repositoryService.createDeployment()
.addClasspathResource("holiday-request.bpmn20.xml")
.deploy();我们现在可以通过API查询验证流程定义已经部署在引擎中(并学习一些API)。通过RepositoryService创建的ProcessDefinitionQuery对象实现。
ProcessDefinition processDefinition = repositoryService.createProcessDefinitionQuery()
.deploymentId(deployment.getId())
.singleResult();
System.out.println("Found process definition : " + processDefinition.getName());2.3.3. 启动流程实例
现在已经在流程引擎中部署了流程定义,因此可以使用这个流程定义作为“蓝图”启动流程实例。
要启动流程实例,需要提供一些初始化流程变量。一般来说,可以通过呈现给用户的表单,或者在流程由其他系统自动触发时通过REST API,来获取这些变量。在这个例子里,我们简化为使用java.util.Scanner类在命令行输入一些数据:
Scanner scanner= new Scanner(System.in);
System.out.println("Who are you?");
String employee = scanner.nextLine();
System.out.println("How many holidays do you want to request?");
Integer nrOfHolidays = Integer.valueOf(scanner.nextLine());
System.out.println("Why do you need them?");
String description = scanner.nextLine();接下来,我们使用RuntimeService启动一个流程实例。收集的数据作为一个java.util.Map实例传递,其中的键就是之后用于获取变量的标识符。这个流程实例使用key启动。这个key就是BPMN 2.0 XML文件中设置的id属性,在这个例子里是holidayRequest。
(请注意:除了使用key之外,在后面你还会看到有很多其他方式启动一个流程实例)
<process id="holidayRequest" name="Holiday Request" isExecutable="true">RuntimeService runtimeService = processEngine.getRuntimeService();
Map<String, Object> variables = new HashMap<String, Object>();
variables.put("employee", employee);
variables.put("nrOfHolidays", nrOfHolidays);
variables.put("description", description);
ProcessInstance processInstance =
runtimeService.startProcessInstanceByKey("holidayRequest", variables);在流程实例启动后,会创建一个执行(execution),并将其放在启动事件上。从这里开始,这个执行沿着顺序流移动到经理审批的用户任务,并执行用户任务行为。这个行为将在数据库中创建一个任务,该任务可以之后使用查询找到。用户任务是一个等待状态(wait state),引擎会停止执行,返回API调用处。
2.3.4. 另一个话题:事务
在Flowable中,数据库事务扮演了关键角色,用于保证数据一致性,并解决并发问题。当调用Flowable API时,默认情况下,所有操作都是同步的,并处于同一个事务下。这意味着,当方法调用返回时,会启动并提交一个事务。
流程启动后,会有一个数据库事务从流程实例启动时持续到下一个等待状态。在这个例子里,指的是第一个用户任务。当引擎到达这个用户任务时,状态会持久化至数据库,提交事务,并返回API调用处。
在Flowable中,当一个流程实例运行时,总会有一个数据库事务从前一个等待状态持续到下一个等待状态。数据持久化之后,可能在数据库中保存很长时间,甚至几年,直到某个API调用使流程实例继续执行。请注意当流程处在等待状态时,不会消耗任何计算或内存资源,直到下一次APi调用。
在这个例子中,当第一个用户任务完成时,会启动一个数据库事务,从用户任务开始,经过排他网关(自动逻辑),直到第二个用户任务。或通过另一条路径直接到达结束。
2.3.5. 查询与完成任务
在更实际的应用中,会为雇员及经理提供用户界面,让他们可以登录并查看任务列表。其中可以看到作为流程变量存储的流程实例数据,并决定如何操作任务。在这个例子中,我们通过执行API调用来模拟任务列表,通常这些API都是由UI驱动的服务在后台调用的。
我们还没有为用户任务配置办理人。我们想将第一个任务指派给"经理(managers)"组,而第二个用户任务指派给请假申请的提交人。因此需要为第一个任务添加candidateGroups属性:
<userTask id="approveTask" name="Approve or reject request" flowable:candidateGroups="managers"/>并如下所示为第二个任务添加assignee属性。请注意我们没有像上面的’managers’一样使用静态值,而是使用一个流程变量动态指派。这个流程变量是在流程实例启动时传递的:
<userTask id="holidayApprovedTask" name="Holiday approved" flowable:assignee="${employee}"/>要获得实际的任务列表,需要通过TaskService创建一个TaskQuery。我们配置这个查询只返回’managers’组的任务:
TaskService taskService = processEngine.getTaskService();
List<Task> tasks = taskService.createTaskQuery().taskCandidateGroup("managers").list();
System.out.println("You have " + tasks.size() + " tasks:");
for (int i=0; i<tasks.size(); i++) {
System.out.println((i+1) + ") " + tasks.get(i).getName());
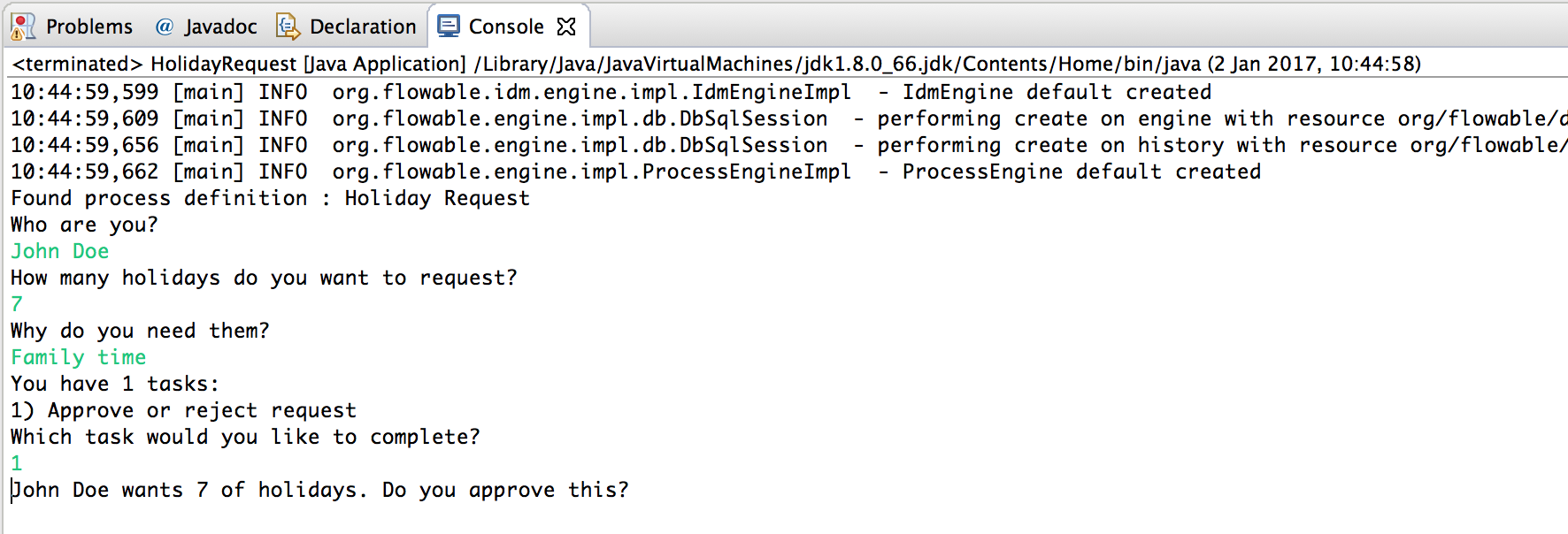
}可以使用任务Id获取特定流程实例的变量,并在屏幕上显示实际的申请:
System.out.println("Which task would you like to complete?");
int taskIndex = Integer.valueOf(scanner.nextLine());
Task task = tasks.get(taskIndex - 1);
Map<String, Object> processVariables = taskService.getVariables(task.getId());
System.out.println(processVariables.get("employee") + " wants " +
processVariables.get("nrOfHolidays") + " of holidays. Do you approve this?");运行结果像下面这样:
经理现在就可以完成任务了。在现实中,这通常意味着由用户提交一个表单。表单中的数据作为流程变量传递。在这里,我们在完成任务时传递带有’approved’变量(这个名字很重要,因为之后会在顺序流的条件中使用!)的map来模拟:
boolean approved = scanner.nextLine().toLowerCase().equals("y");
variables = new HashMap<String, Object>();
variables.put("approved", approved);
taskService.complete(task.getId(), variables);现在任务完成,并会在离开排他网关的两条路径中,基于’approved’流程变量选择一条。
2.3.6. 实现JavaDelegate
拼图还缺了一块:我们还没有实现申请通过后执行的自动逻辑。在BPMN 2.0 XML中,这是一个服务任务(service task):
<serviceTask id="externalSystemCall" name="Enter holidays in external system"
flowable:class="org.flowable.CallExternalSystemDelegate"/>在现实中,这个逻辑可以做任何事情:向某个系统发起一个HTTP REST服务调用,或调用某个使用了好几十年的系统中的遗留代码。我们不会在这里实现实际的逻辑,而只是简单的日志记录流程。
创建一个新的类(在Eclipse里File → New → Class),填入org.flowable作为包名,CallExternalSystemDelegate作为类名。让这个类实现org.flowable.engine.delegate.JavaDelegate接口,并实现execute方法:
package org.flowable;
import org.flowable.engine.delegate.DelegateExecution;
import org.flowable.engine.delegate.JavaDelegate;
public class CallExternalSystemDelegate implements JavaDelegate {
public void execute(DelegateExecution execution) {
System.out.println("Calling the external system for employee "
+ execution.getVariable("employee"));
}
}当执行到达服务任务时,会初始化并调用BPMN 2.0 XML中所引用的类。
现在执行这个例子的时候,就会显示出日志信息,说明已经执行了自定义逻辑:
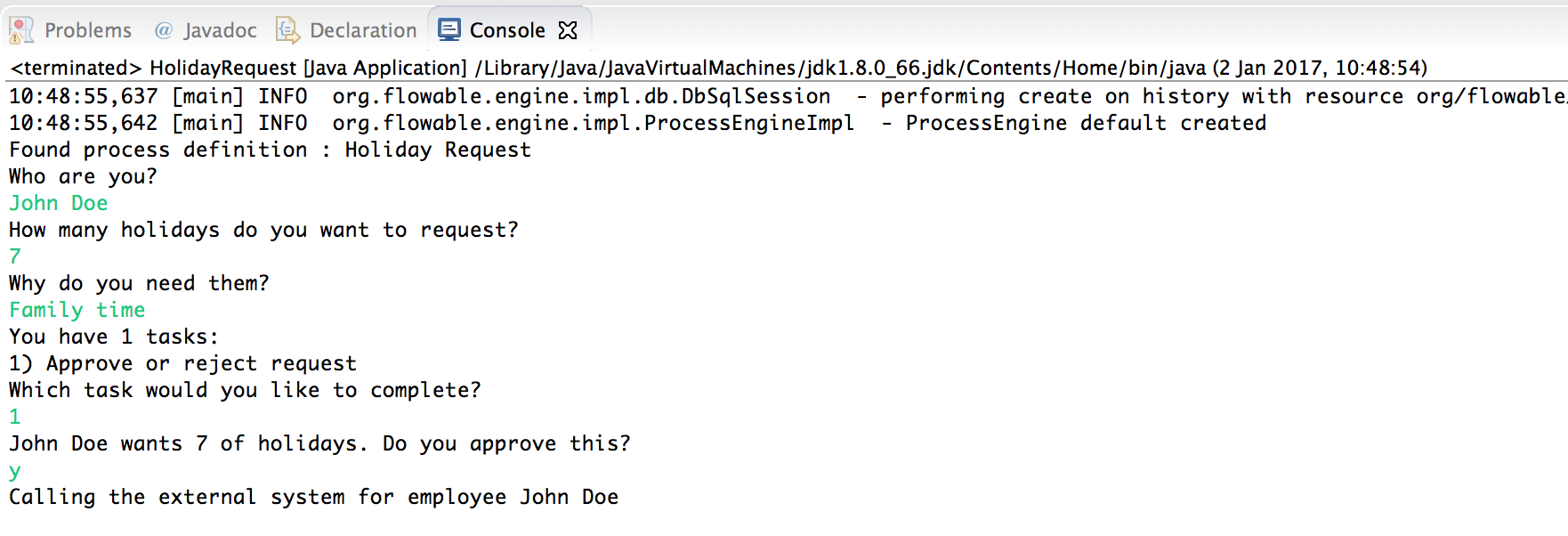
2.3.7. 使用历史数据
选择使用Flowable这样的流程引擎的原因之一,是它可以自动存储所有流程实例的审计数据或历史数据。这些数据可以用于创建报告,深入展现组织运行的情况,瓶颈在哪里,等等。
例如,如果希望显示流程实例已经执行的时间,就可以从ProcessEngine获取HistoryService,并创建历史活动(historical activities)的查询。在下面的代码片段中,可以看到我们添加了一些额外的过滤条件:
-
只选择一个特定流程实例的活动
-
只选择已完成的活动
结果按照结束时间排序,代表其执行顺序。
HistoryService historyService = processEngine.getHistoryService();
List<HistoricActivityInstance> activities =
historyService.createHistoricActivityInstanceQuery()
.processInstanceId(processInstance.getId())
.finished()
.orderByHistoricActivityInstanceEndTime().asc()
.list();
for (HistoricActivityInstance activity : activities) {
System.out.println(activity.getActivityId() + " took "
+ activity.getDurationInMillis() + " milliseconds");
}再次运行例子,可以看到控制台中显示:
startEvent took 1 milliseconds approveTask took 2638 milliseconds decision took 3 milliseconds externalSystemCall took 1 milliseconds
2.3.8. 小结
这个教程介绍了很多Flowable与BPMN 2.0的概念与术语,也展示了如何编程使用Flowable API。
当然,这只是个开始。下面的章节会更深入介绍许多Flowable引擎支持的选项与特性。其他章节介绍安装与使用Flowable引擎的不同方法,并详细介绍了所有可用的BPMN 2.0结构。
2.4. 开始使用Flowable REST API
这个章节展示了与上一章节相同的例子:部署一个流程定义,启动一个流程实例,获取任务列表并完成一个任务。最好先快速浏览上一章节以了解所做的事情。
这一次,将使用Flowable REST API而不是Java API。你很快就会意识到REST API与Java API紧密关联。只要了解一个,就能很快学会另一个。
可以在REST API章节找到Flowable REST API的完整细节。
2.4.1. 安装REST应用
使用Tomcat的步骤如下:
-
下载并解压缩最新的Tomcat zip文件(在Tomcat网站中选择’Core’发行版)。
-
将flowable-rest.war文件从解压的Flowable发行版的wars文件夹中复制到解压的Tomcat文件夹下的webapps文件夹下。
-
使用命令行,转到Tomcat文件夹下的bin文件夹。
-
执行'./catalina run'启动Tomcat服务器。
在服务启动过程中,会显示一些Flowable日志信息。在最后显示的一条类似'INFO [main] org.apache.catalina.startup.Catalina.start Server startup in xyz ms'的消息标志着服务器已经启动,可以接受请求。请注意默认情况下,使用H2内存数据库,这意味着数据在服务器重启后会丢失。
在下面的章节中,我们使用cURL展示各种REST调用。所有的REST调用默认都使用基本认证保护,所有的调用的用户都是 rest-admin,密码为’test'。
在启动后,通过执行下列命令验证应用运行正常:
curl --user rest-admin:test http://localhost:8080/flowable-rest/service/management/engine
如果能获得正确的json响应,则说明REST API已经启动并在工作。
2.4.2. 部署流程定义
第一步是部署一个流程定义。使用REST API时,需要将一个.bpmn20.xml文件(或对于多个流程引擎,一个.zip文件)作为’multipart/formdata’上传:
curl --user rest-admin:test -F "file=@holiday-request.bpmn20.xml" http://localhost:8080/flowable-rest/service/repository/deployments
要验证流程定义已经正确部署,可以请求流程定义的列表:
curl --user rest-admin:test http://localhost:8080/flowable-rest/service/repository/process-definitions
这将返回当前引擎中部署的所有流程定义的列表。
2.4.3. 启动流程实例
使用REST API启动一个流程实例与使用Java API很像:提供key作为流程定义的标识,并使用一个map作为初始化流程变量:
curl --user rest-admin:test -H "Content-Type: application/json" -X POST -d '{ "processDefinitionKey":"holidayRequest", "variables": [ { "name":"employee", "value": "John Doe" }, { "name":"nrOfHolidays", "value": 7 }]}' http://localhost:8080/flowable-rest/service/runtime/process-instances
将返回:
{"id":"43","url":"http://localhost:8080/flowable-rest/service/runtime/process-instances/43","businessKey":null,"suspended":false,"ended":false,"processDefinitionId":"holidayRequest:1:42","processDefinitionUrl":"http://localhost:8080/flowable-rest/service/repository/process-definitions/holidayRequest:1:42","activityId":null,"variables":[],"tenantId":"","completed":false}
2.4.4. 任务列表与完成任务
当流程实例启动后,第一个任务会指派给’managers’组。要获取这个组的所有任务,可以通过REST API进行任务查询:
curl --user rest-admin:test -H "Content-Type: application/json" -X POST -d '{ "candidateGroup" : "managers" }' http://localhost:8080/flowable-rest/service/query/tasks
这将返回’manager’组的所有任务的列表。
可以这样完成任务:
curl --user rest-admin:test -H "Content-Type: application/json" -X POST -d '{ "action" : "complete", "variables" : [ { "name" : "approved", "value" : true} ] }' http://localhost:8080/flowable-rest/service/runtime/tasks/25
然而,很可能会产生如下的错误:
{"message":"Internal server error","exception":"couldn't instantiate class org.flowable.CallExternalSystemDelegate"}
这意味着引擎无法找到服务任务引用的CallExternalSystemDelegate类。要解决这个错误,需要将该类放在应用的classpath下(并需要重启应用)。按照上一章节的介绍创建该类,并将其打包为JAR,放在Tomcat的webapps目录下的flowable-rest目录下的WEB-INF/lib目录下。
3. 配置
3.1. 创建ProcessEngine
Flowable流程引擎通过名为flowable.cfg.xml的XML文件进行配置。请注意这种方式与使用Spring创建流程引擎不一样。
获取ProcessEngine,最简单的方式是使用org.flowable.engine.ProcessEngines类:
ProcessEngine processEngine = ProcessEngines.getDefaultProcessEngine()这样会从classpath寻找flowable.cfg.xml,并用这个文件中的配置构造引擎。下面的代码展示了一个配置的例子。后续章节会对配置参数进行详细介绍。
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd">
<bean id="processEngineConfiguration" class="org.flowable.engine.impl.cfg.StandaloneProcessEngineConfiguration">
<property name="jdbcUrl" value="jdbc:h2:mem:flowable;DB_CLOSE_DELAY=1000" />
<property name="jdbcDriver" value="org.h2.Driver" />
<property name="jdbcUsername" value="sa" />
<property name="jdbcPassword" value="" />
<property name="databaseSchemaUpdate" value="true" />
<property name="asyncExecutorActivate" value="false" />
<property name="mailServerHost" value="mail.my-corp.com" />
<property name="mailServerPort" value="5025" />
</bean>
</beans>请注意这个配置XML文件实际上是一个Spring配置文件。但这并不意味着Flowable只能用于Spring环境!我们只是利用Spring内部的解析与依赖注入功能来简化引擎的构建过程。
也可以通过编程方式使用配置文件,来构造ProcessEngineConfiguration对象。也可以使用不同的bean id(例如第3行)。
ProcessEngineConfiguration.
createProcessEngineConfigurationFromResourceDefault();
createProcessEngineConfigurationFromResource(String resource);
createProcessEngineConfigurationFromResource(String resource, String beanName);
createProcessEngineConfigurationFromInputStream(InputStream inputStream);
createProcessEngineConfigurationFromInputStream(InputStream inputStream, String beanName);也可以不使用配置文件,使用默认配置(参考不同的支持类获得更多信息)。
ProcessEngineConfiguration.createStandaloneProcessEngineConfiguration();
ProcessEngineConfiguration.createStandaloneInMemProcessEngineConfiguration();所有的ProcessEngineConfiguration.createXXX()方法都返回ProcessEngineConfiguration,并可以继续按需调整。调用buildProcessEngine()后,生成一个ProcessEngine:
ProcessEngine processEngine = ProcessEngineConfiguration.createStandaloneInMemProcessEngineConfiguration()
.setDatabaseSchemaUpdate(ProcessEngineConfiguration.DB_SCHEMA_UPDATE_FALSE)
.setJdbcUrl("jdbc:h2:mem:my-own-db;DB_CLOSE_DELAY=1000")
.setAsyncExecutorActivate(false)
.buildProcessEngine();3.2. ProcessEngineConfiguration bean
flowable.cfg.xml文件中必须包含一个id为'processEngineConfiguration'的bean。
<bean id="processEngineConfiguration" class="org.flowable.engine.impl.cfg.StandaloneProcessEngineConfiguration">这个bean用于构建ProcessEngine。有多个类可以用于定义processEngineConfiguration。这些类用于不同的环境,并各自设置一些默认值。最佳实践是选择最匹配你环境的类,以便减少配置引擎需要的参数。目前可以使用的类为:
-
org.flowable.engine.impl.cfg.StandaloneProcessEngineConfiguration:流程引擎独立运行。Flowable自行处理事务。在默认情况下,数据库检查只在引擎启动时进行(如果Flowable表结构不存在或表结构版本不对,会抛出异常)。
-
org.flowable.engine.impl.cfg.StandaloneInMemProcessEngineConfiguration:这是一个便于使用单元测试的类。Flowable自行处理事务。默认使用H2内存数据库。数据库会在引擎启动时创建,并在引擎关闭时删除。使用这个类时,很可能不需要更多的配置(除了使用任务执行器或邮件等功能时)。
-
org.flowable.spring.SpringProcessEngineConfiguration:在流程引擎处于Spring环境时使用。查看Spring集成章节了解更多信息。
-
org.flowable.engine.impl.cfg.JtaProcessEngineConfiguration:用于引擎独立运行,并使用JTA事务的情况。
3.3. 配置数据库
有两种方式配置Flowable引擎使用的数据库。第一种方式是定义数据库的JDBC参数:
-
jdbcUrl: 数据库的JDBC URL。
-
jdbcDriver: 对应数据库类型的驱动。
-
jdbcUsername: 用于连接数据库的用户名。
-
jdbcPassword: 用于连接数据库的密码。
通过提供的JDBC参数构造的数据源,使用默认的MyBatis连接池设置。可用下列属性调整这个连接池(来自MyBatis文档):
-
jdbcMaxActiveConnections: 连接池能够容纳的最大活动连接数量。默认值为10.
-
jdbcMaxIdleConnections: 连接池能够容纳的最大空闲连接数量。
-
jdbcMaxCheckoutTime: 连接从连接池“取出”后,被强制返回前的最大时间间隔,单位为毫秒。默认值为20000(20秒)。
-
jdbcMaxWaitTime: 这是一个底层设置,在连接池获取连接的时间异常长时,打印日志并尝试重新获取连接(避免连接池配置错误,导致没有异常提示)。默认值为20000(20秒)。
数据库配置示例:
<property name="jdbcUrl" value="jdbc:h2:mem:flowable;DB_CLOSE_DELAY=1000" />
<property name="jdbcDriver" value="org.h2.Driver" />
<property name="jdbcUsername" value="sa" />
<property name="jdbcPassword" value="" />我们的跑分显示MyBatis连接池在处理大量并发请求时,并不是最经济或最具弹性的。因此,建议使用javax.sql.DataSource的实现,并将其注入到流程引擎配置中(如Hikari、Tomcat JDBC连接池,等等):
<bean id="dataSource" class="org.apache.commons.dbcp.BasicDataSource" >
<property name="driverClassName" value="com.mysql.jdbc.Driver" />
<property name="url" value="jdbc:mysql://localhost:3306/flowable" />
<property name="username" value="flowable" />
<property name="password" value="flowable" />
<property name="defaultAutoCommit" value="false" />
</bean>
<bean id="processEngineConfiguration" class="org.flowable.engine.impl.cfg.StandaloneProcessEngineConfiguration">
<property name="dataSource" ref="dataSource" />
...请注意Flowable发布时不包括用于定义数据源的库。需要自行把库放在classpath中。
无论使用JDBC还是数据源方式配置,都可以使用下列参数:
-
databaseType: 通常不需要专门设置这个参数,因为它可以从数据库连接信息中自动检测得出。只有在自动检测失败时才需要设置。可用值:{h2, mysql, oracle, postgres, mssql, db2}。这个选项会决定创建、删除与查询时使用的脚本。查看“支持的数据库”章节了解我们支持哪些类型的数据库。
-
databaseSchemaUpdate: 用于设置流程引擎启动关闭时使用的数据库表结构控制策略。
-
false(默认): 当引擎启动时,检查数据库表结构的版本是否匹配库文件版本。版本不匹配时抛出异常。 -
true: 构建引擎时,检查并在需要时更新表结构。表结构不存在则会创建。 -
create-drop: 引擎创建时创建表结构,并在引擎关闭时删除表结构。
-
3.4. 配置JNDI数据源
默认情况下,Flowable的数据库配置保存在每个web应用WEB-INF/classes文件夹下的db.properties文件中。有时这样并不合适,因为这需要用户修改Flowable源码中的db.properties文件并重新编译war包,或者在部署后解开war包并修改db.properties文件。
通过使用JNDI(Java Naming and Directory Interface,Java命名和目录接口)获取数据库连接,连接就完全交由Servlet容器管理,并可以在WAR部署之外管理配置。同时也提供了比db.properties中更多的控制连接的参数。
3.4.1. 配置
根据你使用的servlet容器应用不同,配置JNDI数据源的方式也不同。下面的介绍用于Tomcat,对于其他容器应用,请参考对应的文档。
Tomcat的JNDI资源配置在$CATALINA_BASE/conf/[enginename]/[hostname]/[warname].xml (对于Flowable UI通常会是$CATALINA_BASE/conf/Catalina/localhost/flowable-app.xml)。当应用第一次部署时,默认会从Flowable war包中复制context.xml。所以如果存在这个文件则需要替换。例如,如果需要将JNDI资源修改为应用连接MySQL而不是H2,需要如下修改:
<?xml version="1.0" encoding="UTF-8"?>
<Context antiJARLocking="true" path="/flowable-app">
<Resource auth="Container"
name="jdbc/flowableDB"
type="javax.sql.DataSource"
description="JDBC DataSource"
url="jdbc:mysql://localhost:3306/flowable"
driverClassName="com.mysql.jdbc.Driver"
username="sa"
password=""
defaultAutoCommit="false"
initialSize="5"
maxWait="5000"
maxActive="120"
maxIdle="5"/>
</Context>3.4.2. JNDI参数
在Flowable UI的配置文件中使用下列参数配置JNDI数据源:
-
spring.datasource.jndi-name=: 数据源的JNDI名
-
datasource.jndi.resourceRef: 设置是否在J2EE容器中查找。也就是说,如果JNDI名中没有包含"java:comp/env/"前缀,是否需要添加它。默认为"true"。
3.5. 支持的数据库
下面列出Flowable用于引用数据库的类型(区分大小写!)。
| Flowable数据库类型 | 示例JDBC URL | 备注 |
|---|---|---|
h2 |
jdbc:h2:tcp://localhost/flowable |
默认配置的数据库 |
mysql |
jdbc:mysql://localhost:3306/flowable?autoReconnect=true |
已使用mysql-connector-java数据库驱动测试 |
oracle |
jdbc:oracle:thin:@localhost:1521:xe |
|
postgres |
jdbc:postgresql://localhost:5432/flowable |
|
db2 |
jdbc:db2://localhost:50000/flowable |
|
mssql |
jdbc:sqlserver://localhost:1433;databaseName=flowable (jdbc.driver=com.microsoft.sqlserver.jdbc.SQLServerDriver) OR jdbc:jtds:sqlserver://localhost:1433/flowable (jdbc.driver=net.sourceforge.jtds.jdbc.Driver) |
已使用Microsoft JDBC Driver 4.0 (sqljdbc4.jar)与JTDS Driver测试 |
3.6. 创建数据库表
在你的数据库中创建数据库表,最简单的方法是:
-
在classpath中添加flowable-engine JAR
-
添加合适的数据库驱动
-
在classpath中添加Flowable配置文件(flowable.cfg.xml),指向你的数据库(参考数据库配置)
-
执行DbSchemaCreate类的main方法
然而,通常只有数据库管理员可以在数据库中执行DDL语句,在生产环境中这也是最明智的选择。DDL的SQL脚本可以在Flowable下载页面或Flowable发布文件夹中找到,位于database子文件夹。引擎JAR (flowable-engine-x.jar)的org/flowable/db/create包中也有一份(drop文件夹存放删除脚本)。SQL文件的格式为:
flowable.{db}.{create|drop}.{type}.sql
其中db为支持的数据库,而type为:
-
engine: 引擎执行所需的表,必需。
-
history: 存储历史与审计信息的表。当历史级别设置为none时不需要。请注意不使用这些表会导致部分使用历史数据的功能失效(如任务备注)。
MySQL用户请注意:低于5.6.4的MySQL版本不支持timestamps或包含毫秒精度的日期。更糟的是部分版本会在创建类似的列时抛出异常,而另一些版本则不会。当使用自动创建/升级时,引擎在执行时会自动修改DDL语句。当使用DDL文件方式建表时,可以使用通用版本,或使用文件名包含mysql55的特殊版本(用于5.6.4以下的任何版本)。特殊版本的文件中不会使用毫秒精度的列类型。
具体地说,对于MySQL的版本:
-
<5.6: 不支持毫秒精度。可以使用DDL文件(使用包含mysql55的文件)。可以使用自动创建/升级。
-
5.6.0 - 5.6.3: 不支持毫秒精度。不可以使用自动创建/升级。建议升级为较新版本的数据库。如果确实需要,可以使用包含mysql55的DDL文件。
-
5.6.4+: 支持毫秒精度。可以使用DDL文件(默认的包含mysql的文件)。可以使用自动创建/升级。
请注意如果在Flowable表已经创建/升级后,再升级MySQL数据库,则需要手工修改列类型!
3.7. 数据库表名说明
Flowable的所有数据库表都以ACT_开头。第二部分是说明表用途的两字符标示符。服务API的命名也大略符合这个规则。
-
ACT_RE_*: 'RE’代表
repository。带有这个前缀的表包含“静态”信息,例如流程定义与流程资源(图片、规则等)。 -
ACT_RU_*: 'RU’代表
runtime。这些表存储运行时信息,例如流程实例(process instance)、用户任务(user task)、变量(variable)、作业(job)等。Flowable只在流程实例运行中保存运行时数据,并在流程实例结束时删除记录。这样保证运行时表小和快。 -
ACT_HI_*: 'HI’代表
history。这些表存储历史数据,例如已完成的流程实例、变量、任务等。 -
ACT_GE_*: 通用数据。在多处使用。
3.8. 数据库升级
在升级前,请确保你已经(使用数据库的备份功能)备份了数据库。
默认情况下,每次流程引擎创建时会进行版本检查,通常是在你的应用或者Flowable web应用启动的时候。如果Flowable发现库版本与Flowable数据库表版本不同,会抛出异常。
要进行升级,首先需要将下列配置参数放入你的flowable.cfg.xml配置文件:
<beans >
<bean id="processEngineConfiguration"
class="org.flowable.engine.impl.cfg.StandaloneProcessEngineConfiguration">
<!-- ... -->
<property name="databaseSchemaUpdate" value="true" />
<!-- ... -->
</bean>
</beans>同时,在classpath中加上合适的数据库驱动。升级应用中的Flowable库,或者启动一个新版本的Flowable,并将它指向包含旧版本数据的数据库。将databaseSchemaUpdate设置为true。当Flowable发现库与数据库表结构不一致时,会自动将数据库表结构升级至新版本。
也可以直接运行升级DDL语句。也可以从Flowable下载页面获取升级数据库脚本并运行。
3.9. 作业执行器(从6.0.1版本起)
在Flowable V6中唯一可用的作业执行器,是Flowable V5中的异步执行器(async executor)。因为它为Flowable引擎提供了性能更好,对数据库也更友好的执行异步作业的方式。 Flowable V5中的作业执行器(job executor)在V6中不再可用。可以在用户手册的高级章节找到更多信息。
此外,如果在Java EE 7下运行,容器还可以使用符合JSR-236标准的ManagedAsyncJobExecutor来管理线程。要启用这个功能,需要在配置中如下加入线程工厂:
<bean id="threadFactory" class="org.springframework.jndi.JndiObjectFactoryBean">
<property name="jndiName" value="java:jboss/ee/concurrency/factory/default" />
</bean>
<bean id="customJobExecutor" class="org.flowable.engine.impl.jobexecutor.ManagedAsyncJobExecutor">
<!-- ... -->
<property name="threadFactory" ref="threadFactory" />
<!-- ... -->
</bean>如果没有设置线程工厂,ManagedAsyncJobExecutor实现会退化为默认实现(AsyncJobExecutor)。
3.10. 启用作业执行器
AsyncExecutor是管理线程池的组件,用于触发定时器与其他异步任务。也可以使用其他实现(如使用消息队列,参见用户手册的高级章节)。
默认情况下,AsyncExecutor并未启用,也不会启动。如下配置使异步执行器与Flowable引擎一同启动:
<property name="asyncExecutorActivate" value="true" />asyncExecutorActivate这个参数使Flowable引擎在启动同时启动异步执行器。
3.11. 配置邮件服务器
配置邮件服务器是可选的。Flowable支持在业务流程中发送电子邮件。发送电子邮件需要配置有效的SMTP邮件服务器。查看电子邮件任务了解配置选项。
3.13. 配置异步历史
[实验性] 从Flowable 6.1.0起,添加了异步历史功能。当启用异步历史时,历史数据将由历史任务执行器负责持久化,而不是与运行时执行持久化同步保存。 查看配置异步历史章节了解更多细节。
<property name="asyncHistoryEnabled" value="true" />3.14. 配置在表达式与脚本中可用的bean
默认情况下,所有通过flowable.cfg.xml或你自己的Spring配置文件声明的bean,都可以在表达式与脚本中使用。如果你希望限制配置文件中bean的可见性,可以使用流程引擎配置的beans参数。ProcessEngineConfiguration中的beans参数是一个map。当你配置这个参数时,只有在这个map中声明的bean可以在表达式与脚本中使用。bean会使用你在map中指定的名字暴露。
3.15. 配置部署缓存
鉴于流程定义信息不会改变,为了避免每次使用流程定义时都读取数据库,所有的流程定义都会(在解析后)被缓存。默认情况下,这个缓存没有限制。要限制流程定义缓存,加上如下的参数
<property name="processDefinitionCacheLimit" value="10" />设置这个参数,会将默认的hashmap缓存替换为LRU缓存,以进行限制。当然,参数的“最佳”取值,取决于总的流程定义数量,以及实际使用的流程定义数量。
也可以注入自己的缓存实现。必须是一个实现了org.flowable.engine.impl.persistence.deploy.DeploymentCache接口的bean:
<property name="processDefinitionCache">
<bean class="org.flowable.MyCache" />
</property>类似的,可以使用名为knowledgeBaseCacheLimit与knowledgeBaseCache的参数配置规则缓存(rules cache)。只有在流程中使用规则任务(rules task)时才需要设置。
3.16. 日志
所有的日志(Flowable、Spring、MyBatis等)都通过SLF4J路由,并允许你自行选择日志实现。
默认情况下,Flowable引擎依赖中不提供SFL4J绑定JAR。你需要自行将其加入你的项目,以便使用所选的日志框架。如果没有加入实现JAR,SLF4J会使用NOP-logger。这时除了一条警告外,不会记录任何日志。可以从http://www.slf4j.org/codes.html#StaticLoggerBinder了解关于绑定的更多信息。
可以像这样(这里使用Log4j)使用Maven添加依赖,请注意你还需要加上版本:
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</dependency>Flowable-UI与Flowable-rest web应用配置为使用Log4j绑定。运行所有flowable-*模块的测试时也会使用Log4j。
重要提示:当使用classpath中带有commons-logging的容器时:为了将spring的日志路由至SLF4j,需要使用桥接(参考http://www.slf4j.org/legacy.html#jclOverSLF4J)。如果你的容器提供了commons-logging实现,请按照http://www.slf4j.org/codes.html#release页面的指示调整。
使用Maven的示例(省略了版本):
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>jcl-over-slf4j</artifactId>
</dependency>3.17. 映射诊断上下文
Flowable支持SLF4J的映射诊断上下文特性。下列基本信息会与需要日志记录的信息一起,传递给底层日志实现:
-
processDefinition Id 作为 mdcProcessDefinitionID
-
processInstance Id 作为 mdcProcessInstanceID
-
execution Id 作为 mdcExecutionId
默认情况下这些信息都不会被日志记录,但可以通过配置logger,按照你想要的格式,与其他日志信息一起显示。例如在Log4j中进行如下简单的格式定义,就可以让logger显示上述信息:
log4j.appender.consoleAppender.layout.ConversionPattern=ProcessDefinitionId=%X{mdcProcessDefinitionID}
executionId=%X{mdcExecutionId} mdcProcessInstanceID=%X{mdcProcessInstanceID} mdcBusinessKey=%X{mdcBusinessKey} %m%n如果需要使用日志中包含的信息进行实时监测(如使用日志分析器),就会很有帮助。
3.18. 事件处理器
Flowable引擎中的事件机制可以让你在引擎中发生多种事件的时候得到通知。查看所有支持的事件类型了解可用的事件。
可以只为特定种类的事件注册监听器,而不是在任何类型的事件发送时都被通知。可以通过配置添加引擎全局的事件监听器,在运行时通过API添加引擎全局的事件监听器,也可以在BPMN XML文件为个别流程定义添加事件监听器。
所有被分发的事件都是org.flowable.engine.common.api.delegate.event.FlowableEvent的子类。事件(在可用时)提供type, executionId, processInstanceId与processDefinitionId。部分事件含有关于发生事件的上下文信息。关于事件包含的附加信息,请参阅所有支持的事件类型。
3.18.1. 实现事件监听器
对事件监听器的唯一要求,是要实现org.flowable.engine.delegate.event.FlowableEventListener接口。下面是一个监听器实现的例子,它将接收的所有事件打印至标准输出,并对作业执行相关的事件特别处理:
public class MyEventListener implements FlowableEventListener {
@Override
public void onEvent(FlowableEvent event) {
switch (event.getType()) {
case JOB_EXECUTION_SUCCESS:
System.out.println("A job well done!");
break;
case JOB_EXECUTION_FAILURE:
System.out.println("A job has failed...");
break;
default:
System.out.println("Event received: " + event.getType());
}
}
@Override
public boolean isFailOnException() {
// onEvent方法中的逻辑并不重要,可以忽略日志失败异常……
return false;
}
}isFailOnException()方法决定了当事件分发后,onEvent(..)方法抛出异常时的行为。若返回false,忽略异常;若返回true,异常不会被忽略而会被上抛,使当前执行的命令失败。如果事件是API调用(或其他事务操作,例如作业执行)的一部分,事务将被回滚。如果事件监听器中并不是重要的业务操作,建议返回false。
Flowable提供了少量基础实现,以简化常用的事件监听器使用场景。它们可以被用作监听器的示例或基类:
-
org.flowable.engine.delegate.event.BaseEntityEventListener: 事件监听器基类,可用来监听实体(entity)相关事件,特定或所有实体的事件都可以。它隐藏了类型检测,提供了4个需要覆盖的方法:
onCreate(..),onUpdate(..)与onDelete(..)在实体创建、更新及删除时调用;对所有其他实体相关事件,onEntityEvent(..)会被调用。
3.18.2. 配置与使用
在流程引擎中配置的事件监听器会在流程引擎启动时生效,引擎重启后也会保持有效。
eventListeners参数为org.flowable.engine.delegate.event.FlowableEventListener类实例的列表(list)。与其他地方一样,你可以声明内联bean定义,也可以用ref指向已有的bean。下面的代码片段在配置中添加了一个事件监听器,无论任何类型的事件分发时,都会得到通知:
<bean id="processEngineConfiguration"
class="org.flowable.engine.impl.cfg.StandaloneProcessEngineConfiguration">
...
<property name="eventListeners">
<list>
<bean class="org.flowable.engine.example.MyEventListener" />
</list>
</property>
</bean>要在特定类型的事件分发时得到通知,使用typedEventListeners参数,值为map。map的key为逗号分隔的事件名字列表(或者一个事件的名字),取值为org.flowable.engine.delegate.event.FlowableEventListener实例的列表。下面的代码片段在配置中添加了一个事件监听器,它会在作业执行成功或失败时得到通知:
<bean id="processEngineConfiguration"
class="org.flowable.engine.impl.cfg.StandaloneProcessEngineConfiguration">
...
<property name="typedEventListeners">
<map>
<entry key="JOB_EXECUTION_SUCCESS,JOB_EXECUTION_FAILURE" >
<list>
<bean class="org.flowable.engine.example.MyJobEventListener" />
</list>
</entry>
</map>
</property>
</bean>事件分发的顺序由加入监听器的顺序决定。首先,所有普通(eventListeners参数定义的)事件监听器按照在list里的顺序被调用;之后,如果分发的是某类型的事件,则(typedEventListeners 参数定义的)该类型监听器被调用。
3.18.3. 在运行时添加监听器
可以使用API(RuntimeService)为引擎添加或删除事件监听器:
/**
* 新增一个监听器,会在所有事件发生时被通知。
* @param listenerToAdd 要新增的监听器
*/
void addEventListener(FlowableEventListener listenerToAdd);
/**
* 新增一个监听器,在给定类型的事件发生时被通知。
* @param listenerToAdd 要新增的监听器
* @param types 监听器需要监听的事件类型
*/
void addEventListener(FlowableEventListener listenerToAdd, FlowableEventType... types);
/**
* 从分发器中移除指定监听器。该监听器将不再被通知,无论该监听器注册为监听何种类型。
* @param listenerToRemove 要移除的监听器
*/
void removeEventListener(FlowableEventListener listenerToRemove);请注意,运行时新增的监听器在引擎重启后不会保持。
3.18.4. 为流程定义增加监听器
可以为某一流程定义增加监听器。只有与该流程定义相关,或使用该流程定义启动的流程实例相关的事件,才会调用这个监听器。监听器实现可以用完全限定类名(fully qualified classname)定义;也可以定义为表达式,该表达式需要能被解析为实现监听器接口的bean;也可以配置为抛出消息(message)/信号(signal)/错误(error)的BPMN事件。
执行用户定义逻辑的监听器
下面的代码片段为流程定义增加了2个监听器。第一个监听器接收任何类型的事件,使用完全限定类名定义。第二个监听器只在作业成功执行或失败时被通知,使用流程引擎配置中beans参数定义的bean作为监听器。
<process id="testEventListeners">
<extensionElements>
<flowable:eventListener class="org.flowable.engine.test.MyEventListener" />
<flowable:eventListener delegateExpression="${testEventListener}" events="JOB_EXECUTION_SUCCESS,JOB_EXECUTION_FAILURE" />
</extensionElements>
...
</process>实体相关的事件也可以在流程定义中增加监听器,只有在特定实体类型的事件发生时得到通知。下面的代码片段展示了如何设置。可以响应实体的所有事件(第一个例子),或只响应实体的特定类型事件(第二个例子)。
<process id="testEventListeners">
<extensionElements>
<flowable:eventListener class="org.flowable.engine.test.MyEventListener" entityType="task" />
<flowable:eventListener delegateExpression="${testEventListener}" events="ENTITY_CREATED" entityType="task" />
</extensionElements>
...
</process>entityType可用的值有:attachment(附件), comment(备注), execution(执行), identity-link(身份关联), job(作业), process-instance(流程实例), process-definition(流程定义), task(任务)。
抛出BPMN事件的监听器
处理分发的事件的另一个方法,是抛出BPMN事件。请牢记在心,只有特定种类的Flowable事件类型,抛出BPMN事件才合理。例如,在流程实例被删除时抛出BPMN事件,会导致错误。下面的代码片段展示了如何在流程实例中抛出信号,向外部流程(全局)抛出信号,在流程实例中抛出消息事件,以及在流程实例中抛出错误事件。这里不使用class或delegateExpression,而要使用throwEvent属性,以及一个附加属性,用于指定需要抛出的事件类型。
<process id="testEventListeners">
<extensionElements>
<flowable:eventListener throwEvent="signal" signalName="My signal" events="TASK_ASSIGNED" />
</extensionElements>
</process><process id="testEventListeners">
<extensionElements>
<flowable:eventListener throwEvent="globalSignal" signalName="My signal" events="TASK_ASSIGNED" />
</extensionElements>
</process><process id="testEventListeners">
<extensionElements>
<flowable:eventListener throwEvent="message" messageName="My message" events="TASK_ASSIGNED" />
</extensionElements>
</process><process id="testEventListeners">
<extensionElements>
<flowable:eventListener throwEvent="error" errorCode="123" events="TASK_ASSIGNED" />
</extensionElements>
</process>如果需要使用额外的逻辑判断是否需要抛出BPMN事件,可以扩展Flowable提供的监听器类。通过在你的子类中覆盖isValidEvent(FlowableEvent event),可以阻止抛出BPMN事件。相关的类为org.flowable.engine.test.api.event.SignalThrowingEventListenerTest, org.flowable.engine.impl.bpmn.helper.MessageThrowingEventListener与org.flowable.engine.impl.bpmn.helper.ErrorThrowingEventListener.
关于流程定义监听器的说明
-
事件监听器只能作为
extensionElements的子元素,声明在process元素上。不能在个别节点(activity)上定义(事件)监听器。 -
delegateExpression中的表达式,与其他表达式(例如在网关中的)不一样,不可以访问执行上下文。只能够引用在流程引擎配置中beans参数定义的bean;或是在使用spring(且没有定义beans参数)时,引用任何实现了监听器接口的spring bean。 -
使用监听器的
class属性时,只会创建唯一一个该类的实例。请确保监听器实现不依赖于成员变量,或确保多线程/上下文的使用安全。 -
如果
events属性使用了不合法的事件类型,或者使用了不合法的throwEvent值,会在流程定义部署时抛出异常(导致部署失败)。如果class或delegateExecution指定了不合法的值(不存在的类,不存在的bean引用,或者代理类没有实现监听器接口),在流程启动(或该流程定义的第一个有效事件分发给这个监听器)时,会抛出异常。请确保引用的类在classpath中,并且保证表达式能够解析为有效的实例。
3.18.5. 通过API分发事件
可以通过API提供事件分发机制,向任何在引擎中注册的监听器分发自定义事件。建议(但不强制)只分发CUSTOM类型的FlowableEvents。使用RuntimeService分发事件:
/**
* 将给定事件分发给所有注册监听器。
* @param event 要分发的事件。
*
* @throws FlowableException 当分发事件发生异常,或者{@link FlowableEventDispatcher}被禁用。
* @throws FlowableIllegalArgumentException 当给定事件不可分发
*/
void dispatchEvent(FlowableEvent event);3.18.6. 支持的事件类型
下表列出引擎中的所有事件类型。每种类型对应org.flowable.engine.common.api.delegate.event.FlowableEventType中的一个枚举值。
| 事件名称 | 说明 | 事件类 |
|---|---|---|
ENGINE_CREATED |
本监听器所属的流程引擎已经创建,并可以响应API调用。 |
|
ENGINE_CLOSED |
本监听器所属的流程引擎已经关闭,不能再对该引擎进行API调用。 |
|
ENTITY_CREATED |
新的实体已经创建。该实体包含在本事件里。 |
|
ENTITY_INITIALIZED |
新的实体已经创建并完全初始化。如果任何子实体作为该实体的一部分被创建,本事件会在子实体创建/初始化后触发,与 |
|
ENTITY_UPDATED |
实体已经更新。该实体包含在本事件里。 |
|
ENTITY_DELETED |
实体已经删除。该实体包含在本事件里。 |
|
ENTITY_SUSPENDED |
实体已经暂停。该实体包含在本事件里。ProcessDefinitions(流程定义), ProcessInstances(流程实例)与Tasks(任务)会分发本事件。 |
|
ENTITY_ACTIVATED |
实体已经激活。该实体包含在本事件里。ProcessDefinitions, ProcessInstances与Tasks会分发本事件。 |
|
JOB_EXECUTION_SUCCESS |
作业已经成功执行。该作业包含在本事件里。 |
|
JOB_EXECUTION_FAILURE |
作业执行失败。该作业与异常包含在本事件里。 |
|
JOB_RETRIES_DECREMENTED |
作业重试次数已经由于执行失败而减少。该作业包含在本事件里。 |
|
TIMER_SCHEDULED |
已创建一个定时作业,并预计在未来时间点执行。 |
|
TIMER_FIRED |
定时器已经触发。 |
|
JOB_CANCELED |
作业已经取消。该作业包含在本事件里。作业会由于API调用取消,任务完成导致关联的边界定时器取消,也会由于新流程定义的部署而取消。 |
|
ACTIVITY_STARTED |
节点开始执行 |
|
ACTIVITY_COMPLETED |
节点成功完成 |
|
ACTIVITY_CANCELLED |
节点将要取消。节点的取消有三个原因(MessageEventSubscriptionEntity, SignalEventSubscriptionEntity, TimerEntity)。 |
|
ACTIVITY_SIGNALED |
节点收到了一个信号 |
|
ACTIVITY_MESSAGE_RECEIVED |
节点收到了一个消息。事件在节点接收消息前分发。节点接收消息后,会为该节点分发 |
|
ACTIVITY_MESSAGE_WAITING |
一个节点已经创建了一个消息事件订阅,并正在等待接收消息。 |
|
ACTIVITY_MESSAGE_CANCELLED |
一个节点已经取消了一个消息事件订阅,因此接收这个消息不会再触发该节点。 |
|
ACTIVITY_ERROR_RECEIVED |
节点收到了错误事件。在节点实际处理错误前分发。该事件的 |
|
UNCAUGHT_BPMN_ERROR |
抛出了未捕获的BPMN错误。流程没有该错误的处理器。该事件的 |
|
ACTIVITY_COMPENSATE |
节点将要被补偿(compensate)。该事件包含将要执行补偿的节点id。 |
|
MULTI_INSTANCE_ACTIVITY_STARTED |
多实例节点开始执行 |
|
MULTI_INSTANCE_ACTIVITY_COMPLETED |
多实例节点成功完成 |
|
MULTI_INSTANCE_ACTIVITY_CANCELLED |
多实例节点将要取消。多实例节点的取消有三个原因(MessageEventSubscriptionEntity, SignalEventSubscriptionEntity, TimerEntity)。 |
|
VARIABLE_CREATED |
流程变量已经创建。本事件包含变量名、取值,及关联的执行和任务(若有)。 |
|
VARIABLE_UPDATED |
变量已经更新。本事件包含变量名、取值,及关联的执行和任务(若有)。 |
|
VARIABLE_DELETED |
变量已经删除。本事件包含变量名、最后取值,及关联的执行和任务(若有)。 |
|
TASK_ASSIGNED |
任务已经分派给了用户。该任务包含在本事件里。 |
|
TASK_CREATED |
任务已经创建。本事件在 |
|
TASK_COMPLETED |
任务已经完成。本事件在 |
|
PROCESS_CREATED |
流程实例已经创建。已经设置所有的基础参数,但还未设置变量。 |
|
PROCESS_STARTED |
流程实例已经启动。在启动之前创建的流程时分发。PROCESS_STARTED事件在相关的ENTITY_INITIALIZED事件,以及设置变量之后分发。 |
|
PROCESS_COMPLETED |
流程实例已经完成。在最后一个节点的 |
|
PROCESS_COMPLETED_WITH_TERMINATE_END_EVENT |
流程已经到达终止结束事件(terminate end event)并结束。 |
|
PROCESS_CANCELLED |
流程已经被取消。在流程实例从运行时中删除前分发。流程实例由API调用 |
|
MEMBERSHIP_CREATED |
用户已经加入组。本事件包含了相关的用户和组的id。 |
|
MEMBERSHIP_DELETED |
用户已经从组中移出。本事件包含了相关的用户和组的id。 |
|
MEMBERSHIPS_DELETED |
组的所有用户将被移出。本事件在用户移出前抛出,因此关联关系仍然可以访问。因为性能原因,不会再为每个被移出的用户抛出 |
|
引擎中所有的 ENTITY_\* 事件都与实体关联。下表列出每个实体分发的实体事件:
-
ENTITY_CREATED, ENTITY_INITIALIZED, ENTITY_DELETED: 附件(Attachment),备注(Comment),部署(Deployment),执行(Execution),组(Group),身份关联(IdentityLink),作业(Job),模型(Model),流程定义(ProcessDefinition),流程实例(ProcessInstance),任务(Task),用户(User)。 -
ENTITY_UPDATED: 附件,部署,执行,组,身份关联,作业,模型,流程定义,流程实例,任务,用户。 -
ENTITY_SUSPENDED, ENTITY_ACTIVATED: 流程定义,流程实例/执行,任务。
3.18.7. 附加信息
监听器只会响应其所在引擎分发的事件。因此如果在同一个数据库上运行不同的引擎,则只有该监听器注册的引擎生成的事件,才会分发给该监听器。其他引擎生成的事件不会分发给这个监听器,而不论这些引擎是否运行在同一个JVM下。
某些事件类型(与实体相关)暴露了目标实体。按照事件类型的不同,有些实体不能被更新(如实体删除事件中的实体)。如果可能的话,请使用事件暴露的EngineServices来安全地操作引擎。即使这样,更新、操作事件中暴露的实体仍然需要小心。
历史不会分发实体事件,因为它们都有对应的运行时实体分发事件。
4. Flowable API
4.1. 流程引擎API与服务
引擎API是与Flowable交互的最常用手段。总入口点是ProcessEngine。像配置章节中介绍的一样,ProcessEngine可以使用多种方式创建。使用ProcessEngine,可以获得各种提供工作流/BPM方法的服务。ProcessEngine与服务对象都是线程安全的,因此可以在服务器中保存并共用同一个引用。
ProcessEngine processEngine = ProcessEngines.getDefaultProcessEngine();
RuntimeService runtimeService = processEngine.getRuntimeService();
RepositoryService repositoryService = processEngine.getRepositoryService();
TaskService taskService = processEngine.getTaskService();
ManagementService managementService = processEngine.getManagementService();
IdentityService identityService = processEngine.getIdentityService();
HistoryService historyService = processEngine.getHistoryService();
FormService formService = processEngine.getFormService();
DynamicBpmnService dynamicBpmnService = processEngine.getDynamicBpmnService();在ProcessEngines.getDefaultProcessEngine()第一次被调用时,将初始化并构建流程引擎,之后的重复调用都会返回同一个流程引擎。可以通过ProcessEngines.init()创建流程引擎,并由ProcessEngines.destroy()关闭流程引擎。
ProcessEngines会扫描flowable.cfg.xml与flowable-context.xml文件。对于flowable.cfg.xml文件,流程引擎会以标准Flowable方式构建引擎:ProcessEngineConfiguration.createProcessEngineConfigurationFromInputStream(inputStream).buildProcessEngine()。对于flowable-context.xml文件,流程引擎会以Spring的方式构建:首先构建Spring应用上下文,然后从该上下文中获取流程引擎。
所有的服务都是无状态的。这意味着你可以很容易的在集群环境的多个节点上运行Flowable,使用同一个数据库,而不用担心上一次调用实际在哪台机器上执行。不论在哪个节点执行,对任何服务的任何调用都是幂等(idempotent)的。
RepositoryService很可能是使用Flowable引擎要用的第一个服务。这个服务提供了管理与控制部署(deployments)与流程定义(process definitions)的操作。在这里简单说明一下,流程定义是BPMN 2.0流程对应的Java对象,体现流程中每一步的结构与行为。部署是Flowable引擎中的包装单元,一个部署中可以包含多个BPMN 2.0 XML文件及其他资源。开发者可以决定在一个部署中包含的内容,可以是单个流程的BPMN 2.0 XML文件,也可以包含多个流程及其相关资源(如’hr-processes’部署可以包含所有与人力资源流程相关的的东西)。RepositoryService可用于部署这样的包。部署意味着将它上传至引擎,引擎将在储存至数据库之前检查与分析所有的流程。在部署操作后,可以在系统中使用这个部署包,部署包中的所有流程都可以启动。
此外,这个服务还可以:
-
查询引擎现有的部署与流程定义。
-
暂停或激活部署中的某些流程,或整个部署。暂停意味着不能再对它进行操作,激活刚好相反,重新使它可以操作。
-
获取各种资源,比如部署中保存的文件,或者引擎自动生成的流程图。
-
获取POJO版本的流程定义。它可以用Java而不是XML的方式查看流程。
与提供静态信息(也就是不会改变,至少不会经常改变的信息)的RepositoryService相反,RuntimeService用于启动流程定义的新流程实例。前面介绍过,流程定义中定义了流程中不同步骤的结构与行为。流程实例则是流程定义的实际执行过程。同一时刻,一个流程定义通常有多个运行中的实例。RuntimeService也用于读取与存储流程变量。流程变量是流程实例中的数据,可以在流程的许多地方使用(例如排他网关经常使用流程变量判断流程下一步要走的路径)。RuntimeService还可以用于查询流程实例与执行(Execution)。执行也就是BPMN 2.0中 'token' 的概念。通常执行是指向流程实例当前位置的指针。最后,还可以在流程实例等待外部触发时使用RuntimeService,使流程可以继续运行。流程有许多等待状态(wait states),RuntimeService服务提供了许多操作用于“通知”流程实例:已经接收到外部触发,流程实例可以继续运行。
对于像Flowable这样的BPM引擎来说,核心是需要人类用户操作的任务。所有任务相关的东西都组织在TaskService中,例如:
-
查询分派给用户或组的任务
-
创建独立运行(standalone)任务。这是一种没有关联到流程实例的任务。
-
决定任务的执行用户(assignee),或者将用户通过某种方式与任务关联。
-
认领(claim)与完成(complete)任务。认领是指某人决定成为任务的执行用户,也即他将会完成这个任务。完成任务是指“做这个任务要求的工作”,通常是填写某个表单。
IdentityService很简单。它用于管理(创建,更新,删除,查询……)组与用户。请注意,Flowable实际上在运行时并不做任何用户检查。例如任务可以分派给任何用户,而引擎并不会验证系统中是否存在该用户。这是因为Flowable有时要与LDAP、Active Directory等服务结合使用。
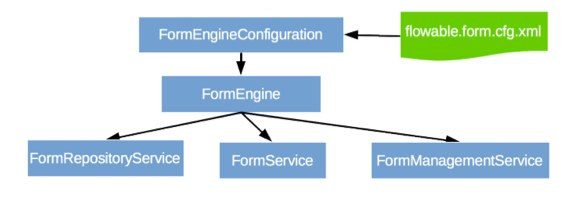
FormService是可选服务。也就是说Flowable没有它也能很好地运行,而不必牺牲任何功能。这个服务引入了开始表单(start form)与任务表单(task form)的概念。 开始表单是在流程实例启动前显示的表单,而任务表单是用户完成任务时显示的表单。Flowable可以在BPMN 2.0流程定义中定义这些表单。表单服务通过简单的方式暴露这些数据。再次重申,表单不一定要嵌入流程定义,因此这个服务是可选的。
HistoryService暴露Flowable引擎收集的所有历史数据。当执行流程时,引擎会保存许多数据(可配置),例如流程实例启动时间、谁在执行哪个任务、完成任务花费的事件、每个流程实例的执行路径,等等。这个服务主要提供查询这些数据的能力。
ManagementService通常在用Flowable编写用户应用时不需要使用。它可以读取数据库表与表原始数据的信息,也提供了对作业(job)的查询与管理操作。Flowable中很多地方都使用作业,例如定时器(timer),异步操作(asynchronous continuation),延时暂停/激活(delayed suspension/activation)等等。后续会详细介绍这些内容。
DynamicBpmnService可用于修改流程定义中的部分内容,而不需要重新部署它。例如可以修改流程定义中一个用户任务的办理人设置,或者修改一个服务任务中的类名。
参考javadocs了解服务操作与引擎API的更多信息。
4.2. 异常策略
Flowable的异常基类是org.flowable.engine.FlowableException,这是一个非受检异常(unchecked exception)。在任何API操作时都可能会抛出这个异常,javadoc提供了每个方法可能抛出的异常。例如,从TaskService中摘录:
/**
* 当任务成功执行时调用。
* @param taskId 需要完成的任务id,不能为null。
* @throws FlowableObjectNotFoundException 若给定id找不到任务。
*/
void complete(String taskId);在上例中,如果所用的id找不到任务,就会抛出异常。并且,由于javadoc中明确要求taskId不能为null,因此如果传递了null值,会抛出FlowableIllegalArgumentException异常。
尽管我们想避免过大的异常层次结构,但在特定情况下仍然会抛出下述异常子类。所有流程执行与API调用中发生的错误,如果不符合下面列出的异常,会统一抛出FlowableExceptions。
-
FlowableWrongDbException: 当Flowable引擎检测到数据库表结构版本与引擎版本不匹配时抛出。 -
FlowableOptimisticLockingException: 当对同一数据实体的并发访问导致数据存储发生乐观锁异常时抛出。 -
FlowableClassLoadingException: 当需要载入的类(如JavaDelegate, TaskListener, …)无法找到,或载入发生错误时抛出。 -
FlowableObjectNotFoundException: 当请求或要操作的对象不存在时抛出。 -
FlowableIllegalArgumentException: 当调用Flowable API时使用了不合法的参数时抛出。可能是引擎配置中的不合法值,或者是API调用传递的不合法参数,也可能是流程定义中的不合法值。 -
FlowableTaskAlreadyClaimedException: 当对已被认领的任务调用taskService.claim(…)时抛出。
4.3. 查询API
从引擎中查询数据有两种方式:查询API与原生(native)查询。查询API可以使用链式API,通过编程方式进行类型安全的查询。你可以在查询中增加各种条件(所有条件都用做AND逻辑),也可以明确指定排序方式。下面是示例代码:
List<Task> tasks = taskService.createTaskQuery()
.taskAssignee("kermit")
.processVariableValueEquals("orderId", "0815")
.orderByDueDate().asc()
.list();有时需要更复杂的查询,例如使用OR操作符查询,或者使用查询API不能满足查询条件要求。我们为这种需求提供了可以自己写SQL查询的原生查询。返回类型由使用的查询对象决定,数据会映射到正确的对象中(Task、ProcessInstance、Execution,等等)。查询在数据库中进行,因此需要使用数据库中定义的表名与列名。这需要了解内部数据结构,因此建议小心使用原生查询。数据库表名可以通过API读取,这样可以将依赖关系减到最小。
List<Task> tasks = taskService.createNativeTaskQuery()
.sql("SELECT count(*) FROM " + managementService.getTableName(Task.class) +
" T WHERE T.NAME_ = #{taskName}")
.parameter("taskName", "gonzoTask")
.list();
long count = taskService.createNativeTaskQuery()
.sql("SELECT count(*) FROM " + managementService.getTableName(Task.class) + " T1, " +
managementService.getTableName(VariableInstanceEntity.class) + " V1 WHERE V1.TASK_ID_ = T1.ID_")
.count();4.4. 变量
流程实例按步骤执行时,需要使用一些数据。在Flowable中,这些数据称作变量(variable),并会存储在数据库中。变量可以用在表达式中(例如在排他网关中用于选择正确的出口路径),也可以在Java服务任务(service task)中用于调用外部服务(例如为服务调用提供输入或结果存储),等等。
流程实例可以持有变量(称作流程变量 process variables);用户任务以及执行(executions)——流程当前活动节点的指针——也可以持有变量。流程实例可以持有任意数量的变量,每个变量存储为ACT_RU_VARIABLE数据库表的一行。
所有的startProcessInstanceXXX方法都有一个可选参数,用于在流程实例创建及启动时设置变量。例如,在RuntimeService中:
ProcessInstance startProcessInstanceByKey(String processDefinitionKey, Map<String, Object> variables);也可以在流程执行中加入变量。例如,(RuntimeService):
void setVariable(String executionId, String variableName, Object value);
void setVariableLocal(String executionId, String variableName, Object value);
void setVariables(String executionId, Map<String, ? extends Object> variables);
void setVariablesLocal(String executionId, Map<String, ? extends Object> variables);请注意可以为给定执行(请记住,流程实例由一颗执行的树(tree of executions)组成)设置局部(local)变量。局部变量将只在该执行中可见,对执行树的上层则不可见。这可以用于 数据不应该暴露给流程实例的其他执行,或者变量在流程实例的不同路径中有不同的值(例如使用并行路径时)的情况。
可以用下列方法读取变量。请注意TaskService中有类似的方法。这意味着任务与执行一样,可以持有局部变量,其生存期为任务持续的时间。
Map<String, Object> getVariables(String executionId);
Map<String, Object> getVariablesLocal(String executionId);
Map<String, Object> getVariables(String executionId, Collection<String> variableNames);
Map<String, Object> getVariablesLocal(String executionId, Collection<String> variableNames);
Object getVariable(String executionId, String variableName);
<T> T getVariable(String executionId, String variableName, Class<T> variableClass);变量通常用于Java代理(Java delegates)、表达式(expressions)、执行(execution)、任务监听器(tasklisteners)、脚本(scripts)等等。在这些结构中,提供了当前的execution或task对象,可用于变量的设置、读取。简单示例如下:
execution.getVariables();
execution.getVariables(Collection<String> variableNames);
execution.getVariable(String variableName);
execution.setVariables(Map<String, object> variables);
execution.setVariable(String variableName, Object value);请注意也可以使用上例中方法的局部变量版本。
由于历史(与向后兼容)原因,当调用上述任何方法时,引擎会从数据库中取出所有变量。也就是说,如果你有10个变量,使用getVariable("myVariable")获取其中的一个,实际上其他9个变量也会从数据库取出并缓存。这并不坏,因为后续的调用可以不必再读取数据库。比如,如果流程定义包含三个连续的服务任务(因此它们在同一个数据库事务里),在第一个服务任务里通过一次调用获取全部变量,也许比在每个服务任务里分别获取需要的变量要好。请注意对读取与设置变量都是这样。
当然,如果使用大量变量,或者你希望精细控制数据库查询与流量,上述的做法就不合适了。我们引入了可以更精细控制的方法。这个方法有一个可选的参数,告诉引擎是否需要读取并缓存所有变量:
Map<String, Object> getVariables(Collection<String> variableNames, boolean fetchAllVariables);
Object getVariable(String variableName, boolean fetchAllVariables);
void setVariable(String variableName, Object value, boolean fetchAllVariables);当fetchAllVariables参数为true时,行为与上面描述的完全一样:读取或设置一个变量时,所有的变量都将被读取并缓存。
而当参数值为false时,会使用明确的查询,其他变量不会被读取或缓存。只有指定的变量的值会被缓存并用于后续使用。
4.5. 瞬时变量
瞬时变量(Transient variable)类似普通变量,只是不会被持久化。通常来说,瞬时变量用于高级使用场景。如果不明确,还是使用普通流程变量为好。
瞬时变量具有下列特性:
-
瞬时变量完全不存储历史。
-
与普通变量类似,设置瞬时变量时会存入最上层父中。这意味着在一个执行中设置一个变量时,瞬时变量实际上会存储在流程实例执行中。与普通变量类似,可以使用局部(local)的对应方法,将变量设置为某个执行或任务的局部变量。
-
瞬时变量只能在下一个“等待状态”之前访问。之后该变量即消失。等待状态意味着流程实例会持久化至数据存储中。请注意在这个定义中,异步活动也是“等待状态”!
-
只能使用setTransientVariable(name, value)设置瞬时变量,但是调用getVariable(name)也会返回瞬时变量(也有getTransientVariable(name)方法,它只会返回瞬时变量)。这是为了简化表达式的撰写,并保证已有逻辑可以使用这两种类型的变量。
-
瞬时变量屏蔽(shadow)同名的持久化变量。也就是说当一个流程实例中设置了同名的持久化变量与瞬时变量时,getVariable("someVariable")会返回瞬时变量的值。
在大多数可以使用普通变量的地方,都可以获取、设置瞬时变量:
-
在JavaDelegate实现中的DelegateExecution内
-
在ExecutionListener实现中的DelegateExecution内,以及在TaskListener实现中的DelegateTask内
-
通过execution对象在脚本任务内
-
通过RuntimeService启动流程实例时
-
完成任务时
-
调用runtimeService.trigger方法时
瞬时变量相关的方法遵循普通流程变量方法的命名约定:
void setTransientVariable(String variableName, Object variableValue);
void setTransientVariableLocal(String variableName, Object variableValue);
void setTransientVariables(Map<String, Object> transientVariables);
void setTransientVariablesLocal(Map<String, Object> transientVariables);
Object getTransientVariable(String variableName);
Object getTransientVariableLocal(String variableName);
Map<String, Object> getTransientVariables();
Map<String, Object> getTransientVariablesLocal();
void removeTransientVariable(String variableName);
void removeTransientVariableLocal(String variableName);下面的BPMN流程图展示了一个典型例子:
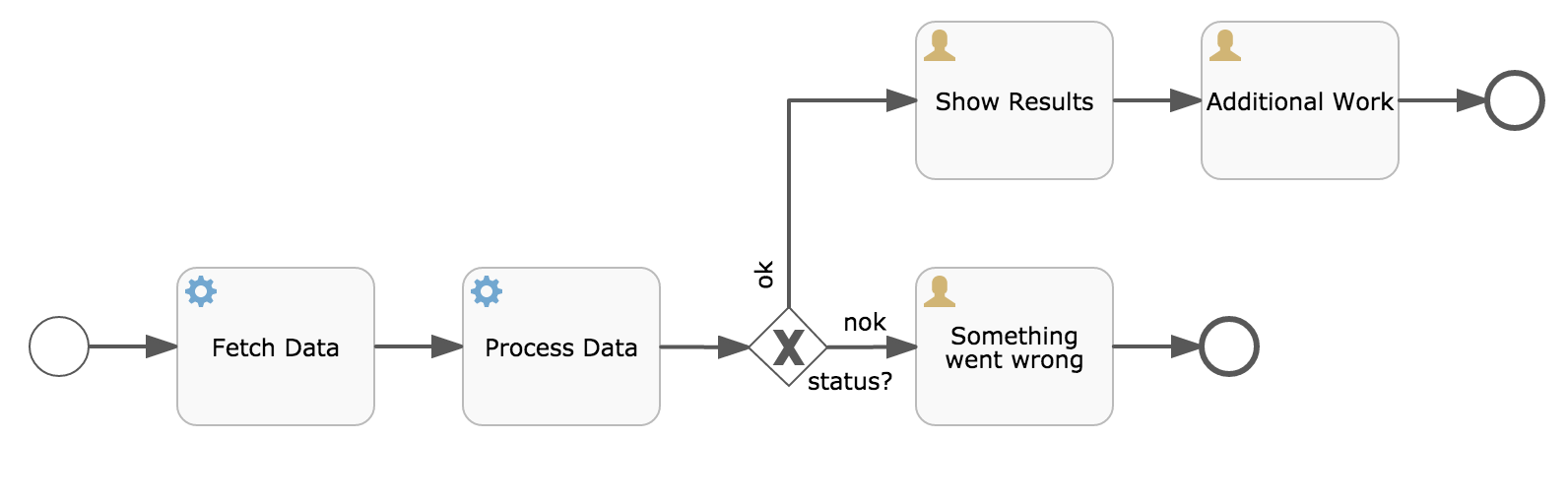
假设’Fetch Data(获取数据)'服务任务调用某个远程服务(例如使用REST)。也假设需要其需要一些配置参数,并需要在启动流程实例时提供。同时,这些配置参数对于历史审计并不重要,因此我们将它们作为瞬时变量传递:
ProcessInstance processInstance = runtimeService.createProcessInstanceBuilder()
.processDefinitionKey("someKey")
.transientVariable("configParam01", "A")
.transientVariable("configParam02", "B")
.transientVariable("configParam03", "C")
.start();请注意在到达用户任务并持久化之前,都可以使用这些瞬时变量。例如,在’Additional Work(额外工作)'用户任务中它们就不再可用。也请注意如果’Fetch Data’是异步的,则瞬时变量在该步骤之后也不再可用。
Fetch Data(的简化版本)可以像是:
public static class FetchDataServiceTask implements JavaDelegate {
public void execute(DelegateExecution execution) {
String configParam01 = (String) execution.getVariable(configParam01);
// ...
RestResponse restResponse = executeRestCall();
execution.setTransientVariable("response", restResponse.getBody());
execution.setTransientVariable("status", restResponse.getStatus());
}
}'Process Data(处理数据)'可以获取response瞬时变量,解析并将其相关数据存储在实际流程变量中,因为之后还需要使用它们。
离开排他网关的顺序流上的条件表达式,不关注使用的是持久化还是瞬时变量(在这个例子中status是瞬时变量):
<conditionExpression xsi:type="tFormalExpression">${status == 200}</conditionExpression>4.6. 表达式
Flowable使用UEL进行表达式解析。UEL代表Unified Expression Language,是EE6规范的一部分(查看EE6规范了解更多信息)。
表达式可以用于Java服务任务(Java Service task)、执行监听器(Execution Listener)、任务监听器(Task Listener) 与 条件顺序流(Conditional sequence flow)等。尽管有值表达式与方法表达式这两种不同的表达式,Flowable通过抽象,使它们都可以在需要表达式的地方使用。
-
值表达式 Value expression: 解析为一个值。默认情况下,所有流程变量都可以使用。(若使用Spring)所有的Spring bean也可以用在表达式里。例如:
${myVar}
${myBean.myProperty}
-
方法表达式 Method expression: 调用一个方法,可以带或不带参数。当调用不带参数的方法时,要确保在方法名后添加空括号(以避免与值表达式混淆)。传递的参数可以是字面值(literal value),也可以是表达式,它们会被自动解析。例如:
${printer.print()}
${myBean.addNewOrder('orderName')}
${myBean.doSomething(myVar, execution)}
请注意,表达式支持解析(及比较)原始类型(primitive)、bean、list、array与map。 Note that these expressions support resolving primitives (including comparing them), beans, lists, arrays and maps.
除了所有流程变量外,还有一些默认对象可在表达式中使用:
-
execution:DelegateExecution+,持有正在运行的执行的额外信息。 -
task:DelegateTask持有当前任务的额外信息。请注意:只在任务监听器的表达式中可用。 -
authenticatedUserId: 当前已验证的用户id。如果没有已验证的用户,该变量不可用。
更多实际使用例子,请查看Spring中的表达式、Java服务任务、执行监听器、任务监听器或者条件顺序流等章节。
4.7. 单元测试
业务流程是软件项目的必要组成部分,也需要使用测试一般应用逻辑的方法——单元测试——测试它们。Flowable是嵌入式的Java引擎,因此为业务流程编写单元测试就同编写一般的单元测试一样简单。
Flowable支持JUnit 3及4的单元测试风格。按照JUnit 3的风格,必须扩展(extended)org.flowable.engine.test.FlowableTestCase。它通过保护(protected)成员变量提供对ProcessEngine与服务的访问。在测试的setup()中,processEngine会默认使用classpath中的flowable.cfg.xml资源初始化。如果要指定不同的配置文件,请覆盖getConfigurationResource()方法。当使用相同的配置资源时,流程引擎会静态缓存,用于多个单元测试。
通过扩展FlowableTestCase,可以使用org.flowable.engine.test.Deployment注解测试方法。在测试运行前,会部署与测试类在同一个包下的格式为testClassName.testMethod.bpmn20.xml的资源文件。在测试结束时,会删除这个部署,包括所有相关的流程实例、任务,等等。也可以使用Deployment注解显式指定资源位置。查看该类以获得更多信息。
综上所述,JUnit 3风格的测试看起来类似:
public class MyBusinessProcessTest extends FlowableTestCase {
@Deployment
public void testSimpleProcess() {
runtimeService.startProcessInstanceByKey("simpleProcess");
Task task = taskService.createTaskQuery().singleResult();
assertEquals("My Task", task.getName());
taskService.complete(task.getId());
assertEquals(0, runtimeService.createProcessInstanceQuery().count());
}
}要使用JUnit 4的风格书写单元测试并达成同样的功能,必须使用org.flowable.engine.test.FlowableRule Rule。这样能够通过它的getter获得流程引擎与服务。对于FlowableTestCase(上例),包含@Rule就可以使用org.flowable.engine.test.Deployment注解(参见上例解释其用途及配置),并且会自动在classpath中寻找默认配置文件。当使用相同的配置资源时,流程引擎会静态缓存,以用于多个单元测试。
下面的代码片段展示了JUnit 4风格的测试与FlowableRule的用法。
public class MyBusinessProcessTest {
@Rule
public FlowableRule flowableRule = new FlowableRule();
@Test
@Deployment
public void ruleUsageExample() {
RuntimeService runtimeService = flowableRule.getRuntimeService();
runtimeService.startProcessInstanceByKey("ruleUsage");
TaskService taskService = flowableRule.getTaskService();
Task task = taskService.createTaskQuery().singleResult();
assertEquals("My Task", task.getName());
taskService.complete(task.getId());
assertEquals(0, runtimeService.createProcessInstanceQuery().count());
}
}4.8. 调试单元测试
当使用H2内存数据库进行单元测试时,下面的方法可以让你在调试过程中方便地检查Flowable数据库中的数据。截图来自Eclipse,但其他IDE方式相似。
假设我们的单元测试的某处放置了断点(breakpoint)(在Eclipse里可以通过在代码左侧条上双击实现):

如果我们在debug模式(在测试类中右键,选择“Run as”,然后选择“JUnit test”)下运行单元测试,测试进程会在断点处暂停,这样我们就可以在右上窗口中查看测试中的变量。
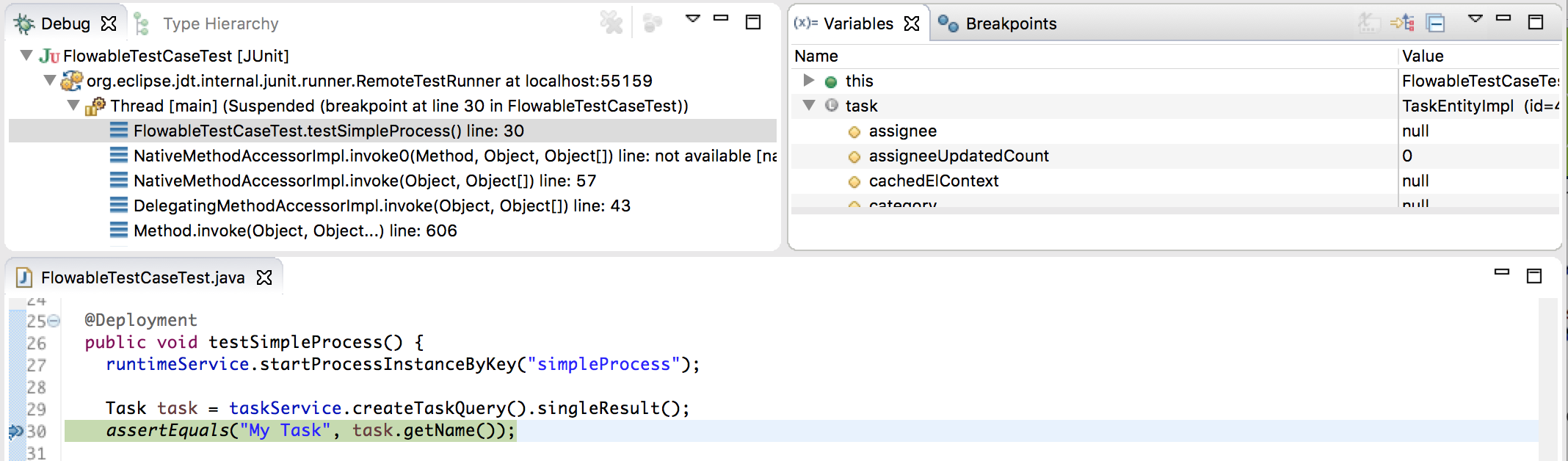
要检查Flowable的数据,打开Display窗口(如果没有找到这个窗口,打开 Window→Show View→Other,然后选择Display),并键入(可以使用代码补全)org.h2.tools.Server.createWebServer("-web").start()
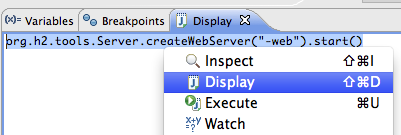
选中刚键入的行并右键点击。然后选择’Display'(或者用快捷键执行)

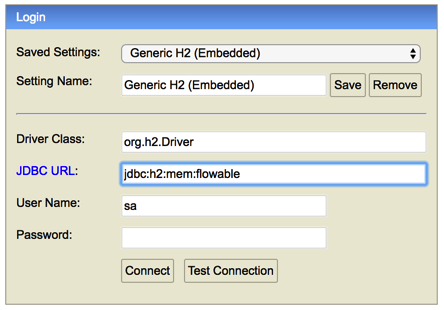
现在打开浏览器并访问http://localhost:8082,填入内存数据库的JDBC URL(默认为jdbc:h2:mem:flowable),然后点击connect按钮。
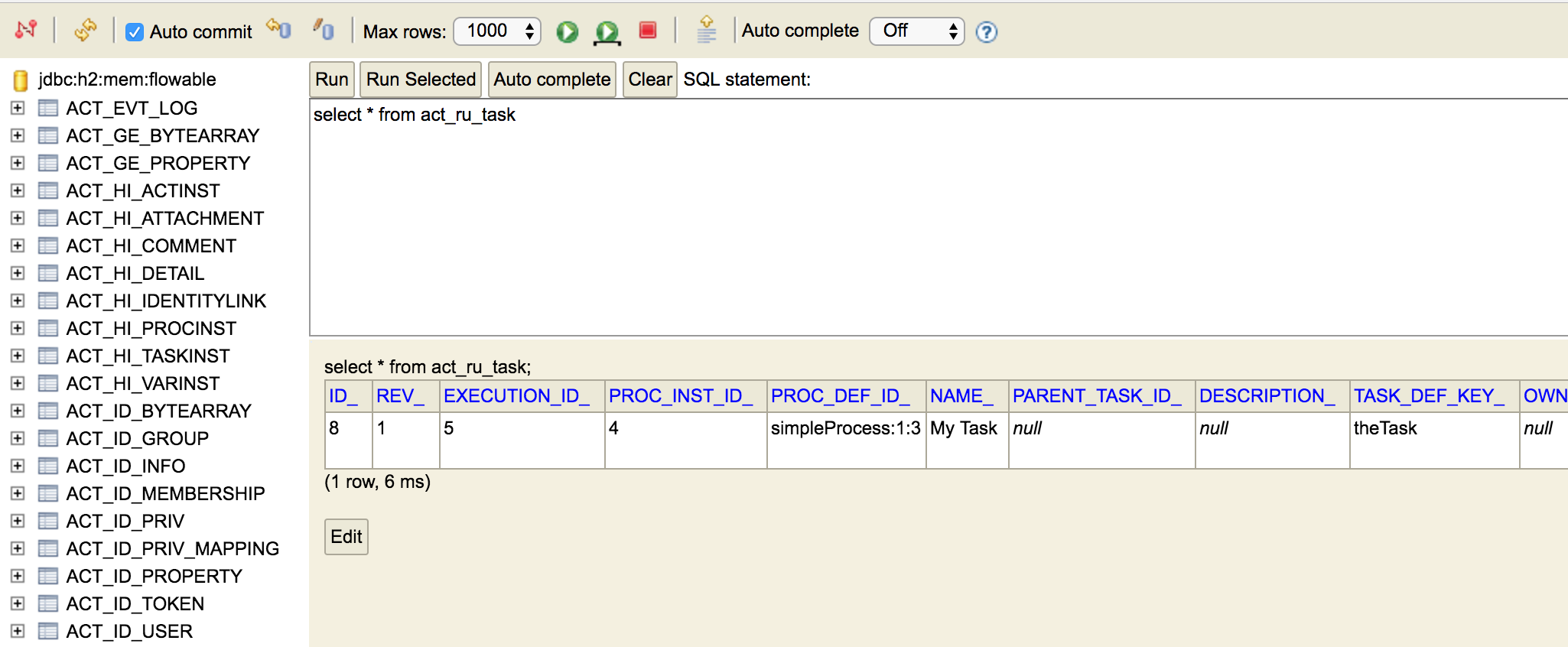
这样就可以看到Flowable的数据。便于理解单元测试执行流程的方式。
4.9. Web应用中的流程引擎
ProcessEngine是线程安全的类,可以很容易地在多个线程间共享。在web应用中,这意味着可以在容器启动时创建引擎,并在容器关闭时关闭引擎。
下面的代码片段展示了如何在Servlet环境中,通过ServletContextListener初始化与销毁流程引擎。
public class ProcessEnginesServletContextListener implements ServletContextListener {
public void contextInitialized(ServletContextEvent servletContextEvent) {
ProcessEngines.init();
}
public void contextDestroyed(ServletContextEvent servletContextEvent) {
ProcessEngines.destroy();
}
}contextInitialized方法会调用ProcessEngines.init()。它会在classpath中查找flowable.cfg.xml资源文件,并为每个文件分别创建ProcessEngine(如果多个JAR都包含配置文件)。如果在classpath中有多个这样的资源文件,请确保它们使用不同的引擎名。需要使用流程引擎时,可以这样获取:
ProcessEngines.getDefaultProcessEngine()或者
ProcessEngines.getProcessEngine("myName");当然,就像配置章节中介绍的,还可以使用各种不同的方式创建流程引擎。
context-listener的contextDestroyed方法会调用ProcessEngines.destroy()。它会妥善关闭所有已初始化的流程引擎。
5. 集成Spring
尽管完全可以脱离Spring使用Flowable,我们仍提供了很多非常好的集成特性,并将在这一章节介绍。
5.1. ProcessEngineFactoryBean
可以将ProcessEngine配置为普通的Spring bean。入口是org.flowable.spring.ProcessEngineFactoryBean类。这个bean处理流程引擎配置,并创建流程引擎。所以在Spring中创建与设置的参数与配置章节中介绍的相同。Spring集成所用的配置与引擎bean为:
<bean id="processEngineConfiguration" class="org.flowable.spring.SpringProcessEngineConfiguration">
...
</bean>
<bean id="processEngine" class="org.flowable.spring.ProcessEngineFactoryBean">
<property name="processEngineConfiguration" ref="processEngineConfiguration" />
</bean>请注意processEngineConfiguration bean现在使用org.flowable.spring.SpringProcessEngineConfiguration类。
5.2. 事务
我们会逐步说明(Flowable)发行版里,Spring示例中的SpringTransactionIntegrationTest。下面是我们示例中使用的Spring配置文件(SpringTransactionIntegrationTest-context.xml)。下面的小节包含了dataSource(数据源),transactionManager(事务管理器),processEngine(流程引擎)以及Flowable引擎服务。
将DataSource传递给SpringProcessEngineConfiguration(使用“dataSource”参数)时,Flowable会在内部使用org.springframework.jdbc.datasource.TransactionAwareDataSourceProxy对得到的数据源进行包装(wrap)。这是为了保证从数据源获取的SQL连接与Spring的事务可以协同工作。这样也就不需要在Spring配置中对数据源进行代理(proxy)。但仍然可以将代理TransactionAwareDataSourceProxy传递给SpringProcessEngineConfiguration——在这种情况下,不会再进行包装。
请确保如果自行在Spring配置中声明了TransactionAwareDataSourceProxy,则不要将它用在已经配置Spring事务的资源上(例如DataSourceTransactionManager与JPATransactionManager。它们需要未经代理的数据源)。
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:tx="http://www.springframework.org/schema/tx"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context-2.5.xsd
http://www.springframework.org/schema/tx
http://www.springframework.org/schema/tx/spring-tx-3.0.xsd">
<bean id="dataSource" class="org.springframework.jdbc.datasource.SimpleDriverDataSource">
<property name="driverClass" value="org.h2.Driver" />
<property name="url" value="jdbc:h2:mem:flowable;DB_CLOSE_DELAY=1000" />
<property name="username" value="sa" />
<property name="password" value="" />
</bean>
<bean id="transactionManager" class="org.springframework.jdbc.datasource.DataSourceTransactionManager">
<property name="dataSource" ref="dataSource" />
</bean>
<bean id="processEngineConfiguration" class="org.flowable.spring.SpringProcessEngineConfiguration">
<property name="dataSource" ref="dataSource" />
<property name="transactionManager" ref="transactionManager" />
<property name="databaseSchemaUpdate" value="true" />
<property name="asyncExecutorActivate" value="false" />
</bean>
<bean id="processEngine" class="org.flowable.spring.ProcessEngineFactoryBean">
<property name="processEngineConfiguration" ref="processEngineConfiguration" />
</bean>
<bean id="repositoryService" factory-bean="processEngine" factory-method="getRepositoryService" />
<bean id="runtimeService" factory-bean="processEngine" factory-method="getRuntimeService" />
<bean id="taskService" factory-bean="processEngine" factory-method="getTaskService" />
<bean id="historyService" factory-bean="processEngine" factory-method="getHistoryService" />
<bean id="managementService" factory-bean="processEngine" factory-method="getManagementService" />
...这个Spring配置文件也包含了在这个示例中要用到的bean与配置:
<beans>
...
<tx:annotation-driven transaction-manager="transactionManager"/>
<bean id="userBean" class="org.flowable.spring.test.UserBean">
<property name="runtimeService" ref="runtimeService" />
</bean>
<bean id="printer" class="org.flowable.spring.test.Printer" />
</beans>可以使用任何Spring支持的方式创建应用上下文(application context)。在这个例子中,可以使用classpath中的XML资源配置来创建Spring应用上下文:
ClassPathXmlApplicationContext applicationContext = new ClassPathXmlApplicationContext(
"org/flowable/examples/spring/SpringTransactionIntegrationTest-context.xml");或者在单元测试中:
@ContextConfiguration(
"classpath:org/flowable/spring/test/transaction/SpringTransactionIntegrationTest-context.xml")然后就可以获取服务bean,并调用它们的方法。ProcessEngineFactoryBean会为服务加上额外的拦截器(interceptor),并为Flowable服务方法设置Propagation.REQUIRED事务级别。这样,我们就可以使用repositoryService部署流程:
RepositoryService repositoryService =
(RepositoryService) applicationContext.getBean("repositoryService");
String deploymentId = repositoryService
.createDeployment()
.addClasspathResource("org/flowable/spring/test/hello.bpmn20.xml")
.deploy()
.getId();还有另一种方法也可以使用。如果userBean.hello()方法在Spring事务中,Flowable服务方法调用就会加入这个事务。
UserBean userBean = (UserBean) applicationContext.getBean("userBean");
userBean.hello();UserBean看起来像下面这样。请记着在上面的Spring bean配置中,我们已经将repositoryService注入了userBean。
public class UserBean {
/** 已经由Spring注入 */
private RuntimeService runtimeService;
@Transactional
public void hello() {
// 可以在你的领域模型(domain model)中进行事务操作,
// 它会与Flowable RuntimeService的startProcessInstanceByKey
// 合并在同一个事务里
runtimeService.startProcessInstanceByKey("helloProcess");
}
public void setRuntimeService(RuntimeService runtimeService) {
this.runtimeService = runtimeService;
}
}5.3. 表达式
当使用ProcessEngineFactoryBean时,默认BPMN流程中所有的表达式都可以“看见”所有的Spring bean。可以通过配置的map,限制表达式能使用的bean,甚至可以完全禁止表达式使用bean。下面的例子只暴露了一个bean(printer),可以使用“printer”作为key访问。要完全禁止表达式使用bean,可以将SpringProcessEngineConfiguration的‘beans’参数设为空list。如果不设置‘beans’参数,则上下文中的所有bean都将可以使用。
<bean id="processEngineConfiguration" class="org.flowable.spring.SpringProcessEngineConfiguration">
...
<property name="beans">
<map>
<entry key="printer" value-ref="printer" />
</map>
</property>
</bean>
<bean id="printer" class="org.flowable.examples.spring.Printer" />这样就可以在表达式中使用这个bean了。例如,SpringTransactionIntegrationTest hello.bpmn20.xml展示了如何通过UEL方法表达式(method expression)调用Spring bean:
<definitions id="definitions">
<process id="helloProcess">
<startEvent id="start" />
<sequenceFlow id="flow1" sourceRef="start" targetRef="print" />
<serviceTask id="print" flowable:expression="#{printer.printMessage()}" />
<sequenceFlow id="flow2" sourceRef="print" targetRef="end" />
<endEvent id="end" />
</process>
</definitions>其中Printer为:
public class Printer {
public void printMessage() {
System.out.println("hello world");
}
}Spring bean配置(上面已经展示过)为:
<beans>
...
<bean id="printer" class="org.flowable.examples.spring.Printer" />
</beans>5.4. 自动部署资源
集成Spring也提供了部署资源的特殊方式。在流程引擎配置中,可以指定一组资源。当创建流程引擎时,会扫描并部署这些资源。可以用过滤器阻止重复部署:只有当资源确实发生变化时,才会重新部署至Flowable数据库。在Spring容器经常重启(例如测试时)的时候,这很有用。
这里有个例子:
<bean id="processEngineConfiguration" class="org.flowable.spring.SpringProcessEngineConfiguration">
...
<property name="deploymentResources"
value="classpath*:/org/flowable/spring/test/autodeployment/autodeploy.*.bpmn20.xml" />
</bean>
<bean id="processEngine" class="org.flowable.spring.ProcessEngineFactoryBean">
<property name="processEngineConfiguration" ref="processEngineConfiguration" />
</bean>默认情况下,上面的配置方式会将符合这个过滤器的所有资源组织在一起,作为Flowable引擎的一个部署。重复检测过滤器将作用于整个部署,避免重复地部署未改变资源。有时这不是你想要的。例如,如果用这种方式部署了一组资源,即使只有其中的一个资源发生了改变,整个部署都会被视作已改变,因此这个部署中所有的所有流程定义都会被重新部署。这将导致每个流程定义都会刷新版本号(流程定义id会变化),即使实际上只有一个流程发生了变化。
可以使用SpringProcessEngineConfiguration中的额外参数+deploymentMode+,定制部署的方式。这个参数定义了对于一组符合过滤器的资源,组织部署的方式。默认这个参数有3个可用值:
-
default: 将所有资源组织在一个部署中,整体用于重复检测过滤。这是默认值,在未设置这个参数时也会用这个值。 -
single-resource: 为每个资源创建一个单独的部署,并用于重复检测过滤。如果希望单独部署每一个流程定义,并且只有在它发生变化时才创建新的流程定义版本,就应该使用这个值。 -
resource-parent-folder: 为同一个目录下的资源创建一个单独的部署,并用于重复检测过滤。这个参数值可以为大多数资源创建独立的部署。同时仍可以通过将部分资源放在同一个目录下,将它们组织在一起。这里有一个将deploymentMode设置为single-resource的例子:
<bean id="processEngineConfiguration"
class="org.flowable.spring.SpringProcessEngineConfiguration">
...
<property name="deploymentResources" value="classpath*:/flowable/*.bpmn" />
<property name="deploymentMode" value="single-resource" />
</bean>如果上述deploymentMode的参数值不能满足要求,还可以自定义组织部署的行为。创建SpringProcessEngineConfiguration的子类,并覆盖getAutoDeploymentStrategy(String deploymentMode)方法。这个方法用于确定对给定的deploymentMode参数值,应使用何种部署策略。
5.5. 单元测试
与Spring集成后,业务流程可以非常简单地使用标准的 Flowable测试工具进行测试。下面的例子展示了如何通过典型的基于Spring的单元测试,对业务流程进行测试:
@RunWith(SpringJUnit4ClassRunner.class)
@ContextConfiguration("classpath:org/flowable/spring/test/junit4/springTypicalUsageTest-context.xml")
public class MyBusinessProcessTest {
@Autowired
private RuntimeService runtimeService;
@Autowired
private TaskService taskService;
@Autowired
@Rule
public FlowableRule flowableSpringRule;
@Test
@Deployment
public void simpleProcessTest() {
runtimeService.startProcessInstanceByKey("simpleProcess");
Task task = taskService.createTaskQuery().singleResult();
assertEquals("My Task", task.getName());
taskService.complete(task.getId());
assertEquals(0, runtimeService.createProcessInstanceQuery().count());
}
}请注意要让这个例子可以正常工作,需要在Spring配置中定义org.flowable.engine.test.FlowableRule bean(在上面的例子中通过@Autowire注入)。
<bean id="flowableRule" class="org.flowable.engine.test.Flowable">
<property name="processEngine" ref="processEngine" />
</bean>5.6. 通过Hibernate 4.2.x使用JPA
要在Flowable引擎的服务任务或者监听器逻辑中使用Hibernate 4.2.x JPA,需要添加Spring ORM的额外依赖。对Hibernate 4.1.x或更低则不需要。需要添加的依赖为:
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-orm</artifactId>
<version>${org.springframework.version}</version>
</dependency>5.7. Spring Boot
Spring Boot是一个应用框架。按照其官网的介绍,可以轻松地创建独立运行的,生产级别的,基于Spring的应用,并且可以“直接运行”。它基于约定大于配置的原则使用Spring框架与第三方库,使你可以轻松地开始使用。大多数Spring Boot应用只需要很少的Spring配置。
要获得更多关于Spring Boot的信息,请查阅http://projects.spring.io/spring-boot/
Flowable与Spring Boot的集成是我们与Spring的提交者共同开发的。
5.7.1. 兼容性
Flowable使用同一个starter支持Spring Boot 2.0及1.5。主要支持Spring Boot 2.0。所以监控(actuator) endpoint只支持2.0。Flowable的starter直接引用Spring Boot starter,所以如果需要使用1.5版的Spring Boot starter,需要自行定义。
5.7.2. 开始
Spring Boot提倡约定大于配置。要开始工作,只需在项目中添加flowable-spring-boot-starter或flowable-spring-boot-starter-rest依赖。如果不需要引入所有的引擎,可以查看其它的Flowable starter。 如使用Maven:
<dependency>
<groupId>org.flowable</groupId>
<artifactId>flowable-spring-boot-starter</artifactId>
<version>${flowable.version}</version>
</dependency>就这么简单。这个依赖会自动向classpath添加正确的Flowable与Spring依赖。现在可以编写Spring Boot应用了:
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication(proxyBeanMethods = false)
public class MyApplication {
public static void main(String[] args) {
SpringApplication.run(MyApplication.class, args);
}
}Flowable需要数据库来存储数据。运行上面的代码会得到异常提示,指出需要在classpath中添加数据库驱动依赖。现在添加H2数据库依赖:
<dependency>
<groupId>com.h2database</groupId>
<artifactId>h2</artifactId>
<version>1.4.197</version>
</dependency>应用这次可以启动了。你会看到类似这样的输出:
. ____ _ __ _ _
/\\ / ___'_ __ _ _(_)_ __ __ _ \ \ \ \
( ( )\___ | '_ | '_| | '_ \/ _` | \ \ \ \
\\/ ___)| |_)| | | | | || (_| | ) ) ) )
' |____| .__|_| |_|_| |_\__, | / / / /
=========|_|==============|___/=/_/_/_/
:: Spring Boot :: (v2.0.0.RELEASE)
MyApplication : Starting MyApplication on ...
MyApplication : No active profile set, falling back to default profiles: default
ConfigServletWebServerApplicationContext : Refreshing org.springframework.boot.web.servlet.context.AnnotationConfigServletWebServerApplicationContext@4fdfa676: startup date [Wed Mar 28 12:04:00 CEST 2018]; root of context hierarchy
o.s.b.w.embedded.tomcat.TomcatWebServer : Tomcat initialized with port(s): 8080 (http)
o.apache.catalina.core.StandardService : Starting service [Tomcat]
org.apache.catalina.core.StandardEngine : Starting Servlet Engine: Apache Tomcat/8.5.28
o.a.c.c.C.[Tomcat].[localhost].[/] : Initializing Spring embedded WebApplicationContext
o.s.web.context.ContextLoader : Root WebApplicationContext: initialization completed in 3085 ms
o.s.b.w.servlet.ServletRegistrationBean : Servlet dispatcherServlet mapped to [/]
o.s.b.w.servlet.ServletRegistrationBean : Servlet Flowable IDM Rest API mapped to [/idm-api/*]
o.s.b.w.servlet.ServletRegistrationBean : Servlet Flowable Form Rest API mapped to [/form-api/*]
o.s.b.w.servlet.ServletRegistrationBean : Servlet Flowable DMN Rest API mapped to [/dmn-api/*]
o.s.b.w.servlet.ServletRegistrationBean : Servlet Flowable Content Rest API mapped to [/content-api/*]
o.s.b.w.servlet.ServletRegistrationBean : Servlet Flowable CMMN Rest API mapped to [/cmmn-api/*]
o.s.b.w.servlet.ServletRegistrationBean : Servlet Flowable BPMN Rest API mapped to [/process-api/*]
o.s.b.w.servlet.FilterRegistrationBean : Mapping filter: 'characterEncodingFilter' to: [/*]
o.s.b.w.servlet.FilterRegistrationBean : Mapping filter: 'hiddenHttpMethodFilter' to: [/*]
o.s.b.w.servlet.FilterRegistrationBean : Mapping filter: 'httpPutFormContentFilter' to: [/*]
o.s.b.w.servlet.FilterRegistrationBean : Mapping filter: 'requestContextFilter' to: [/*]
uration$$EnhancerBySpringCGLIB$$3d0c70ac : No deployment resources were found for autodeployment
uration$$EnhancerBySpringCGLIB$$8131eb1a : No deployment resources were found for autodeployment
o.f.e.i.c.ProcessEngineConfigurationImpl : Found 5 Engine Configurators in total:
o.f.e.i.c.ProcessEngineConfigurationImpl : class org.flowable.spring.configurator.SpringIdmEngineConfigurator (priority:100000)
o.f.e.i.c.ProcessEngineConfigurationImpl : class org.flowable.dmn.spring.configurator.SpringDmnEngineConfigurator (priority:200000)
o.f.e.i.c.ProcessEngineConfigurationImpl : class org.flowable.form.spring.configurator.SpringFormEngineConfigurator (priority:300000)
o.f.e.i.c.ProcessEngineConfigurationImpl : class org.flowable.content.spring.configurator.SpringContentEngineConfigurator (priority:400000)
o.f.e.i.c.ProcessEngineConfigurationImpl : class org.flowable.cmmn.spring.configurator.SpringCmmnEngineConfigurator (priority:500000)
o.f.e.i.c.ProcessEngineConfigurationImpl : Executing beforeInit() of class org.flowable.spring.configurator.SpringIdmEngineConfigurator (priority:100000)
o.f.e.i.c.ProcessEngineConfigurationImpl : Executing beforeInit() of class org.flowable.dmn.spring.configurator.SpringDmnEngineConfigurator (priority:200000)
o.f.e.i.c.ProcessEngineConfigurationImpl : Executing beforeInit() of class org.flowable.form.spring.configurator.SpringFormEngineConfigurator (priority:300000)
o.f.e.i.c.ProcessEngineConfigurationImpl : Executing beforeInit() of class org.flowable.content.spring.configurator.SpringContentEngineConfigurator (priority:400000)
o.f.e.i.c.ProcessEngineConfigurationImpl : Executing beforeInit() of class org.flowable.cmmn.spring.configurator.SpringCmmnEngineConfigurator (priority:500000)
com.zaxxer.hikari.HikariDataSource : HikariPool-1 - Starting...
com.zaxxer.hikari.HikariDataSource : HikariPool-1 - Start completed.
o.f.e.i.c.ProcessEngineConfigurationImpl : Executing configure() of class org.flowable.spring.configurator.SpringIdmEngineConfigurator (priority:100000)
.d.AbstractSqlScriptBasedDbSchemaManager : performing create on identity with resource org/flowable/idm/db/create/flowable.h2.create.identity.sql
o.f.idm.engine.impl.IdmEngineImpl : IdmEngine default created
o.f.e.i.c.ProcessEngineConfigurationImpl : Executing configure() of class org.flowable.dmn.spring.configurator.SpringDmnEngineConfigurator (priority:200000)
o.f.dmn.engine.impl.DmnEngineImpl : DmnEngine default created
o.f.e.i.c.ProcessEngineConfigurationImpl : Executing configure() of class org.flowable.form.spring.configurator.SpringFormEngineConfigurator (priority:300000)
o.f.form.engine.impl.FormEngineImpl : FormEngine default created
o.f.e.i.c.ProcessEngineConfigurationImpl : Executing configure() of class org.flowable.content.spring.configurator.SpringContentEngineConfigurator (priority:400000)
o.f.c.engine.ContentEngineConfiguration : Content file system root : ...
o.f.c.engine.impl.ContentEngineImpl : ContentEngine default created
o.f.e.i.c.ProcessEngineConfigurationImpl : Executing configure() of class org.flowable.cmmn.spring.configurator.SpringCmmnEngineConfigurator (priority:500000)
o.f.cmmn.engine.CmmnEngineConfiguration : Found 1 Engine Configurators in total:
o.f.cmmn.engine.CmmnEngineConfiguration : class org.flowable.cmmn.engine.impl.cfg.IdmEngineConfigurator (priority:100000)
o.f.cmmn.engine.CmmnEngineConfiguration : Executing beforeInit() of class org.flowable.cmmn.engine.impl.cfg.IdmEngineConfigurator (priority:100000)
o.f.cmmn.engine.CmmnEngineConfiguration : Executing configure() of class org.flowable.cmmn.engine.impl.cfg.IdmEngineConfigurator (priority:100000)
o.f.idm.engine.impl.IdmEngineImpl : IdmEngine default created
o.f.cmmn.engine.impl.CmmnEngineImpl : CmmnEngine default created
o.f.engine.impl.ProcessEngineImpl : ProcessEngine default created
o.f.j.s.i.a.AbstractAsyncExecutor : Starting up the async job executor [org.flowable.spring.job.service.SpringAsyncExecutor].
o.f.j.s.i.a.AcquireAsyncJobsDueRunnable : starting to acquire async jobs due
o.f.j.s.i.a.AcquireTimerJobsRunnable : starting to acquire async jobs due
o.f.j.s.i.a.ResetExpiredJobsRunnable : starting to reset expired jobs
o.f.e.impl.cmd.ValidateV5EntitiesCmd : Total of v5 deployments found: 0
s.w.s.m.m.a.RequestMappingHandlerAdapter : Looking for @ControllerAdvice: org.springframework.boot.web.servlet.context.AnnotationConfigServletWebServerApplicationContext@4fdfa676: startup date [Wed Mar 28 12:04:00 CEST 2018]; root of context hierarchy
s.w.s.m.m.a.RequestMappingHandlerMapping : Mapped "{[/error]}" onto public org.springframework.http.ResponseEntity<java.util.Map<java.lang.String, java.lang.Object>> org.springframework.boot.autoconfigure.web.servlet.error.BasicErrorController.error(javax.servlet.http.HttpServletRequest)
s.w.s.m.m.a.RequestMappingHandlerMapping : Mapped "{[/error],produces=[text/html]}" onto public org.springframework.web.servlet.ModelAndView org.springframework.boot.autoconfigure.web.servlet.error.BasicErrorController.errorHtml(javax.servlet.http.HttpServletRequest,javax.servlet.http.HttpServletResponse)
o.s.w.s.handler.SimpleUrlHandlerMapping : Mapped URL path [/webjars/**] onto handler of type [class org.springframework.web.servlet.resource.ResourceHttpRequestHandler]
o.s.w.s.handler.SimpleUrlHandlerMapping : Mapped URL path [/**] onto handler of type [class org.springframework.web.servlet.resource.ResourceHttpRequestHandler]
o.s.w.s.handler.SimpleUrlHandlerMapping : Mapped URL path [/**/favicon.ico] onto handler of type [class org.springframework.web.servlet.resource.ResourceHttpRequestHandler]
o.s.j.e.a.AnnotationMBeanExporter : Registering beans for JMX exposure on startup
o.s.j.e.a.AnnotationMBeanExporter : Bean with name 'dataSource' has been autodetected for JMX exposure
o.s.j.e.a.AnnotationMBeanExporter : Located MBean 'dataSource': registering with JMX server as MBean [com.zaxxer.hikari:name=dataSource,type=HikariDataSource]
o.s.c.support.DefaultLifecycleProcessor : Starting beans in phase -20
o.s.c.support.DefaultLifecycleProcessor : Starting beans in phase 0
o.s.c.support.DefaultLifecycleProcessor : Starting beans in phase 20
o.s.b.w.embedded.tomcat.TomcatWebServer : Tomcat started on port(s): 8080 (http) with context path ''
flowable.Application : Started Application in 18.235 seconds (JVM running for 19.661)
只是在classpath中添加依赖,并使用@SpringBootAplication注解,就会在幕后发生很多事情:
-
自动创建了内存数据库(因为classpath中有H2驱动),并传递给Flowable流程引擎配置
-
创建并暴露了Flowable的ProcessEngine、CmmnEngine、DmnEngine、FormEngine、ContentEngine及IdmEngine bean
-
所有的Flowable服务都暴露为Spring bean
-
创建了Spring Job Executor
并且:
-
processes目录下的任何BPMN 2.0流程定义都会被自动部署。创建processes目录,并在其中创建示例流程定义(命名为one-task-process.bpmn20.xml)。
-
cases目录下的任何CMMN 1.1事例都会被自动部署。
-
forms目录下的任何Form定义都会被自动部署。
<?xml version="1.0" encoding="UTF-8"?>
<definitions
xmlns="http://www.omg.org/spec/BPMN/20100524/MODEL"
xmlns:flowable="http://flowable.org/bpmn"
targetNamespace="Examples">
<process id="oneTaskProcess" name="The One Task Process">
<startEvent id="theStart" />
<sequenceFlow id="flow1" sourceRef="theStart" targetRef="theTask" />
<userTask id="theTask" name="my task" />
<sequenceFlow id="flow2" sourceRef="theTask" targetRef="theEnd" />
<endEvent id="theEnd" />
</process>
</definitions>然后添加下列代码,以测试部署是否生效。CommandLineRunner是一个特殊的Spring bean,在应用启动时执行:
@SpringBootApplication(proxyBeanMethods = false)
public class MyApplication {
public static void main(String[] args) {
SpringApplication.run(MyApplication.class, args);
}
@Bean
public CommandLineRunner init(final RepositoryService repositoryService,
final RuntimeService runtimeService,
final TaskService taskService) {
return new CommandLineRunner() {
@Override
public void run(String... strings) throws Exception {
System.out.println("Number of process definitions : "
+ repositoryService.createProcessDefinitionQuery().count());
System.out.println("Number of tasks : " + taskService.createTaskQuery().count());
runtimeService.startProcessInstanceByKey("oneTaskProcess");
System.out.println("Number of tasks after process start: "
+ taskService.createTaskQuery().count());
}
};
}
}会得到这样的输出:
Number of process definitions : 1 Number of tasks : 0 Number of tasks after process start : 1
5.7.3. 更换数据源与连接池
上面也提到过,Spring Boot的约定大于配置。默认情况下,如果classpath中只有H2,就会创建内存数据库,并传递给Flowable流程引擎配置。
只要添加一个数据库驱动的依赖并提供数据库URL,就可以更换数据源。例如,要切换到MySQL数据库:
spring.datasource.url=jdbc:mysql://127.0.0.1:3306/flowable-spring-boot?characterEncoding=UTF-8
spring.datasource.username=flowable
spring.datasource.password=flowable从Maven依赖中移除H2,并在classpath中添加MySQL驱动:
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.45</version>
</dependency>这次应用启动后,可以看到使用了MySQL作为数据库(并使用HikariCP连接池框架):
org.flowable.engine.impl.db.DbSqlSession : performing create on engine with resource org/flowable/db/create/flowable.mysql.create.engine.sql org.flowable.engine.impl.db.DbSqlSession : performing create on history with resource org/flowable/db/create/flowable.mysql.create.history.sql org.flowable.engine.impl.db.DbSqlSession : performing create on identity with resource org/flowable/db/create/flowable.mysql.create.identity.sql
多次重启应用,会发现任务的数量增加了(H2内存数据库在关闭后会丢失,而MySQL不会)。
关于配置数据源的更多信息,可以在Spring Boot的参考手册中Configure a DataSource(配置数据源)章节查看。
5.7.4. REST 支持
通常会在嵌入的Flowable引擎之上,使用REST API(用于与公司的不同服务交互)。Spring Boot让这变得很容易。在classpath中添加下列依赖:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<version>${spring.boot.version}</version>
</dependency>创建一个新的Spring服务类,并创建两个方法:一个用于启动流程,另一个用于获得给定任务办理人的任务列表。在这里只是简单地包装了Flowable调用,但在实际使用场景中会比这复杂得多。
@Service
public class MyService {
@Autowired
private RuntimeService runtimeService;
@Autowired
private TaskService taskService;
@Transactional
public void startProcess() {
runtimeService.startProcessInstanceByKey("oneTaskProcess");
}
@Transactional
public List<Task> getTasks(String assignee) {
return taskService.createTaskQuery().taskAssignee(assignee).list();
}
}现在可以用@RestController来注解类,以创建REST endpoint。在这里我们简单地调用上面定义的服务。
@RestController
public class MyRestController {
@Autowired
private MyService myService;
@PostMapping(value="/process")
public void startProcessInstance() {
myService.startProcess();
}
@RequestMapping(value="/tasks", method= RequestMethod.GET, produces=MediaType.APPLICATION_JSON_VALUE)
public List<TaskRepresentation> getTasks(@RequestParam String assignee) {
List<Task> tasks = myService.getTasks(assignee);
List<TaskRepresentation> dtos = new ArrayList<TaskRepresentation>();
for (Task task : tasks) {
dtos.add(new TaskRepresentation(task.getId(), task.getName()));
}
return dtos;
}
static class TaskRepresentation {
private String id;
private String name;
public TaskRepresentation(String id, String name) {
this.id = id;
this.name = name;
}
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}
}Spring Boot会自动扫描组件,并找到我们添加在应用类上的@Service与@RestController。再次运行应用,现在可以与REST API交互了。例如使用cURL:
curl http://localhost:8080/tasks?assignee=kermit
[]
curl -X POST http://localhost:8080/process
curl http://localhost:8080/tasks?assignee=kermit
[{"id":"10004","name":"my task"}]
5.7.5. JPA 支持
要为Spring Boot中的Flowable添加JPA支持,增加下列依赖:
<dependency>
<groupId>org.flowable</groupId>
<artifactId>flowable-spring-boot-starter</artifactId>
<version>${flowable.version}</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
<version>${spring-boot.version</version>
</dependency>这会加入JPA用的Spring配置以及bean。默认使用Hibernate作为JPA提供者。
创建一个简单的实体类:
@Entity
class Person {
@Id
@GeneratedValue
private Long id;
private String username;
private String firstName;
private String lastName;
private Date birthDate;
public Person() {
}
public Person(String username, String firstName, String lastName, Date birthDate) {
this.username = username;
this.firstName = firstName;
this.lastName = lastName;
this.birthDate = birthDate;
}
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
public String getUsername() {
return username;
}
public void setUsername(String username) {
this.username = username;
}
public String getFirstName() {
return firstName;
}
public void setFirstName(String firstName) {
this.firstName = firstName;
}
public String getLastName() {
return lastName;
}
public void setLastName(String lastName) {
this.lastName = lastName;
}
public Date getBirthDate() {
return birthDate;
}
public void setBirthDate(Date birthDate) {
this.birthDate = birthDate;
}
}默认情况下,如果没有使用内存数据库则不会自动创建数据库表。在classpath中创建application.properties文件并加入下列参数:
spring.jpa.hibernate.ddl-auto=update
添加下列类:
@Repository
public interface PersonRepository extends JpaRepository<Person, Long> {
Person findByUsername(String username);
}这是一个Spring repository,提供了直接可用的增删改查。我们添加了通过username查找Person的方法。Spring会基于约定自动实现它(也就是使用names属性)。
现在进一步增强我们的服务:
-
在类上添加@Transactional。请注意,通过上面添加的JPA依赖,之前使用的DataSourceTransactionManager会自动替换为JpaTransactionManager。
-
startProcess增加了任务办理人入参,用于查找Person,并将Person JPA对象作为流程变量存入流程实例。
-
添加了创建示例用户的方法。CommandLineRunner使用它打桩数据库。
@Service
@Transactional
public class MyService {
@Autowired
private RuntimeService runtimeService;
@Autowired
private TaskService taskService;
@Autowired
private PersonRepository personRepository;
public void startProcess(String assignee) {
Person person = personRepository.findByUsername(assignee);
Map<String, Object> variables = new HashMap<String, Object>();
variables.put("person", person);
runtimeService.startProcessInstanceByKey("oneTaskProcess", variables);
}
public List<Task> getTasks(String assignee) {
return taskService.createTaskQuery().taskAssignee(assignee).list();
}
public void createDemoUsers() {
if (personRepository.findAll().size() == 0) {
personRepository.save(new Person("jbarrez", "Joram", "Barrez", new Date()));
personRepository.save(new Person("trademakers", "Tijs", "Rademakers", new Date()));
}
}
}CommandLineRunner现在为:
@Bean
public CommandLineRunner init(final MyService myService) {
return new CommandLineRunner() {
public void run(String... strings) throws Exception {
myService.createDemoUsers();
}
};
}RestController也有小改动(只展示新方法),以配合上面的修改。HTTP POST使用body传递办理人用户名:
@RestController
public class MyRestController {
@Autowired
private MyService myService;
@PostMapping(value="/process")
public void startProcessInstance(@RequestBody StartProcessRepresentation startProcessRepresentation) {
myService.startProcess(startProcessRepresentation.getAssignee());
}
...
static class StartProcessRepresentation {
private String assignee;
public String getAssignee() {
return assignee;
}
public void setAssignee(String assignee) {
this.assignee = assignee;
}
}最后,为了试用Spring-JPA-Flowable集成,我们在流程定义中,将Person JPA对象的ID指派为任务办理人:
<userTask id="theTask" name="my task" flowable:assignee="${person.id}"/>现在可以在POST body中提供用户名,启动一个新的流程实例:
curl -H "Content-Type: application/json" -d '{"assignee" : "jbarrez"}' http://localhost:8080/process
可以使用Person id获取任务列表:
curl http://localhost:8080/tasks?assignee=1
[{"id":"12505","name":"my task"}]
5.7.6. Flowable Actuator Endpoint
Flowable提供了Spring Boot Actuator Endpoint,以提供正在运行的流程的信息。
默认情况下 flowable 端点映射至 /actuator/flowable 。
Spring Boot默认只通过web暴露少许端点(例如:在 spring-boot-starter-actuator:2.5.4 中, Spring Boot 默认只通过web暴露了 health 端点。更多有关于 Spring Boot 默认暴露的端点的信息,请参考 https://docs.spring.io/spring-boot/docs/current/reference/html/actuator.html#actuator.endpoints.exposing )。要通过web使用 flowable 端点,需要在 application.properties 中添加 management.endpoints.web.exposure.include=flowable (注意: org.flowable.spring.boot.EndpointAutoConfiguration 类没有使用 @ConditionalOnAvailableEndpoint 注解检查 flowable 的端点是否同时被启用和被暴露。所以为了通过web使用 flowable 端点,你只需要在配置文件中添加 management.endpoints.web.exposure.include=flowable 或 management.endpoints.web.exposure.include=* 即可)。
curl http://localhost:8080/actuator/flowable
{
"completedTaskCountToday": 0,
"deployedProcessDefinitions": [
"oneTaskProcess (v1)"
],
"processDefinitionCount": 1,
"cachedProcessDefinitionCount": 0,
"runningProcessInstanceCount": {
"oneTaskProcess (v1)": 0
},
"completedTaskCount": 2,
"completedActivities": 3,
"completedProcessInstanceCount": {
"oneTaskProcess (v1)": 0
},
"openTaskCount": 0
}要了解Spring Boot Actuator的更多信息,可以在Spring Boot参考手册中查看Production Ready Endpoint(生产可用的端点)。
5.7.7. Flowable Info Contributor
Flowable也提供了Spring Boot的 InfoContributor :
curl http://localhost:8080/actuator/info
{
"flowable": {
"version": "6.3.0.1"
}
}5.7.8. 配置Flowable应用
Flowable会自动配置用于控制Spring Boot的参数与配置。参见Spring Boot参考手册中的Properties and Configuration(参数与配置)。
下面是Flowable Spring Boot支持的配置参数列表。
# ===================================================================
# Common Flowable Spring Boot Properties
# 通用Flowable Spring Boot参数
#
# This sample file is provided as a guideline. Do NOT copy it in its
# entirety to your own application. ^^^
# 本示例文件只作为指导。请不要直接拷贝至你自己的应用中。
# ===================================================================
# Core (Process) FlowableProperties
# 核心(流程)
flowable.check-process-definitions=true # 是否需要自动部署流程定义。
flowable.custom-mybatis-mappers= # 需要添加至引擎的自定义Mybatis映射的FQN。
flowable.custom-mybatis-x-m-l-mappers= # 需要添加至引擎的自定义Mybatis XML映射的路径。
flowable.database-schema= # 如果数据库返回的元数据不正确,可以在这里设置schema用于检测/生成表。
flowable.database-schema-update=true # 数据库schema更新策略。
flowable.db-history-used=true # 是否要使用db历史。
flowable.deployment-name=SpringBootAutoDeployment # 自动部署的名称。
flowable.history-level=audit # 要使用的历史级别。
flowable.process-definition-location-prefix=classpath*:/processes/ # 自动部署时查找流程的目录。
flowable.process-definition-location-suffixes=**.bpmn20.xml,**.bpmn # 'processDefinitionLocationPrefix'路径下需要部署的文件的后缀(扩展名)。
# Process FlowableProcessProperties
# 流程
flowable.process.definition-cache-limit=-1 # 流程定义缓存中保存流程定义的最大数量。默认值为-1(缓存所有流程定义)。
flowable.process.enable-safe-xml=true # 在解析BPMN XML文件时进行额外检查。参见 https://www.flowable.org/docs/userguide/index.html#advanced.safe.bpmn.xml 。不幸的是,部分平台(JDK 6,JBoss)上无法使用这个功能,因此如果你所用的平台在XML解析时不支持StaxSource,需要禁用这个功能。
flowable.process.servlet.load-on-startup=-1 # 启动时加载Process servlet。
flowable.process.servlet.name=Flowable BPMN Rest API # Process servlet的名字。
flowable.process.servlet.path=/process-api # Process servelet的context path。
# Process Async Executor
# 流程异步执行器
flowable.process.async-executor-activate=true # 是否启用异步执行器。
flowable.process.async.executor.async-job-lock-time-in-millis=300000 # 异步作业在被异步执行器取走后的锁定时间(以毫秒计)。在这段时间内,其它异步执行器不会尝试获取及锁定这个任务。
flowable.process.async.executor.default-async-job-acquire-wait-time-in-millis=10000 # 异步作业获取线程在进行下次获取查询前的等待时间(以毫秒计)。只在当次没有取到新的异步作业,或者只取到很少的异步作业时生效。默认值 = 10秒。
flowable.process.async.executor.default-queue-size-full-wait-time-in-millis=0 # 异步作业(包括定时器作业与异步执行)获取线程在队列满时,等待执行下次查询的等待时间(以毫秒计)。默认值为0(以向后兼容)
flowable.process.async.executor.default-timer-job-acquire-wait-time-in-millis=10000 # 定时器作业获取线程在进行下次获取查询前的等待时间(以毫秒计)。只在当次没有取到新的定时器作业,或者只取到很少的定时器作业时生效。默认值 = 10秒。
flowable.process.async.executor.max-async-jobs-due-per-acquisition=1 # (译者补)单次查询的异步作业数量。默认值为1,以降低乐观锁异常的可能性。除非你知道自己在做什么,否则请不要修改这个值。
flowable.process.async.executor.retry-wait-time-in-millis=500 # ???(译者补不了了)
flowable.process.async.executor.timer-lock-time-in-millis=300000 # 定时器作业在被异步执行器取走后的锁定时间(以毫秒计)。在这段时间内,其它异步执行器不会尝试获取及锁定这个任务。
# CMMN FlowableCmmnProperties
flowable.cmmn.deploy-resources=true # 是否部署资源。默认值为'true'。
flowable.cmmn.deployment-name=SpringBootAutoDeployment # CMMN资源部署的名字。
flowable.cmmn.enable-safe-xml=true # 在解析CMMN XML文件时进行额外检查。参见 https://www.flowable.org/docs/userguide/index.html#advanced.safe.bpmn.xml 。不幸的是,部分平台(JDK 6,JBoss)上无法使用这个功能,因此如果你所用的平台在XML解析时不支持StaxSource,需要禁用这个功能。
flowable.cmmn.enabled=true # 是否启用CMMN引擎。
flowable.cmmn.resource-location=classpath*:/cases/ # CMMN资源的路径。
flowable.cmmn.resource-suffixes=**.cmmn,**.cmmn11,**.cmmn.xml,**.cmmn11.xml # 需要扫描的资源后缀名。
flowable.cmmn.servlet.load-on-startup=-1 # 启动时加载CMMN servlet。
flowable.cmmn.servlet.name=Flowable CMMN Rest API # CMMN servlet的名字。
flowable.cmmn.servlet.path=/cmmn-api # CMMN servlet的context path。
# CMMN Async Executor
# CMMN异步执行器
flowable.cmmn.async-executor-activate=true # 是否启用异步执行器。
flowable.cmmn.async.executor.async-job-lock-time-in-millis=300000 # 异步作业在被异步执行器取走后的锁定时间(以毫秒计)。在这段时间内,其它异步执行器不会尝试获取及锁定这个任务。
flowable.cmmn.async.executor.default-async-job-acquire-wait-time-in-millis=10000 # 异步作业获取线程在进行下次获取查询前的等待时间(以毫秒计)。只在当次没有取到新的异步作业,或者只取到很少的异步作业时生效。默认值 = 10秒。
flowable.cmmn.async.executor.default-queue-size-full-wait-time-in-millis=0 # 异步作业(包括定时器作业与异步执行)获取线程在队列满时,等待执行下次查询的等待时间(以毫秒计)。默认值为0(以向后兼容)
flowable.cmmn.async.executor.default-timer-job-acquire-wait-time-in-millis=10000 # 定时器作业获取线程在进行下次获取查询前的等待时间(以毫秒计)。只在当次没有取到新的定时器作业,或者只取到很少的定时器作业时生效。默认值 = 10秒。
flowable.cmmn.async.executor.max-async-jobs-due-per-acquisition=1 # (译者补)单次查询的异步作业数量。默认值为1,以降低乐观锁异常的可能性。除非你知道自己在做什么,否则请不要修改这个值。
flowable.cmmn.async.executor.retry-wait-time-in-millis=500 #(译者补不了了)
flowable.cmmn.async.executor.timer-lock-time-in-millis=300000 # 定时器作业在被异步执行器取走后的锁定时间(以毫秒计)。在这段时间内,其它异步执行器不会尝试获取及锁定这个任务。
# Content FlowableContentProperties
flowable.content.enabled=true # 是否启动Content引擎。
flowable.content.servlet.load-on-startup=-1 # 启动时加载Content servlet。
flowable.content.servlet.name=Flowable Content Rest API # Content servlet的名字。
flowable.content.servlet.path=/content-api # Content servlet的context path。
flowable.content.storage.create-root=true # 如果根路径不存在,是否需要创建?
flowable.content.storage.root-folder= # 存储content文件(如上传的任务附件,或表单文件)的根路径。
# DMN FlowableDmnProperties
flowable.dmn.deploy-resources=true # 是否部署资源。默认为'true'。
flowable.dmn.deployment-name=SpringBootAutoDeployment # DMN资源部署的名字。
flowable.dmn.enable-safe-xml=true # 在解析DMN XML文件时进行额外检查。参见 https://www.flowable.org/docs/userguide/index.html#advanced.safe.bpmn.xml 。不幸的是,部分平台(JDK 6,JBoss)上无法使用这个功能,因此如果你所用的平台在XML解析时不支持StaxSource,需要禁用这个功能。
flowable.dmn.enabled=true # 是否启用DMN引擎。
flowable.dmn.history-enabled=true # 是否启用DMN引擎的历史。
flowable.dmn.resource-location=classpath*:/dmn/ # DMN资源的路径。
flowable.dmn.resource-suffixes=**.dmn,**.dmn.xml,**.dmn11,**.dmn11.xml # 需要扫描的资源后缀名。
flowable.dmn.servlet.load-on-startup=-1 # 启动时加载DMN servlet。
flowable.dmn.servlet.name=Flowable DMN Rest API # DMN servlet的名字。
flowable.dmn.servlet.path=/dmn-api # DMN servlet的context path。
flowable.dmn.strict-mode=true # 如果希望避免抉择表命中策略检查导致失败,可以将本参数设置为false。如果检查发现了错误,会直接返回错误前一刻的中间结果。
# Form FlowableFormProperties
flowable.form.deploy-resources=true # 是否部署资源。默认为'true'。
flowable.form.deployment-name=SpringBootAutoDeployment # Form资源部署的名字。
flowable.form.enabled=true # 是否启用Form引擎。
flowable.form.resource-location=classpath*:/forms/ # Form资源的路径。
flowable.form.resource-suffixes=**.form # 需要扫描的资源后缀名。
flowable.form.servlet.load-on-startup=-1 # 启动时加载Form servlet。
flowable.form.servlet.name=Flowable Form Rest API # Form servlet的名字。
flowable.form.servlet.path=/form-api # Form servlet的context path。
# IDM FlowableIdmProperties
flowable.idm.enabled=true # 是否启用IDM引擎。
flowable.idm.password-encoder= # 使用的密码编码类型。
flowable.idm.servlet.load-on-startup=-1 # 启动时加载IDM servlet。
flowable.idm.servlet.name=Flowable IDM Rest API # IDM servlet的名字。
flowable.idm.servlet.path=/idm-api # IDM servlet的context path。
# IDM Ldap FlowableLdapProperties
flowable.idm.ldap.attribute.email= # 用户email的属性名。
flowable.idm.ldap.attribute.first-name= # 用户名字的属性名。
flowable.idm.ldap.attribute.group-id= # 用户组ID的属性名。
flowable.idm.ldap.attribute.group-name= # 用户组名的属性名。
flowable.idm.ldap.attribute.group-type= # 用户组类型的属性名。
flowable.idm.ldap.attribute.last-name= # 用户姓的属性名。
flowable.idm.ldap.attribute.user-id= # 用户ID的属性名。
flowable.idm.ldap.base-dn= # 查找用户与组的DN(标志名称 distinguished name)。
flowable.idm.ldap.cache.group-size=-1 # 设置{@link org.flowable.ldap.LDAPGroupCache}的大小。这是LRU缓存,用于缓存用户及组,以避免每次都查询LDAP系统。
flowable.idm.ldap.custom-connection-parameters= # 用于设置所有没有专用setter的LDAP连接参数。查看 http://docs.oracle.com/javase/tutorial/jndi/ldap/jndi.html 介绍的自定义参数。参数包括配置链接池,安全设置,等等。
flowable.idm.ldap.enabled=false # 是否启用LDAP IDM 服务。
flowable.idm.ldap.group-base-dn= # 组查找的DN。
flowable.idm.ldap.initial-context-factory=com.sun.jndi.ldap.LdapCtxFactory # 初始化上下文工厂的类名。
flowable.idm.ldap.password= # 连接LDAP系统的密码。
flowable.idm.ldap.port=-1 # LDAP系统的端口。
flowable.idm.ldap.query.all-groups= # 查询所有组所用的语句。
flowable.idm.ldap.query.all-users= # 查询所有用户所用的语句。
flowable.idm.ldap.query.groups-for-user= # 按照指定用户查询所属组所用的语句
flowable.idm.ldap.query.user-by-full-name-like= # 按照给定全名查找用户所用的语句。
flowable.idm.ldap.query.user-by-id= # 按照userId查找用户所用的语句。
flowable.idm.ldap.search-time-limit=0 # 查询LDAP的超时时间(以毫秒计)。默认值为'0',即“一直等待”。
flowable.idm.ldap.security-authentication=simple # 连接LDAP系统所用的'java.naming.security.authentication'参数的值。
flowable.idm.ldap.server= # LDAP系统的主机名。如'ldap://localhost'。
flowable.idm.ldap.user= # 连接LDAP系统的用户ID。
flowable.idm.ldap.user-base-dn= # 查找用户的DN。
# Flowable Mail FlowableMailProperties
flowable.mail.server.default-from=flowable@localhost # 发送邮件时使用的默认发信人地址。
flowable.mail.server.host=localhost # 邮件服务器。
flowable.mail.server.password= # 邮件服务器的登录密码。
flowable.mail.server.port=1025 # 邮件服务器的端口号。
flowable.mail.server.ssl-port=1465 # SSL邮件服务器的端口号。
flowable.mail.server.use-ssl=false # 是否使用SSL/TLS加密SMTP传输连接(即SMTPS/POPS)。
flowable.mail.server.use-tls=false # 使用或禁用STARTTLS加密。
flowable.mail.server.username= # 邮件服务器的登录用户名。如果为空,则不需要登录。
# Flowable Http FlowableHttpProperties
flowable.http.user-system-properties=false # 是否使用系统属性 (e.g. http.proxyPort).
flowable.http.connect-timeout=5s # 连接http客户端的超时时间
flowable.http.socket-timeout=5s # http客户端的Socket超时时间
flowable.http.connection-request-timeout=5s # http客户端的连接请求超时时间
flowable.http.request-retry-limit=3 # 请求http客户端的重试限制
flowable.http.disable-cert-verify=false # 是否禁用http客户端的证书验证
# Flowable REST
flowable.rest.app.cors.enabled=true # Whether to enable CORS requests at all. If false, the other properties have no effect
flowable.rest.app.cors.allow-credentials=true # Whether to include credentials in a CORS request
flowable.rest.app.cors.allowed-origins=* # Comma-separated URLs to accept CORS requests from
flowable.rest.app.cors.allowed-headers=* # Comma-separated HTTP headers to allow in a CORS request
flowable.rest.app.cors.allowed-methods=DELETE,GET,PATCH,POST,PUT # Comma-separated HTTP verbs to allow in a CORS request
flowable.rest.app.cors.exposed-headers=* # Comma-separated list of headers to expose in CORS response
# Actuator
management.endpoint.flowable.cache.time-to-live=0ms # 缓存响应的最大时间。
management.endpoint.flowable.enabled=true # 是否启用flowable端点。| 现参数 | 原参数 | 默认值 | 描述 |
|---|---|---|---|
flowable.process.servlet.name |
flowable.rest-api-servlet-name |
Flowable BPMN Rest API |
Process servlet的名字。 |
flowable.process.servlet.path |
flowable.rest-api-mapping |
/process-api |
Process servlet的context path。 |
flowable.mail.server.host |
flowable.mail-server-host |
localhost |
邮件服务器。 |
flowable.mail.server.password |
flowable.mail-server-password |
- |
邮件服务器的密码。 |
flowable.mail.server.port |
flowable.mail-server-port |
1025 |
邮件服务器的端口号。 |
flowable.mail.server.ssl-port |
flowable.mail-server-ssl-port |
1465 |
SSL邮件服务器的端口号。 |
flowable.mail.server.use-ssl |
flowable.mail-server-use-ssl |
false |
是否使用SSL/TLS加密SMTP传输连接(即SMTPS/POPS)。 |
flowable.mail.server.use-tls |
flowable.mail-server-use-tls |
false |
使用或禁用STARTTLS加密。 |
flowable.mail.server.username |
flowable.mail-server-user-name |
- |
邮件服务器的登录用户名。如果为空,则不需要登录。 |
flowable.process.definition-cache-limit |
flowable.process-definitions.cache.max |
-1 |
流程定义缓存中保存流程定义的最大数量。默认值为-1(缓存所有流程定义)。 |
5.7.9. Flowable自动配置类
这是Flowable提供的所有自动配置类的列表,并包括了文档及源码的连接。记得查看你的应用的conditions报告,以确认具体启用了哪些功能。(使用—debug或-Ddebug或在Actuator应用中启动应用,并使用 conditions 端点)。
| 配置类 |
|---|
5.7.10. Flowable Starter
这是Flowable Spring Boot stater的列表。
| Starter | 描述 |
|---|---|
提供以独立运行模式启动CMMN引擎的依赖 |
|
提供以独立运行模式启动CMMN引擎,并提供其REST API的依赖。 |
|
提供以独立运行模式启动DMN引擎的依赖。 |
|
提供以独立运行模式启动DMN引擎,并提供其REST API的依赖。 |
|
提供以独立运行模式启动流程引擎的依赖。 |
|
提供以独立运行模式启动流程引擎,并提供其REST API的依赖。 |
|
提供启动所有Flowable引擎(流程,CMMN,DMN,Form,Content及IDM)的依赖。 |
|
提供启动所有Flowable引擎,并提供其REST API的依赖。 |
|
提供Spring Boot Actuator所需的依赖。 |
5.7.11. 使用Liquibase
Flowable引擎使用Liquibase管理数据库版本。
因此Spring Boot的 LiquibaseAutoConfiguration 会自动启用。
然而,如果你并未使用Liquibase,则应用将无法启动,并抛出异常。
因此Flowable将 spring.liquibase.enabled 设置为 false ,也即如果需要使用Liquibase,则需手动启用它。
5.7.12. 扩展阅读
很明显还有很多Spring Boot相关的内容还没有提及,如非常简单的JTA集成、构建能在主流应用服务器上运行的WAR文件。也还有很多Spring Boot集成:
-
Actuator支持
-
Spring Integration支持
-
Rest API集成:启动Spring应用中嵌入的Flowable Rest API
-
Spring Security支持
5.7.13. 高级配置
自定义引擎配置
实现org.flowable.spring.boot.EngineConfigurationConfigurer<T>接口,可以获取引擎配置对象。其中T是具体引擎配置的Spring类型。 这样可以在参数尚未公开时,进行高级配置,或简化配置。 例如:
public class MyConfigurer implements EngineConfigurationConfigurer<SpringProcessEngineConfiguration> {
public void configure(SpringProcessEngineConfiguration processEngineConfiguration) {
// advanced configuration
}
}在Spring Boot配置中使用@Bean发布该类的实例,这样配置类会在流程引擎创建前调用。
|
可以用这种方法实现自定义的Flowable服务。参见 FlowableLdapAutoConfiguration |
整合starter
如果需要一组引擎,则只能依次添加依赖。 比如要使用流程、CMMN、Form与IDM引擎,并使用LDAP,则需要添加这些依赖:
<dependency>
<groupId>org.flowable</groupId>
<artifactId>flowable-spring-boot-starter-process</artifactId>
<version>${flowable.version}</version>
</dependency>
<dependency>
<groupId>org.flowable</groupId>
<artifactId>flowable-spring-boot-starter-cmmn</artifactId>
<version>${flowable.version}</version>
</dependency>
<dependency>
<groupId>org.flowable</groupId>
<artifactId>flowable-content-spring-configurator</artifactId>
<version>${flowable.version}</version>
</dependency>
<dependency>
<groupId>org.flowable</groupId>
<artifactId>flowable-ldap</artifactId>
<version>${flowable.version}</version>
</dependency>配置异步执行器
流程及CMMN引擎使用专门的 AsyncExecutor ,并可使用 flowable.{engine}.async.executor 参数组进行配置。
其中 engine 代表 process 或 cmmn 。
默认情况下, AsyncExecutor 共享同一个Spring TaskExecutor 及 SpringRejectedJobsHandler 。
如果需要为引擎提供专门的执行器,则需要使用 @Process 及 @Cmmn 定义的bean。
可以使用如下方法配置自定义的执行器:
@Configuration
public class MyConfiguration {
@Process (1)
@Bean
public TaskExecutor processTaskExecutor() {
return new SimpleAsyncTaskExecutor();
}
@Cmmn (2)
@Bean
public TaskExecutor cmmnTaskExecutor() {
return new SyncTaskExecutor();
}
}| 1 | 流程引擎将使用 SimpleAsyncTaskExecutor 作为异步执行器 |
| 2 | CMMN引擎将使用 SyncTaskExecutor 作为异步执行器 |
|
如果使用了自定义的 |
6. 部署
6.1. 业务存档
要部署流程,需要将它们包装在业务存档(BAR, Business archive)里。业务存档是Flowable引擎的部署单元,也就是一个ZIP文件。可以包含BPMN 2.0流程、表单定义、DMN规则,与其他类型的文件。总的来说,业务存档包含一组具名资源。
当部署业务存档时,会扫描具有.bpmn20.xml或.bpmn扩展名的BPMN文件。每一个这种文件都会被处理,并可以包含多个流程定义。
当启用DMN引擎时,也会解析.dmn。当启用表单引擎时,会处理.form文件。
|
业务存档中的Java类不会添加至classpath。业务存档中,所有流程定义使用的自定义类(例如Java服务任务或者事件监听器),都需要放在运行流程的flowable引擎的classpath内。 |
6.1.1. 编程方式部署
从ZIP文件部署业务存档,可以这样做:
String barFileName = "path/to/process-one.bar";
ZipInputStream inputStream = new ZipInputStream(new FileInputStream(barFileName));
repositoryService.createDeployment()
.name("process-one.bar")
.addZipInputStream(inputStream)
.deploy();也可以为单个资源构建部署。查看javadoc以获取更多信息。
6.2. 外部资源
流程定义保存在Flowable数据库中。这些流程定义在使用服务任务、执行监听器,或执行Flowable配置文件中定义的Spring bean时,可以引用委托类。这些类及Spring配置文件都需要在可能运行这个流程定义的流程引擎中可用。
6.2.1. Java类
在流程启动时,引擎的classpath中需要有所有流程中用到的自定义类(例如服务任务、事件监听器、任务监听器等中用到的JavaDelegate)。
但是在部署业务存档时,classpath中可以没有这些类。这意味着,比如使用Ant部署新业务存档时,代理类不必提前放在classpath中。
当使用演示配置且希望添加自定义类时,需要在flowable-task或flowable-rest的webapp lib中,添加包含有你的自定义类的JAR。别忘了也要添加你的自定义类的依赖(若有)。或者,也可以将你的依赖添加到Tomcat的库文件夹${tomcat.home}/lib中。
6.2.2. 在流程中使用Spring bean
在表达式或脚本中使用Spring bean时,执行该流程定义的引擎需要可以使用这些bean。可以简单直接地自行构建web应用,并按照集成Spring章节的介绍在上下文中配置流程引擎。但也请牢记在心,如果使用Flowable task和rest web应用,就需要更新它的上下文配置。
6.2.3. 创建单独应用
如果不想费心在所有流程引擎的classpath中都包含所有需要的代理类,及保证它们都使用了正确的Spring配置,也可以考虑将Flowable rest web应用嵌入你自己的web应用。也就是说只使用一个单独的ProcessEngine。
6.3. 流程定义的版本
BPMN并没有版本的概念。这其实很好,因为可执行的BPMN流程文件很可能已经作为开发项目的一部分,保存在版本管理系统仓库中了(例如Subversion,Git,或者Mercurial)。但是,作为部署过程的一部分,引擎会创建流程定义的版本。在部署时,Flowable会在保存至Flowable数据库前,为ProcessDefinition指定版本。
对于业务存档中的每个流程定义,为了初始化key、version、name与id参数,会执行下列步骤:
-
XML文件中的流程定义
id属性用作流程定义的key参数。 -
XML文件中的流程定义
name属性用作流程定义的name参数。如果未给定name属性,会使用id作为name。 -
当每个key的流程第一次部署时,指定版本为1。对其后所有使用相同key的流程定义,部署时版本会在该key当前已部署的最高版本号基础上加1。key参数用于区分流程定义。
-
id参数设置为{processDefinitionKey}:{processDefinitionVersion}:{generated-id},其中
generated-id是一个唯一数字,用以保证在集群环境下,流程定义缓存中,流程id的唯一性。
以下面的流程为例
<definitions id="myDefinitions" >
<process id="myProcess" name="My important process" >
...当部署这个流程定义时,数据库中的流程定义会是这个样子:
| id | key | name | version |
|---|---|---|---|
myProcess:1:676 |
myProcess |
My important process |
1 |
如果我们现在部署同一个流程的更新版本(例如修改部分用户任务),且保持流程定义的id不变,那么流程定义表中会包含下面的记录:
| id | key | name | version |
|---|---|---|---|
myProcess:1:676 |
myProcess |
My important process |
1 |
myProcess:2:870 |
myProcess |
My important process |
2 |
当调用runtimeService.startProcessInstanceByKey("myProcess")时,会使用版本2的流程定义,因为这是这个流程定义的最新版本。
如果再创建第二个流程,如下定义并部署至Flowable,表中会增加第三行。
<definitions id="myNewDefinitions" >
<process id="myNewProcess" name="My important process" >
...表数据类似:
| id | key | name | version |
|---|---|---|---|
myProcess:1:676 |
myProcess |
My important process |
1 |
myProcess:2:870 |
myProcess |
My important process |
2 |
myNewProcess:1:1033 |
myNewProcess |
My important process |
1 |
请注意新流程的key与第一个流程的key不同。即使name是相同的(我们也可以修改它),Flowable也只用id属性来区分流程。因此新的流程部署时版本为1.
6.4. 提供流程图
可以在部署中添加流程图片。这个图片将存储在Flowable数据库中,并可以使用API访问。图片可以用在Flowable应用中,使流程可视化。
如果在classpath中,有一个org/flowable/expenseProcess.bpmn20.xml流程,key为’expense'。则流程图片会使用下列命名约定(按顺序):
-
如果部署中有图片资源,并且文件名包含BPMN 2.0 XML流程定义文件名以及流程key,并具有图形格式,则使用这个图片。在我们的例子中,就是
org/flowable/expenseProcess.expense.png(或者.jpg/gif)。使用key的原因是,一个BPMN 2.0 XML文件中可以有多个流程定义。因此使用流程key区分每一个流程图的文件。 -
如果没有这种图片,就会寻找部署中匹配BPMN 2.0 XML文件名的图片资源。在我们的例子中,就是
org/flowable/expenseProcess.png。请注意,这意味着同一个BPMN 2.0文件中的每一个流程定义,都会使用同一个流程图图片。当然,如果每个BPMN 2.0 XML文件中都只有一个流程定义,就没有问题。
用编程方式部署的例子:
repositoryService.createDeployment()
.name("expense-process.bar")
.addClasspathResource("org/flowable/expenseProcess.bpmn20.xml")
.addClasspathResource("org/flowable/expenseProcess.png")
.deploy();图片资源可用下面的API获取:
ProcessDefinition processDefinition = repositoryService.createProcessDefinitionQuery()
.processDefinitionKey("expense")
.singleResult();
String diagramResourceName = processDefinition.getDiagramResourceName();
InputStream imageStream = repositoryService.getResourceAsStream(
processDefinition.getDeploymentId(), diagramResourceName);6.5. 生成流程图
如果部署时没有按上小节介绍的方式提供图片,且流程定义中包含必要的“图形交换(diagram interchange)”信息,Flowable引擎会生成流程图。
可以用与部署时提供图片完全相同的方法获取图片资源。
如果不需要或不希望在部署时生成流程图,可以在流程引擎配置中设置isCreateDiagramOnDeploy参数:
<property name="createDiagramOnDeploy" value="false" />这样就不会生成流程图了。
6.6. 类别
部署与流程定义都可以自定义类别。流程定义的类别使用BPMN文件中targetNamespace的值设置:<definitions … targetNamespace="yourCategory" …/>。
部署的类别也可用API如此设定:
repositoryService
.createDeployment()
.category("yourCategory")
...
.deploy();7. BPMN 2.0介绍
7.1. BPMN是什么?
BPMN是一个广泛接受与支持的,展现流程的注记方法。OMG BPMN标准.
7.2. 定义流程
|
本篇文档假设你使用Eclipse IDE创建与编辑文件。但其实文档中只有少数几处使用了Eclipse的特性。你可以使用喜欢的任何其他工具创建BPMN 2.0 XML文件。 |
创建一个新的XML文件(在任意项目上右击,选择New→Other→XML-XML File)并命名。确保该文件名以.bpmn20.xml或.bpmn结尾,否则引擎不会在部署时使用这个文件。
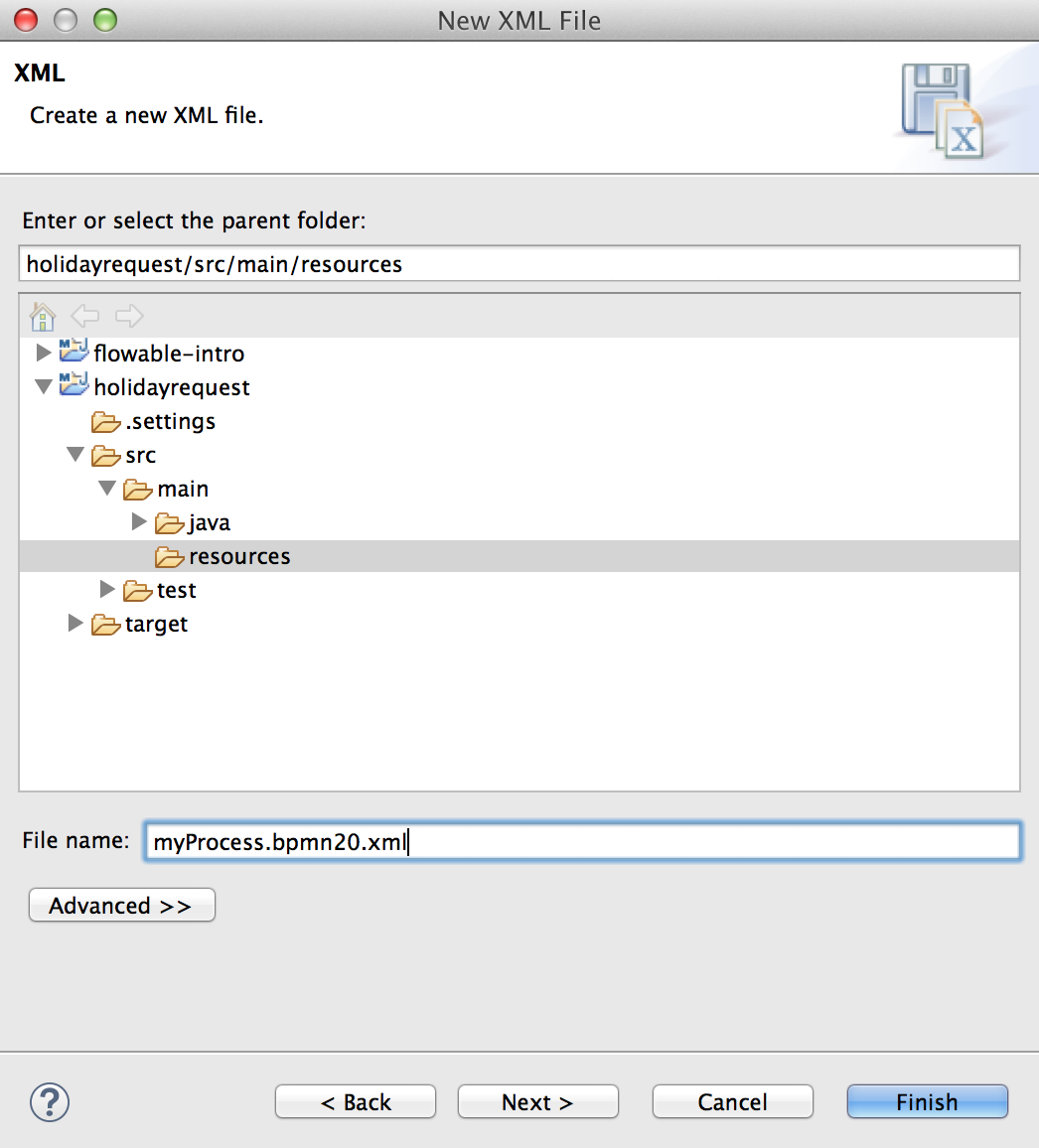
BPMN 2.0概要(schema)的根元素(root element)是definitions元素。在这个元素中,可以定义多个流程定义(然而我们建议在每个文件中,只有一个流程定义。这样可以简化之后的部署过程)。下面给出的是一个空流程定义。请注意definitions元素最少需要包含xmlns与targetNamespace声明。targetNamespace可以为空,它用于对流程定义进行分类。
<definitions
xmlns="http://www.omg.org/spec/BPMN/20100524/MODEL"
xmlns:flowable="http://flowable.org/bpmn"
targetNamespace="Examples">
<process id="myProcess" name="My First Process">
..
</process>
</definitions>除了使用Eclipse中的XML分类选项,也可以使用在线概要作为BPMN 2.0 XML概要。
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.omg.org/spec/BPMN/20100524/MODEL
http://www.omg.org/spec/BPMN/2.0/20100501/BPMN20.xsdprocess元素有两个属性:
-
id: 必填属性,将映射为Flowable
ProcessDefinition对象的key参数。可以使用RuntimeService中的startProcessInstanceByKey方法,使用id来启动这个流程定义的新流程实例。这个方法总会使用流程定义的最新部署版本。
ProcessInstance processInstance = runtimeService.startProcessInstanceByKey("myProcess");-
请注意这与调用
startProcessInstanceById方法不同。startProcessInstanceById方法的参数为Flowable引擎在部署时生成的字符串ID(可以通过调用processDefinition.getId()方法获取)。生成ID的格式为key:version,长度限制为64字符。请注意限制流程key的长度,否则会抛出FlowableException异常,提示生成的ID过长。 -
name: 可选属性,将映射为
ProcessDefinition的name参数。引擎本身不会使用这个参数。可以用于在用户界面上显示更友好的名字。
7.3. 开始:十分钟教程
这个章节包含了一个很简单的业务流程,用于介绍一些基本的Flowable概念以及Flowable API。
7.3.1. 必要条件
这个教程需要你已经运行了Flowable演示配置,并使用独立的H2服务器。编辑db.properties并设置jdbc.url=jdbc:h2:tcp://localhost/flowable,然后按照H2文档的介绍运行独立服务器。
7.3.2. 目标
这个教程的目标是学习Flowable以及BPMN 2.0的一些基础概念。最后成果是一个简单的Java SE程序,部署了一个流程定义,并可以通过Flowable引擎API与流程进行交互。当然,在这个教程里学到的东西,也可以按照你的业务流程用于构建你自己的web应用程序。
7.3.3. 用例
用例很简单:有一个公司,叫做BPMCorp。在BPMCorp中,由会计部门负责,每月需要为投资人撰写一份报告。在报告完成后,需要高层经理中的一人进行审核,然后才能发给所有投资人。

7.3.5. XML格式
这个业务流程的XML版本(FinancialReportProcess.bpmn20.xml)在下面展示。很容易认出流程的主要元素(点击链接可以跳转到BPMN 2.0结构的详细章节):
<definitions id="definitions"
targetNamespace="http://flowable.org/bpmn20"
xmlns:flowable="http://flowable.org/bpmn"
xmlns="http://www.omg.org/spec/BPMN/20100524/MODEL">
<process id="financialReport" name="Monthly financial report reminder process">
<startEvent id="theStart" />
<sequenceFlow id="flow1" sourceRef="theStart" targetRef="writeReportTask" />
<userTask id="writeReportTask" name="Write monthly financial report" >
<documentation>
Write monthly financial report for publication to shareholders.
</documentation>
<potentialOwner>
<resourceAssignmentExpression>
<formalExpression>accountancy</formalExpression>
</resourceAssignmentExpression>
</potentialOwner>
</userTask>
<sequenceFlow id="flow2" sourceRef="writeReportTask" targetRef="verifyReportTask" />
<userTask id="verifyReportTask" name="Verify monthly financial report" >
<documentation>
Verify monthly financial report composed by the accountancy department.
This financial report is going to be sent to all the company shareholders.
</documentation>
<potentialOwner>
<resourceAssignmentExpression>
<formalExpression>management</formalExpression>
</resourceAssignmentExpression>
</potentialOwner>
</userTask>
<sequenceFlow id="flow3" sourceRef="verifyReportTask" targetRef="theEnd" />
<endEvent id="theEnd" />
</process>
</definitions>7.3.6. 启动流程实例
现在我们已经创建了业务流程的流程定义。使用这样的流程定义,可以创建流程实例。在这个例子中,一个流程实例将对应某一月份的财经报告创建与审核工作。所有月份的流程实例共享相同的流程定义。
要用给定的流程定义创建流程实例,需要首先部署(deploy)流程定义。部署流程定义意味着两件事:
-
流程定义将会存储在Flowable引擎配置的持久化数据库中。因此部署业务流程保证了引擎在重启后也能找到流程定义。
-
BPMN 2.0流程XML会解析为内存中的对象模型,供Flowable API使用。
更多关于部署的信息可以在部署章节中找到。
与该章节的描述一样,部署有很多种方式。其中一种是通过下面展示的API。请注意所有与Flowable引擎的交互都要通过它的服务(services)进行。
Deployment deployment = repositoryService.createDeployment()
.addClasspathResource("FinancialReportProcess.bpmn20.xml")
.deploy();现在可以使用在流程定义中定义的id(参见XML中的process元素)启动新流程实例。请注意这个id在Flowable术语中被称作key。
ProcessInstance processInstance = runtimeService.startProcessInstanceByKey("financialReport");这会创建流程实例,并首先通过开始事件。在开始事件后,会沿着所有出口顺序流(在这个例子中只有一个)继续执行,并到达第一个任务(write monthly financial report 撰写月度财务报告)。这时,Flowable引擎会在持久化数据库中存储一个任务。同时也会解析并保存这个任务附加的分配用户或组。请注意,Flowable引擎会持续执行流程,直到到达等待状态(wait state),例如用户任务。在等待状态,流程实例的当前状态会存储在数据库中并保持,直到用户决定完成任务。这时,引擎会继续执行,直到遇到新的等待状态,或者流程结束。如果在这期间引擎重启或崩溃,流程的状态也仍在数据库中安全的保存。
用户任务活动是一个等待状态,因此startProcessInstanceByKey方法会在任务创建后返回。在这个例子里,这个任务分配给一个组。这意味着这个组的每一个成员都是处理这个任务的候选人(candidate)。
现在可以将前面这些东西整合起来,构造一个简单的Java程序。创建一个新的Eclipse项目,在它的classpath中添加Flowable JAR与依赖(可以在Flowable发行版的libs目录下找到)。在调用Flowable服务前,需要首先构建ProcessEngine,用于访问服务。这里我们使用'独立(standalone)'配置,这个配置会构建ProcessEngine,并使用与演示配置中相同的数据库。
public static void main(String[] args) {
// 创建Flowable流程引擎
ProcessEngine processEngine = ProcessEngineConfiguration
.createStandaloneProcessEngineConfiguration()
.buildProcessEngine();
// 获取Flowable服务
RepositoryService repositoryService = processEngine.getRepositoryService();
RuntimeService runtimeService = processEngine.getRuntimeService();
// 部署流程定义
repositoryService.createDeployment()
.addClasspathResource("FinancialReportProcess.bpmn20.xml")
.deploy();
// 启动流程实例
runtimeService.startProcessInstanceByKey("financialReport");
}7.3.7. 任务列表
现在可以通过如下代码获取这个任务:
List<Task> tasks = taskService.createTaskQuery().taskCandidateUser("kermit").list();请注意传递给这个操作的用户需要是accountancy组的成员,因为在流程定义中是这么声明的:
<potentialOwner>
<resourceAssignmentExpression>
<formalExpression>accountancy</formalExpression>
</resourceAssignmentExpression>
</potentialOwner>也可以使用任务查询API,用组名查得相同结果。可以在代码中添加下列逻辑:
TaskService taskService = processEngine.getTaskService();
List<Task> tasks = taskService.createTaskQuery().taskCandidateGroup("accountancy").list();因为我们使用与演示配置中相同的数据库配置ProcessEngine,因此可以直接登录Flowable IDM。使用admin/test登录,创建两个新用户kermit与fozzie,并将Access the workflow application(访问工作流应用)权限授予他们。然后创建两个组,命名为accountancy与management,并将fozzie添加至accountancy组,将kermit添加至management组。
然后以fozzie登录Flowable task应用。选择Task应用,再选择其Processes页面,选择'Monthly financial report (月度财务报告)',这样就可以启动我们的业务流程。
前面已经解释过,流程会执行直到第一个用户任务。因为登录为fozzie,所以可以看到在启动流程实例后,他有一个新的候选任务(candidate task)。选择Task页面来查看这个新任务。请注意即使流程是由其他人启动的,accountancy组中的每一个人仍然都能看到这个候选任务。
7.3.8. 申领任务
会计师(accountancy组的成员)现在需要申领任务(claim)。申领任务后,这个用户会成为任务的执行人(assignee),这个任务也会从accountancy组的其他成员的任务列表中消失。可以通过如下代码实现申领任务:
taskService.claim(task.getId(), "fozzie");这个任务现在在申领任务者的个人任务列表中。
List<Task> tasks = taskService.createTaskQuery().taskAssignee("fozzie").list();在Flowable Task应用中,点击claim按钮会执行相同操作。这个任务会转移到登录用户的个人任务列表中。也可以看到任务执行人变更为当前登录用户。
7.3.9. 完成任务
会计师(accountancy组的成员)现在需要开始撰写财务报告了。完成报告后,他就可以完成任务(complete),代表任务的所有工作都已完成。
taskService.complete(task.getId());对于Flowable引擎来说,这是个外部信号,指示流程实例可以继续执行。Flowable会从运行时数据中移除任务,并沿着这个任务唯一的出口转移线(outgoing transition),将执行移至第二个任务('verification of the report 审核报告')。为第二个任务分配执行人的机制,与上面介绍的第一个任务使用的机制相同。唯一的区别是这个任务会分配给management组。
在演示设置中,完成任务可以通过点击任务列表中的complete按钮。因为Fozzie不是经理,我们需要登出Flowable Task应用,并用kermit(他是经理)登录。这样就可以在未分配任务列表中看到第二个任务。
7.3.10. 结束流程
可以使用与之前完全相同的方式获取并申领审核任务。完成这个第二个任务会将流程执行移至结束事件,并结束流程实例。这个流程实例,及所有相关的运行时执行数据都会从数据库中移除。
也可以通过编程方式,使用historyService验证流程已经结束
HistoryService historyService = processEngine.getHistoryService();
HistoricProcessInstance historicProcessInstance =
historyService.createHistoricProcessInstanceQuery().processInstanceId(procId).singleResult();
System.out.println("Process instance end time: " + historicProcessInstance.getEndTime());7.3.11. 代码总结
将之前章节的所有代码片段整合起来,会得到类似这样的代码。这段代码考虑到了你可能已经使用Flowable UI应用启动了一些流程实例。代码中总是获取任务列表而不是一个任务,因此可以正确执行:
public class TenMinuteTutorial {
public static void main(String[] args) {
// 创建Flowable流程引擎
ProcessEngine processEngine = ProcessEngineConfiguration
.createStandaloneProcessEngineConfiguration()
.buildProcessEngine();
// 获取Flowable服务
RepositoryService repositoryService = processEngine.getRepositoryService();
RuntimeService runtimeService = processEngine.getRuntimeService();
// 部署流程定义
repositoryService.createDeployment()
.addClasspathResource("FinancialReportProcess.bpmn20.xml")
.deploy();
// 启动流程实例
String procId = runtimeService.startProcessInstanceByKey("financialReport").getId();
// 获取第一个任务
TaskService taskService = processEngine.getTaskService();
List<Task> tasks = taskService.createTaskQuery().taskCandidateGroup("accountancy").list();
for (Task task : tasks) {
System.out.println("Following task is available for accountancy group: " + task.getName());
// 申领任务
taskService.claim(task.getId(), "fozzie");
}
// 验证Fozzie获取了任务
tasks = taskService.createTaskQuery().taskAssignee("fozzie").list();
for (Task task : tasks) {
System.out.println("Task for fozzie: " + task.getName());
// 完成任务
taskService.complete(task.getId());
}
System.out.println("Number of tasks for fozzie: "
+ taskService.createTaskQuery().taskAssignee("fozzie").count());
// 获取并申领第二个任务
tasks = taskService.createTaskQuery().taskCandidateGroup("management").list();
for (Task task : tasks) {
System.out.println("Following task is available for management group: " + task.getName());
taskService.claim(task.getId(), "kermit");
}
// 完成第二个任务并结束流程
for (Task task : tasks) {
taskService.complete(task.getId());
}
// 验证流程已经结束
HistoryService historyService = processEngine.getHistoryService();
HistoricProcessInstance historicProcessInstance =
historyService.createHistoricProcessInstanceQuery().processInstanceId(procId).singleResult();
System.out.println("Process instance end time: " + historicProcessInstance.getEndTime());
}
}7.3.12. 后续增强
可以看出这个业务流程太简单了,不能实际使用。但只要继续学习Flowable中可用的BPMN 2.0结构,就可以通过以下元素增强业务流程:
-
定义网关(gateway)使经理可以选择:驳回财务报告,并重新为会计师创建任务;或者接受报告。
-
定义并使用变量(variables)存储或引用报告,并可以在表单中显示它。
-
在流程结束处定义服务任务(service task),将报告发送给每一个投资人。
-
等等。
8. BPMN 2.0结构
本章节介绍Flowable支持的BPMN 2.0结构,以及Flowable对BPMN标准的自定义扩展。
8.1. 自定义扩展
BPMN 2.0标准对流程的所有的参与者都很有用。最终用户不会因为依赖专有解决方案,而被供应商“绑架”。Flowable之类的开源框架,也可以提供与大型供应商的解决方案相同(经常是更好;-)的实现。有了BPMN 2.0标准,从大型供应商解决方案向Flowable的迁移,可以十分简单平滑。
缺点则是标准通常是不同公司(不同观点)大量讨论与妥协的结果。作为阅读BPMN 2.0 XML流程定义的开发者,有时会觉得某些结构或方法十分笨重。Flowable将开发者的感受放在最高优先,因此引入了一些Flowable BPMN扩展(extensions)。这些“扩展”并不在BPMN 2.0规格中,有些是新结构,有些是对特定结构的简化。
尽管BPMN 2.0规格明确指出可以支持自定义扩展,我们仍做了如下保证:
-
自定义扩展保证是在标准方式的基础上进行简化。因此当你决定使用自定义扩展时,不用担心无路可退(仍然可以用标准方式)。
-
使用自定义扩展时,总是通过flowable:命名空间前缀,明确标识出XML元素、属性等。请注意Flowable引擎也支持activiti:命名空间前缀。
因此是否使用自定义扩展,完全取决于你自己。有些其他因素会影响选择(图形化编辑器的使用,公司策略,等等)。我们提供扩展,只是因为相信标准中的某些地方可以用更简单或效率更高的方式处理。请不要吝啬给我们反馈你对扩展的评价(正面的或负面的),也可以给我们提供关于自定义扩展的新想法。说不定某一天,你的想法会成为标准的一部分!
8.2. 事件
事件(event)通常用于为流程生命周期中发生的事情建模。事件总是图形化为圆圈。在BPMN 2.0中,有两种主要的事件分类:捕获(catching)与抛出(throwing)事件。
-
捕获: 当流程执行到达这个事件时,会等待直到触发器动作。触发器的类型由其中的图标,或者说XML中的类型声明而定义。捕获事件与抛出事件显示上的区别,是其内部的图标没有填充(即是白色的)。
-
抛出: 当流程执行到达这个事件时,会触发一个触发器。触发器的类型,由其中的图标,或者说XML中的类型声明而定义。抛出事件与捕获事件显示上的区别,是其内部的图标填充为黑色。
8.2.1. 事件定义
事件定义(event definition),用于定义事件的语义。没有事件定义的话,事件就“不做什么特别的事情”。例如,一个没有事件定义的开始事件,并不限定具体是什么启动了流程。如果为这个开始事件添加事件定义(例如定时器事件定义),就声明了启动流程的“类型”(例如对于定时器事件定义,就是到达了特定的时间点)。
8.2.2. 定时器事件定义
定时器事件(timer event definition),是由定时器所触发的事件。可以用于开始事件,中间事件,或边界事件。定时器事件的行为取决于所使用的业务日历(business calendar)。定时器事件有默认的业务日历,但也可以为每个定时器事件定义,单独定义业务日历。
<timerEventDefinition flowable:businessCalendarName="custom">
...
</timerEventDefinition>其中businessCalendarName指向流程引擎配置中的业务日历。如果省略业务日历定义,则使用默认业务日历。
定时器定义必须且只能包含下列的一种元素:
-
timeDate。这个元素指定了ISO 8601格式的固定时间。在这个时间就会触发触发器。例如:
<timerEventDefinition>
<timeDate>2011-03-11T12:13:14</timeDate>
</timerEventDefinition>-
timeDuration。要定义定时器需要等待多长时间再触发,可以用timerEventDefinition的子元素timeDuration。使用ISO 8601格式(BPMN 2.0规范要求)。例如(等待10天):
<timerEventDefinition>
<timeDuration>P10D</timeDuration>
</timerEventDefinition><timerEventDefinition>
<timeCycle flowable:endDate="2015-02-25T16:42:11+00:00">R3/PT10H</timeCycle>
</timerEventDefinition><timerEventDefinition>
<timeCycle>R3/PT10H/${EndDate}</timeCycle>
</timerEventDefinition>如果同时使用了两种格式,则系统会使用以属性方式定义的endDate。
目前只有BoundaryTimerEvents与CatchTimerEvent可以使用EndDate。
另外,也可以使用cron表达式指定定时周期。下面的例子展示了一个整点启动,每5分钟触发的触发器:
0 0/5 * * * ?
请参考这个教程了解如何使用cron表达式。
请注意: 与普通的Unix cron不同,第一个符号代表的是秒,而不是分钟。
重复时间周期更适合使用相对时间,也就是从某个特定时间点开始计算(比如用户任务开始的时间)。而cron表达式可以使用绝对时间,因此更适合用于定时启动事件。
可以在定时事件定义中使用表达式,也就是使用流程变量控制定时。这个流程变量必须是包含合适时间格式的字符串,ISO 8601(或者对于循环类型,cron)。
<boundaryEvent id="escalationTimer" cancelActivity="true" attachedToRef="firstLineSupport">
<timerEventDefinition>
<timeDuration>${duration}</timeDuration>
</timerEventDefinition>
</boundaryEvent>请注意:定时器只有在异步执行器启用时才能触发(需要在flowable.cfg.xml中,将asyncExecutorActivate设置为true。因为默认情况下异步执行器都是禁用的)。
8.2.3. 错误事件定义
(error event definition)
重要提示: BPMN错误与Java异常不是一回事。事实上,这两者毫无共同点。BPMN错误事件是建模业务异常(business exceptions)的方式。而Java异常会按它们自己的方式处理。
<endEvent id="myErrorEndEvent">
<errorEventDefinition errorRef="myError" />
</endEvent>8.2.4. 信号事件定义
信号事件(signal event),是引用具名信号的事件。信号是全局范围(广播)的事件,并会被传递给所有激活的处理器(等待中的流程实例/捕获信号事件 catching signal events)。
使用signalEventDefinition元素声明信号事件定义。其signalRef属性引用一个signal元素,该signal元素需要声明为definitions根元素的子元素。下面摘录一个流程,使用中间事件(intermediate event)抛出与捕获信号事件。
<definitions... >
<!-- 声明信号 -->
<signal id="alertSignal" name="alert" />
<process id="catchSignal">
<intermediateThrowEvent id="throwSignalEvent" name="Alert">
<!-- 信号事件定义 -->
<signalEventDefinition signalRef="alertSignal" />
</intermediateThrowEvent>
...
<intermediateCatchEvent id="catchSignalEvent" name="On Alert">
<!-- 信号事件定义 -->
<signalEventDefinition signalRef="alertSignal" />
</intermediateCatchEvent>
...
</process>
</definitions>两个signalEventDefinition引用同一个signal元素。
抛出信号事件
信号可以由流程实例使用BPMN结构抛出(throw),也可以通过编程方式使用Java API抛出。下面org.flowable.engine.RuntimeService中的方法可以用编程方式抛出信号:
RuntimeService.signalEventReceived(String signalName);
RuntimeService.signalEventReceived(String signalName, String executionId);signalEventReceived(String signalName)与signalEventReceived(String signalName, String executionId)的区别,是前者在全局范围为所有已订阅处理器抛出信号(广播),而后者只为指定的执行传递信号。
捕获信号事件
可以使用信号捕获中间事件(intermediate catch signal event)或者信号边界事件(signal boundary event)捕获信号事件。
查询信号事件订阅
可以查询订阅了某一信号事件的所有执行:
List<Execution> executions = runtimeService.createExecutionQuery()
.signalEventSubscriptionName("alert")
.list();可以使用signalEventReceived(String signalName, String executionId)方法为这些执行传递这个信号。
信号事件的范围
默认情况下,信号事件在流程引擎全局广播。这意味着你可以在一个流程实例中抛出一个信号事件,而不同流程定义的不同流程实例都会响应这个事件。
但有时也会希望只在同一个流程实例中响应信号事件。例如,在流程实例中使用异步机制,而两个或多个活动彼此互斥的时候。
要限制信号事件的范围(scope),在信号事件定义中添加(非BPMN 2.0标准!)scope属性:
<signal id="alertSignal" name="alert" flowable:scope="processInstance"/>这个属性的默认值为"global(全局)"。
信号事件示例
下面是一个不同流程通过信号通信的例子。第一个流程在保险政策更新或变更时启动。在变更由人工审核之后,会抛出信号事件,指出政策已经发生了变更:
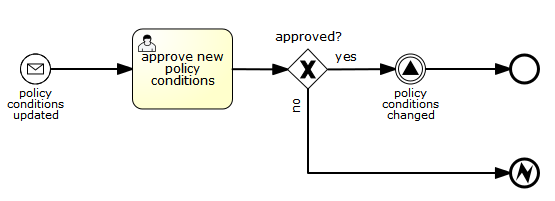
这个事件可以被所有感兴趣的流程实例捕获。下面是一个订阅这个事件的流程的例子。
请注意:要理解信号事件会广播给所有激活的处理器,这很重要。这意味着在上面的例子中,所有订阅这个信号的流程实例都会接收这个信号。在这个例子中这就是我们期望的。然而,有的情况下,不希望使用广播方式。考虑下面的流程:

Flowable不支持上面流程中描述的模式。我们的想法是,在执行"do something"任务时抛出的错误,由错误边界事件捕获,并通过信号抛出事件传播至执行的并行分支,最终中断"do something in parallel"任务。到目前为止Flowable会按照预期效果执行。然而,由于信号的广播效应,它也会被传播至所有其他订阅了这个信号事件的流程实例。这可能并非我们希望的效果。
请注意:信号事件与特定的流程实例无关,而是会广播给所有流程实例。如果你需要只为某一特定的流程实例传递信号,则需要使用signalEventReceived(String signalName, String executionId)手动建立关联,并使用适当的的查询机制。
Flowable提供了解决的方法。可以在信号事件上添加scope属性,并将其设置为processInstance。
8.2.5. 消息事件定义
消息事件(message event),是指引用具名消息的事件。消息具有名字与载荷。与信号不同,消息事件只有一个接收者。
消息事件定义使用messageEventDefinition元素声明。其messageRef属性引用一个message元素,该message元素需要声明为definitions根元素的子元素。下面摘录一个流程,声明了两个消息事件,并由开始事件与消息捕获中间事件(intermediate catching message event)引用。
<definitions id="definitions"
xmlns="http://www.omg.org/spec/BPMN/20100524/MODEL"
xmlns:flowable="http://flowable.org/bpmn"
targetNamespace="Examples"
xmlns:tns="Examples">
<message id="newInvoice" name="newInvoiceMessage" />
<message id="payment" name="paymentMessage" />
<process id="invoiceProcess">
<startEvent id="messageStart" >
<messageEventDefinition messageRef="newInvoice" />
</startEvent>
...
<intermediateCatchEvent id="paymentEvt" >
<messageEventDefinition messageRef="payment" />
</intermediateCatchEvent>
...
</process>
</definitions>抛出消息事件
作为嵌入式的流程引擎,Flowable并不关心实际如何接收消息。因为这可能与环境相关,或需要进行平台定义的操作。例如连接至JMS(Java Messaging Service,Java消息服务)队列(Queue)/主题(Topic),或者处理Webservice或者REST请求。因此接收消息需要作为应用的一部分,或者是流程引擎所嵌入的基础框架中的一部分,由你自行实现。
在应用中接收到消息后,需要决定如何处理它。如果这个消息需要启动新的流程实例,可以选择一种由runtime服务提供的方法:
ProcessInstance startProcessInstanceByMessage(String messageName);
ProcessInstance startProcessInstanceByMessage(String messageName, Map<String, Object> processVariables);
ProcessInstance startProcessInstanceByMessage(String messageName, String businessKey,
Map<String, Object> processVariables);这些方法使用消息启动流程实例。
如果需要由已有的流程实例接收消息,需要首先将消息与特定的流程实例关联(查看后续章节),然后触发等待中的执行,让流程继续进行。runtime服务提供了下列方法,可以触发订阅了消息事件的执行:
void messageEventReceived(String messageName, String executionId);
void messageEventReceived(String messageName, String executionId, HashMap<String, Object> processVariables);查询消息事件订阅
-
对于消息启动事件(message start event),消息事件的订阅与的流程定义相关。可以使用
ProcessDefinitionQuery查询这种类型的消息订阅:
ProcessDefinition processDefinition = repositoryService.createProcessDefinitionQuery()
.messageEventSubscription("newCallCenterBooking")
.singleResult();因为一个消息只能被一个流程定义订阅,因此这个查询总是返回0或1个结果。如果流程定义更新了,只有该流程定义的最新版本会订阅这个消息事件。
-
对于消息捕获中间事件(intermediate catch message event),消息事件的订阅与执行相关。可以使用
ExecutionQuery查询这种类型的消息订阅:
Execution execution = runtimeService.createExecutionQuery()
.messageEventSubscriptionName("paymentReceived")
.variableValueEquals("orderId", message.getOrderId())
.singleResult();这种查询通常都会有关联查询,并且通常需要了解流程的情况(在这个例子里,对于给定的orderId,至多只有一个流程实例)。
消息事件示例
下面是一个流程的例子,可以使用两种不同的消息启动:
在流程需要通过不同的方式启动,但是后续使用统一的方式处理时,就可以使用这种方法。
8.2.6. 启动事件
启动事件(start event)是流程的起点。启动事件的类型(流程在消息到达时启动,在指定的时间间隔后启动,等等),定义了流程如何启动,并显示为启动事件中的小图标。在XML中,类型由子元素声明来定义。
启动事件随时捕获:启动事件(保持)等候,直到特定的触发器被触发。
在启动事件中,可以使用下列Flowable自定义参数:
-
initiator: 指明保存认证用户(authenticated user)ID用的变量名。在流程启动时,操作用户的ID会保存在这个变量中。例如:
<startEvent id="request" flowable:initiator="initiator" />认证用户必须在try-finally块中调用IdentityService.setAuthenticatedUserId(String)方法进行设置。像这样:
try {
identityService.setAuthenticatedUserId("bono");
runtimeService.startProcessInstanceByKey("someProcessKey");
} finally {
identityService.setAuthenticatedUserId(null);
}这段代码已经集成在Flowable应用中,可以在表单中使用。
8.2.7. 空启动事件
描述
“空”启动事件(none Start Event),指的是未指定启动流程实例触发器的启动事件。引擎将无法预知何时启动流程实例。空启动事件用于流程实例通过调用下列startProcessInstanceByXXX API方法启动的情况。
ProcessInstance processInstance = runtimeService.startProcessInstanceByXXX();请注意:子流程(sub-process)必须有空启动事件。
图示
空启动事件用空心圆圈表示,中间没有图标(也就是说,没有触发器)。
XML表示
空启动事件的XML表示格式,就是普通的启动事件声明,而没有任何子元素(其他种类的启动事件都有用于声明其类型的子元素)。
<startEvent id="start" name="my start event" />空启动事件的自定义扩展
formKey: 引用表单定义,用户需要在启动新流程实例时填写该表单。可以在表单章节找到更多信息。例如:
<startEvent id="request" flowable:formKey="request" />8.2.8. 定时器启动事件
描述
定时器启动事件(timer start event)在指定时间创建流程实例。在流程只需要启动一次,或者流程需要在特定的时间间隔重复启动时,都可以使用。
请注意:子流程不能有定时器启动事件。
请注意:定时器启动事件,在流程部署的同时就开始计时。不需要调用startProcessInstanceByXXX就会在时间启动。调用startProcessInstanceByXXX时会在定时启动之外额外启动一个流程。
请注意:当部署带有定时器启动事件的流程的更新版本时,上一版本的定时器作业会被移除。这是因为通常并不希望旧版本的流程仍然自动启动新的流程实例。
图示
定时器启动事件,用其中有一个钟表图标的圆圈来表示。
XML表示
定时器启动事件的XML表示格式,是普通的启动事件声明加上定时器定义子元素。请参考定时器定义了解详细配置方法。
示例:流程会启动4次,间隔5分钟,从2011年3月11日,12:13开始
<startEvent id="theStart">
<timerEventDefinition>
<timeCycle>R4/2011-03-11T12:13/PT5M</timeCycle>
</timerEventDefinition>
</startEvent>示例:流程会在设定的时间启动一次
<startEvent id="theStart">
<timerEventDefinition>
<timeDate>2011-03-11T12:13:14</timeDate>
</timerEventDefinition>
</startEvent>8.2.9. 消息启动事件
描述
消息启动事件(message start event)使用具名消息启动流程实例。消息名用于选择正确的启动事件。
当部署具有一个或多个消息启动事件的流程定义时,会做如下判断:
-
给定流程定义中,消息启动事件的名字必须是唯一的。一个流程定义不得包含多个同名的消息启动事件。如果流程定义中有两个或多个消息启动事件引用同一个消息,或者两个或多个消息启动事件引用了具有相同消息名字的消息,则Flowable会在部署这个流程定义时抛出异常。
-
在所有已部署的流程定义中,消息启动事件的名字必须是唯一的。如果在流程定义中,一个或多个消息启动事件引用了已经部署的另一流程定义中消息启动事件的消息名,则Flowable会在部署这个流程定义时抛出异常。
-
流程版本:在部署流程定义的新版本时,会取消上一版本的消息订阅,即使新版本中并没有这个消息事件)。
在启动流程实例时,可以使用下列RuntimeService中的方法,触发消息启动事件:
ProcessInstance startProcessInstanceByMessage(String messageName);
ProcessInstance startProcessInstanceByMessage(String messageName, Map<String, Object> processVariables);
ProcessInstance startProcessInstanceByMessage(String messageName, String businessKey,
Map<String, Object< processVariables);messageName是由message元素的name属性给定的名字。messageEventDefinition的messageRef属性会引用message元素。当启动流程实例时,会做如下判断:
-
只有顶层流程(top-level process)才支持消息启动事件。嵌入式子流程不支持消息启动事件。
-
如果一个流程定义中有多个消息启动事件,可以使用
runtimeService.startProcessInstanceByMessage(…)选择合适的启动事件。 -
如果一个流程定义中有多个消息启动事件与一个空启动事件,则
runtimeService.startProcessInstanceByKey(…)与runtimeService.startProcessInstanceById(…)会使用空启动事件启动流程实例。 -
如果一个流程定义中有多个消息启动事件而没有空启动事件,则
runtimeService.startProcessInstanceByKey(…)与runtimeService.startProcessInstanceById(…)会抛出异常。 -
如果一个流程定义中只有一个消息启动事件,则
runtimeService.startProcessInstanceByKey(…)与runtimeService.startProcessInstanceById(…)会使用这个消息启动事件启动新流程实例。 -
如果流程由调用活动(call activity)启动,则只有在下列情况下才支持消息启动事件
-
除了消息启动事件之外,流程还有唯一的空启动事件
-
或者流程只有唯一的消息启动事件,而没有其他启动事件。
-
图示
消息启动事件用其中有一个消息事件标志的圆圈表示。这个标志并未填充,用以表示捕获(接收)行为。
XML表示
消息启动事件的XML表示格式,为普通启动事件声明加上messageEventDefinition子元素:
<definitions id="definitions"
xmlns="http://www.omg.org/spec/BPMN/20100524/MODEL"
xmlns:flowable="http://flowable.org/bpmn"
targetNamespace="Examples"
xmlns:tns="Examples">
<message id="newInvoice" name="newInvoiceMessage" />
<process id="invoiceProcess">
<startEvent id="messageStart" >
<messageEventDefinition messageRef="tns:newInvoice" />
</startEvent>
...
</process>
</definitions>8.2.10. 信号启动事件
描述
信号启动事件(signal start event),使用具名信号启动流程实例。这个信号可以由流程实例中的信号抛出中间事件(intermediary signal throw event),或者API(runtimeService.signalEventReceivedXXX方法)触发。两种方式都会启动所有拥有相同名字信号启动事件的流程定义。
请注意可以选择异步还是同步启动流程实例。
需要为API传递的signalName,是由signal元素的name属性决定的名字。signal元素由signalEventDefinition的signalRef属性引用。
图示
信号启动事件用其中有一个信号事件标志的圆圈表示。这个标志并未填充,用以表示捕获(接收)行为。
XML表示
信号启动事件的XML表示格式,为普通启动事件声明,加上signalEventDefinition子元素:
<signal id="theSignal" name="The Signal" />
<process id="processWithSignalStart1">
<startEvent id="theStart">
<signalEventDefinition id="theSignalEventDefinition" signalRef="theSignal" />
</startEvent>
<sequenceFlow id="flow1" sourceRef="theStart" targetRef="theTask" />
<userTask id="theTask" name="Task in process A" />
<sequenceFlow id="flow2" sourceRef="theTask" targetRef="theEnd" />
<endEvent id="theEnd" />
</process>8.2.11. 错误启动事件
图示
错误启动事件用其中有一个错误事件标志的圆圈表示。这个标志并未填充,用以表示捕获(接收)行为。
XML表示
错误启动事件的XML表示格式,为普通启动事件声明加上errorEventDefinition子元素:
<startEvent id="messageStart" >
<errorEventDefinition errorRef="someError" />
</startEvent>8.2.12. 结束事件
结束事件(end event)标志着流程或子流程中一个分支的结束。结束事件总是抛出(型)事件。这意味着当流程执行到达结束事件时,会抛出一个结果。结果的类型由事件内部的黑色图标表示。在XML表示中,类型由子元素声明给出。
8.2.13. 空结束事件
描述
“空”结束事件(none end event),意味着当到达这个事件时,没有特别指定抛出的结果。因此,引擎除了结束当前执行分支之外,不会多做任何事情。
图示
空结束事件,用其中没有图标(没有结果类型)的粗圆圈表示。
XML表示
空事件的XML表示格式为普通结束事件声明,没有任何子元素(其它种类的结束事件都有子元素,用于声明其类型)。
<endEvent id="end" name="my end event" />8.2.14. 错误结束事件
描述
当流程执行到达错误结束事件(error end event)时,结束执行的当前分支,并抛出错误。这个错误可以由匹配的错误边界中间事件捕获。如果找不到匹配的错误边界事件,将会抛出异常。
图示
错误结束事件事件用内部有一个错误图标的标准结束事件(粗圆圈)表示。错误图标是全黑的,代表抛出的含义。
XML表示
错误结束事件表示为结束事件,加上errorEventDefinition子元素:
<endEvent id="myErrorEndEvent">
<errorEventDefinition errorRef="myError" />
</endEvent>errorRef属性可以引用在流程外定义的error元素:
<error id="myError" errorCode="123" />
...
<process id="myProcess">
...error的errorCode用于查找匹配的错误捕获边界事件。如果errorRef不匹配任何已定义的error,则该errorRef会用做errorCode的快捷方式。这个快捷方式是Flowable特有的。下面的代码片段在功能上是相同的。
<error id="myError" errorCode="error123" />
...
<process id="myProcess">
...
<endEvent id="myErrorEndEvent">
<errorEventDefinition errorRef="myError" />
</endEvent>
...与下面的代码功能相同
<endEvent id="myErrorEndEvent">
<errorEventDefinition errorRef="error123" />
</endEvent>请注意errorRef必须遵从BPMN 2.0概要(schema),且必须是合法的QName。
8.2.15. 终止结束事件
描述
当到达终止结束事件(terminate end event)时,当前的流程实例或子流程会被终止。也就是说,当执行到达终止结束事件时,会判断第一个范围 scope(流程或子流程)并终止它。请注意在BPMN 2.0中,子流程可以是嵌入式子流程,调用活动,事件子流程,或事务子流程。有一条通用规则:当存在多实例的调用过程或嵌入式子流程时,只会终止一个实例,其他的实例与流程实例不会受影响。
可以添加一个可选属性terminateAll。当其为true时,无论该终止结束事件在流程定义中的位置,也无论它是否在子流程(甚至是嵌套子流程)中,都会终止(根)流程实例。
图示
终止结束事件用内部有一个全黑圆的标准结束事件(粗圆圈)表示。

XML表示
终止结束事件,表示为结束事件,加上terminateEventDefinition子元素。
请注意terminateAll属性是可选的(默认为false)。
<endEvent id="myEndEvent >
<terminateEventDefinition flowable:terminateAll="true"></terminateEventDefinition>
</endEvent>8.2.16. 取消结束事件
描述
取消结束事件(cancel end event)只能与BPMN事务子流程(BPMN transaction subprocess)一起使用。当到达取消结束事件时,会抛出取消事件,且必须由取消边界事件(cancel boundary event)捕获。取消边界事件将取消事务,并触发补偿(compensation)。
图示
取消结束事件用内部有一个取消图标的标准结束事件(粗圆圈)表示。取消图标是全黑的,代表抛出的含义。

XML表示
取消结束事件,表示为结束事件,加上cancelEventDefinition子元素。
<endEvent id="myCancelEndEvent">
<cancelEventDefinition />
</endEvent>8.2.17. 边界事件
边界事件(boundary event)是捕获型事件,依附在活动(activity)上。边界事件永远不会抛出。这意味着当活动运行时,事件将监听特定类型的触发器。当捕获到事件时,会终止活动,并沿该事件的出口顺序流继续。
所有的边界事件都用相同的方式定义:
<boundaryEvent id="myBoundaryEvent" attachedToRef="theActivity">
<XXXEventDefinition/>
</boundaryEvent>边界事件由下列元素定义:
-
(流程范围内)唯一的标识符
-
由attachedToRef属性定义的,对该事件所依附的活动的引用。请注意边界事件及其所依附的活动,应定义在相同级别(也就是说,边界事件并不包含在活动内)。
-
定义了边界事件的类型的,形如XXXEventDefinition的XML子元素(例如TimerEventDefinition,ErrorEventDefinition,等等)。查阅特定的边界事件类型,以了解更多细节。
8.2.18. 定时器边界事件
描述
定时器边界事件(timer boundary event)的行为像是跑表与闹钟。当执行到达边界事件所依附的活动时,将启动定时器。当定时器触发时(例如在特定时间间隔后),可以中断活动,并沿着边界事件的出口顺序流继续执行。
图示
定时器边界事件用内部有一个定时器图标的标准边界事件(圆圈)表示。
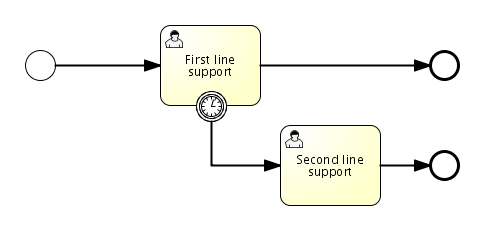
XML表示
定时器边界事件与一般边界事件一样定义。其中类型子元素为timerEventDefinition元素。
<boundaryEvent id="escalationTimer" cancelActivity="true" attachedToRef="firstLineSupport">
<timerEventDefinition>
<timeDuration>PT4H</timeDuration>
</timerEventDefinition>
</boundaryEvent>请参考定时器事件定义了解定时器配置的细节。
在图示中圆圈画为虚线,如下:
中断与非中断定时器事件是不同的。非中断意味着最初的活动不会被中断,而会保持原样。默认为中断行为。在XML表示中,cancelActivity属性设置为false。
一个典型使用场景,是在一段时间之后发送提醒邮件,但不影响正常的流程流向。
<boundaryEvent id="escalationTimer" cancelActivity="false" attachedToRef="firstLineSupport"/>请注意:定时器边界事件只有在异步执行器(async executor)启用时才能触发(也就是说,需要在flowable.cfg.xml中,将asyncExecutorActivate设置为true。因为异步执行器默认情况下是禁用的。)
边界事件的已知问题
所有类型的边界事件,都有一个关于并发的已知问题:不能在边界事件上附加多个出口顺序流。这个问题的解决方案,是使用一条出口顺序流,指向并行网关。
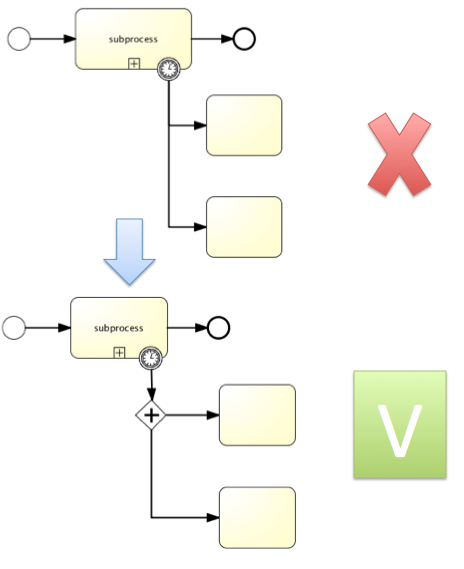
8.2.19. 错误边界事件
描述
在活动边界上的错误捕获中间(事件),或简称错误边界事件(error boundary event),捕获其所依附的活动范围内抛出的错误。
在嵌入式子流程或者调用活动上定义错误边界事件最有意义,因为子流程的范围会包括其中的所有活动。错误可以由错误结束事件抛出。这样的错误会逐层向其上级父范围传播,直到在范围内找到一个匹配错误事件定义的错误边界事件。
当捕获错误事件时,会销毁边界事件定义所在的活动,同时销毁其中所有的当前执行(例如,并行活动,嵌套子流程,等等)。流程执行将沿着边界事件的出口顺序流继续。
图示
错误边界事件用内部有一个错误图标的标准中间事件(两层圆圈)表示。错误图标是白色的,代表捕获的含义。
XML表示
错误边界事件与标准边界事件一样定义:
<boundaryEvent id="catchError" attachedToRef="mySubProcess">
<errorEventDefinition errorRef="myError"/>
</boundaryEvent>在边界事件中,errorRef引用一个流程元素外定义的错误:
<error id="myError" errorCode="123" />
...
<process id="myProcess">
...errorCode用于匹配捕获的错误:
-
如果省略了errorRef,错误边界事件会捕获所有错误事件,无论error的errorCode是什么。
-
如果提供了errorRef,并且其引用了存在的error,则边界事件只会捕获相同错误代码的错误。
-
如果提供了errorRef,但BPMN 2.0文件中没有定义error,则errorRef会用作errorCode(与错误结束事件类似)。
示例
下面的示例流程展示了如何使用错误结束事件。当'Review profitability (审核盈利能力)'用户任务完成,并指出提供的信息不足时,会抛出错误。当这个错误被子流程边界捕获时,'Review sales lead (审核销售线索)'子流程中的所有运行中活动都会被销毁(即使'Review customer rating 审核客户等级'还没有完成),并会创建'Provide additional details (提供更多信息)'用户任务。
这个流程作为演示配置的示例提供。可以在org.flowable.examples.bpmn.event.error包中找到流程XML与单元测试。
8.2.20. 信号边界事件
描述
依附在活动边界上的信号捕获中间(事件),或简称信号边界事件(signal boundary event),捕获与其信号定义具有相同名称的信号。
请注意:与其他事件例如错误边界事件不同的是,信号边界事件不只是捕获其所依附范围抛出的信号。信号边界事件为全局范围(广播)的,意味着信号可以从任何地方抛出,甚至可以是不同的流程实例。
请注意:与其他事件(如错误事件)不同,信号在被捕获后不会被消耗。如果有两个激活的信号边界事件,捕获相同的信号事件,则两个边界事件都会被触发,哪怕它们不在同一个流程实例里。
图示
信号边界事件,用内部有一个信号图标的标准中间事件(两层圆圈)表示。信号图标是白色的,代表捕获的含义。
XML表示
信号边界事件与标准边界事件一样定义:
<boundaryEvent id="boundary" attachedToRef="task" cancelActivity="true">
<signalEventDefinition signalRef="alertSignal"/>
</boundaryEvent>示例
参见信号事件定义章节。
8.2.21. 消息边界事件
描述
在活动边界上的消息捕获中间(事件),或简称消息边界事件(message boundary event),捕获与其消息定义具有相同消息名的消息。
图示
消息边界事件,用内部有一个消息图标的标准中间事件(两层圆圈)表示。信号图标是白色的,代表捕获的含义。
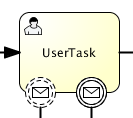
请注意消息边界事件既可以是中断型的(右图),也可以是非中断型的(左图)。
XML表示
消息边界事件与标准边界事件一样定义:
<boundaryEvent id="boundary" attachedToRef="task" cancelActivity="true">
<messageEventDefinition messageRef="newCustomerMessage"/>
</boundaryEvent>示例
参见消息事件定义章节。
8.2.22. 取消边界事件
描述
依附在事务子流程边界上的取消捕获中间事件,或简称取消边界事件(cancel boundary event),在事务取消时触发。当取消边界事件触发时,首先会中断当前范围的所有活动执行。接下来,启动事务范围内所有有效的的补偿边界事件(compensation boundary event)。补偿会同步执行,也就是说在离开事务前,边界事件会等待补偿完成。当补偿完成时,沿取消边界事件的任何出口顺序流离开事务子流程。
请注意:一个事务子流程只允许使用一个取消边界事件。
请注意:如果事务子流程中有嵌套的子流程,只会对成功完成的子流程触发补偿。
请注意:如果取消边界事件放置在具有多实例特性的事务子流程上,如果一个实例触发了取消,则边界事件将取消所有实例。
图示
取消边界事件,用内部有一个取消图标的标准中间事件(两层圆圈)表示。取消图标是白色的(未填充),代表捕获的含义。
XML表示
取消边界事件与标准边界事件一样定义:
<boundaryEvent id="boundary" attachedToRef="transaction" >
<cancelEventDefinition />
</boundaryEvent>因为取消边界事件总是中断型的,因此没有cancelActivity属性。
8.2.23. 补偿边界事件
描述
依附在活动边界上的补偿捕获中间(事件),或简称补偿边界事件(compensation boundary event),可以为活动附加补偿处理器。
补偿边界事件必须使用直接关联的方式引用单个的补偿处理器。
补偿边界事件与其它边界事件的活动策略不同。其它边界事件,例如信号边界事件,在其依附的活动启动时激活;当该活动结束时会被解除,并取消相应的事件订阅。而补偿边界事件不是这样。补偿边界事件在其依附的活动成功完成时激活,同时创建补偿事件的相应订阅。当补偿事件被触发,或者相应的流程实例结束时,才会移除订阅。请考虑下列因素:
-
当补偿被触发时,会调用补偿边界事件关联的补偿处理器。调用次数与其依附的活动成功完成的次数相同。
-
如果补偿边界事件依附在具有多实例特性的活动上,则会为每一个实例创建补偿事件订阅。
-
如果补偿边界事件依附在位于循环内部的活动上,则每次该活动执行时,都会创建一个补偿事件订阅。
-
如果流程实例结束,则取消补偿事件的订阅。
请注意:嵌入式子流程不支持补偿边界事件。
图示
补偿边界事件,用内部有一个补偿图标的标准中间事件(两层圆圈)表示。补偿图标是白色的(未填充),代表捕获的含义。另外,补偿边界事件使用单向连接关联补偿处理器,如下图所示:
XML表示
补偿边界事件与标准边界事件一样定义:
<boundaryEvent id="compensateBookHotelEvt" attachedToRef="bookHotel" >
<compensateEventDefinition />
</boundaryEvent>
<association associationDirection="One" id="a1"
sourceRef="compensateBookHotelEvt" targetRef="undoBookHotel" />
<serviceTask id="undoBookHotel" isForCompensation="true" flowable:class="..." />补偿边界事件在活动完成后才激活,因此不支持cancelActivity属性。
8.2.24. 捕获中间事件
所有的捕获中间事件(intermediate catching events)都使用相同方式定义:
<intermediateCatchEvent id="myIntermediateCatchEvent" >
<XXXEventDefinition/>
</intermediateCatchEvent>捕获中间事件由下列元素定义:
-
(流程范围内)唯一的标识符
-
定义了捕获中间事件类型的,形如XXXEventDefinition的XML子元素(例如TimerEventDefinition等)。查阅特定中间捕获事件类型,以了解更多细节。
8.2.25. 定时器捕获中间事件
描述
定时器捕获中间事件(timer intermediate catching event)的行为像是跑表。当执行到达捕获事件时,启动定时器;当定时器触发时(例如在一段时间间隔后),沿定时器中间事件的出口顺序流继续执行。
图示
定时器中间事件用内部有定时器图标的中间捕获事件表示。
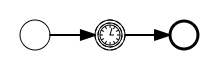
8.2.26. 信号捕获中间事件
描述
信号捕获中间事件(signal intermediate catching event),捕获与其引用的信号定义具有相同信号名称的信号。
请注意:与其他事件如错误事件不同,信号在被捕获后不会被消耗。如果有两个激活的信号中间事件,捕获相同的信号事件,则两个中间事件都会被触发,哪怕它们不在同一个流程实例里。
图示
信号捕获中间事件用内部有信号图标的标准中间事件(两层圆圈)表示。信号图标是白色的(未填充),代表捕获的含义。
XML表示
信号中间事件与捕获中间事件一样定义。子元素为signalEventDefinition。
<intermediateCatchEvent id="signal">
<signalEventDefinition signalRef="newCustomerSignal" />
</intermediateCatchEvent>示例
参阅信号事件定义章节。
8.2.27. 消息捕获中间事件
描述
消息捕获中间事件(message intermediate catching event),捕获特定名字的消息。
图示
消息捕获中间事件用内部有消息图标的标准中间事件(两层圆圈)表示。消息图标是白色的(未填充),代表捕获的含义。

XML表示
消息中间事件与捕获中间事件一样定义。子元素为messageEventDefinition。
<intermediateCatchEvent id="message">
<messageEventDefinition signalRef="newCustomerMessage" />
</intermediateCatchEvent>示例
参阅消息事件定义章节。
8.2.28. 抛出中间事件
所有的抛出中间事件(intermediate throwing evnet)都使用相同方式定义:
<intermediateThrowEvent id="myIntermediateThrowEvent" >
<XXXEventDefinition/>
</intermediateThrowEvent>抛出中间事件由下列元素定义:
-
(流程范围内)唯一的标识符
-
定义了抛出中间事件类型的,形如XXXEventDefinition的XML子元素(例如signalEventDefinition等)。查阅特定中间抛出事件类型,以了解更多细节。
8.2.29. 空抛出中间事件
下面的流程图展示了空抛出中间事件(intermediate throwing none event)的简单例子。其用于指示流程已经到达了某种状态。

添加一个执行监听器后,空中间事件就可以成为很好的监视某些KPI(Key Performance Indicators 关键绩效指标)的钩子。
<intermediateThrowEvent id="noneEvent">
<extensionElements>
<flowable:executionListener class="org.flowable.engine.test.bpmn.event.IntermediateNoneEventTest$MyExecutionListener" event="start" />
</extensionElements>
</intermediateThrowEvent>你也可以添加一些自己的代码,将部分事件发送给你的BAM(Business Activity Monitoring 业务活动监控)工具,或者DWH(Data Warehouse 数据仓库)。在这种情况下,引擎本身不会做任何事情,只是从中穿过。
8.2.30. 信号抛出中间事件
描述
信号抛出中间事件(signal intermediate throwing event),抛出所定义信号的信号事件。
在Flowable中,信号会广播至所有的激活的处理器(也就是说,所有的信号捕获事件)。可以同步或异步地发布信号。
-
在默认配置中,信号同步地传递。这意味着抛出信号的流程实例会等待,直到信号传递至所有的捕获信号的流程实例。所有的捕获流程实例也会在与抛出流程实例相同的事务中,也就是说如果收到通知的流程实例中,有一个实例产生了技术错误(抛出异常),则所有相关的实例都会失败。
-
信号也可以异步地传递。这是由到达抛出信号事件时的发送处理器来决定的。对于每个激活的处理器,JobExecutor会为其存储并传递一个异步通知消息(asynchronous notification message),即作业(Job)。
图示
消息抛出中间事件用内部有信号图标的标准中间事件(两层圆圈)表示。信号图标是黑色的(已填充),代表抛出的含义。
XML表示
信号中间事件与抛出中间事件一样定义。子元素为signalEventDefinition。
<intermediateThrowEvent id="signal">
<signalEventDefinition signalRef="newCustomerSignal" />
</intermediateThrowEvent>异步信号事件这样定义:
<intermediateThrowEvent id="signal">
<signalEventDefinition signalRef="newCustomerSignal" flowable:async="true" />
</intermediateThrowEvent>示例
参阅信号事件定义章节。
8.2.31. 补偿抛出中间事件
描述
补偿抛出中间事件(compensation intermediate throwing event)用于触发补偿。
触发补偿:既可以为设计的活动触发补偿,也可以为补偿事件所在的范围触发补偿。补偿由活动所关联的补偿处理器执行。
-
活动抛出补偿时,活动关联的补偿处理器将执行的次数,为活动成功完成的次数。
-
抛出补偿时,当前范围中所有的活动,包括并行分支上的活动都会被补偿。
-
补偿分层触发:如果将要被补偿的活动是一个子流程,则该子流程中所有的活动都会触发补偿。如果该子流程有嵌套的活动,则会递归地抛出补偿。然而,补偿不会传播至流程的上层:如果子流程中触发了补偿,该补偿不会传播至子流程范围外的活动。BPMN规范指出,对“与子流程在相同级别”的活动触发补偿。
-
在Flowable中,补偿按照执行的相反顺序运行。这意味着最后完成的活动会第一个补偿。
-
可以使用补偿抛出中间事件补偿已经成功完成的事务子流程。
请注意:如果抛出补偿的范围中有一个子流程,而该子流程包含有关联了补偿处理器的活动,则当抛出补偿时,只有该子流程成功完成时,补偿才会传播至该子流程。如果子流程内嵌套的部分活动已经完成,并附加了补偿处理器,但包含这些活动的子流程还没有完成,则这些补偿处理器仍不会执行。参考下面的例子:
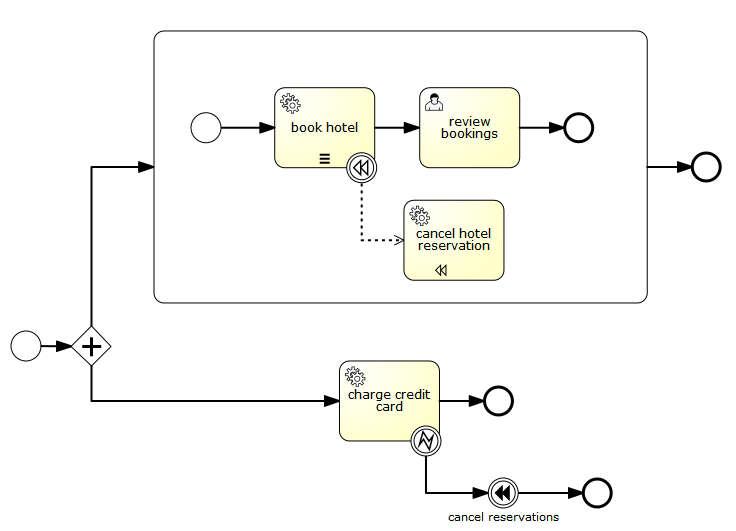
在这个流程中,有两个并行的执行:一个执行嵌入子流程,另一个执行“charge credit card(信用卡付款)”活动。假定两个执行都已开始,且第一个执行正等待用户完成“review bookings(检查预定)”任务。第二个执行进行了“charge credit card(信用卡付款)”活动的操作,抛出了错误,导致“cancel reservations(取消预订)”事件触发补偿。这时并行子流程还未完成,意味着补偿不会传播至该子流程,因此不会执行“cancel hotel reservation(取消酒店预订)”补偿处理器。而如果“cancel reservations(取消预订)”运行前,这个用户任务(因此该嵌入式子流程也)已经完成,则补偿会传播至该嵌入式子流程。
流程变量:当补偿嵌入式子流程时,用于执行补偿处理器的执行,可以访问子流程的局部流程变量在子流程完成时的值。为此,会对范围执行(为执行子流程所创建的执行)所关联的流程变量进行快照。意味着:
-
补偿执行器无法访问子流程范围内并行执行所添加的变量。
-
上层执行所关联的流程变量(例如流程实例关联的流程变量)不在该快照中。因为补偿处理器可以直接访问这些流程变量在抛出补偿时的值。
-
只会为嵌入式子流程进行变量快照。其他活动不会进行变量快照。
目前的限制:
-
目前不支持
waitForCompletion="false"。当补偿抛出中间事件触发补偿时,只有在补偿成功完成时,才会离开该事件。 -
补偿由并行执行运行。并行执行会按照补偿活动完成的逆序启动。
-
补偿不会传播至调用活动(call activity)生成的子流程。
图示
补偿抛出中间事件用内部有补偿图标的标准中间事件(两层圆圈)表示。补偿图标是黑色的(已填充),代表抛出的含义。
XML表示
补偿中间事件与抛出中间事件一样定义。子元素为compensateEventDefinition。
<intermediateThrowEvent id="throwCompensation">
<compensateEventDefinition />
</intermediateThrowEvent>另外,activityRef可选项用于为指定的范围或活动触发补偿:
<intermediateThrowEvent id="throwCompensation">
<compensateEventDefinition activityRef="bookHotel" />
</intermediateThrowEvent>8.3. 顺序流
8.3.1. 描述
顺序流(sequence flow)是流程中两个元素间的连接器。在流程执行过程中,一个元素被访问后,会沿着其所有出口顺序流继续执行。这意味着BPMN 2.0的默认是并行执行的:两个出口顺序流就会创建两个独立的、并行的执行路径。
8.3.2. 图示
顺序流,用从源元素指向目标元素的箭头表示。箭头总是指向目标元素。

8.3.3. XML表示
顺序流需要有流程唯一的id,并引用存在的源与目标元素。
<sequenceFlow id="flow1" sourceRef="theStart" targetRef="theTask" />8.3.4. 条件顺序流
描述
在顺序流上可以定义条件(conditional sequence flow)。当离开BPMN 2.0活动时,默认行为是计算其每个出口顺序流上的条件。当条件计算为true时,选择该出口顺序流。如果该方法选择了多条顺序流,则会生成多个执行,流程会以并行方式继续。
请注意:上面的介绍针对BPMN 2.0活动(与事件),但不适用于网关(gateway)。不同类型的网关,会用不同的方式处理带有条件的顺序流。
图示
条件顺序流用起点带有小菱形的顺序流表示。在顺序流旁显示条件表达式。
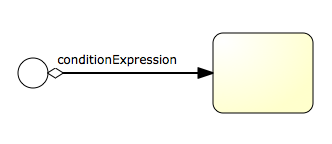
XML表示
条件顺序流的XML表示格式为含有conditionExpression(条件表达式)子元素的普通顺序流。请注意目前只支持tFormalExpressions。可以省略xsi:type=""定义,默认为唯一支持的表达式类型。
<sequenceFlow id="flow" sourceRef="theStart" targetRef="theTask">
<conditionExpression xsi:type="tFormalExpression">
<![CDATA[${order.price > 100 && order.price < 250}]]>
</conditionExpression>
</sequenceFlow>目前conditionalExpressions只能使用UEL。详细信息可以在表达式章节找到。使用的表达式需要能解析为boolean值,否则当计算条件时会抛出异常。
-
下面的例子,通过典型的JavaBean的方式,使用getter引用流程变量的数据。
<conditionExpression xsi:type="tFormalExpression">
<![CDATA[${order.price > 100 && order.price < 250}]]>
</conditionExpression>-
这个例子调用了一个解析为boolean值的方法。
<conditionExpression xsi:type="tFormalExpression">
<![CDATA[${order.isStandardOrder()}]]>
</conditionExpression>Flowable发行版中包含了下列示例流程,用于展示值表达式与方法表达式的使用(参见org.flowable.examples.bpmn.expression)。

8.3.5. 默认顺序流
描述
所有的BPMN 2.0任务与网关都可以使用默认顺序流(default sequence flow)。只有当没有其他顺序流可以选择时,才会选择默认顺序流作为活动的出口顺序流。流程会忽略默认顺序流上的条件。
图示
默认顺序流用起点带有“斜线”标记的一般顺序流表示。

XML表示
活动的默认顺序流由该活动的default属性定义。下面的XML片段展示了一个排他网关(exclusive gateway),带有默认顺序流flow 2。只有当conditionA与conditionB都计算为false时,才会选择默认顺序流作为网关的出口顺序流。
<exclusiveGateway id="exclusiveGw" name="Exclusive Gateway" default="flow2" />
<sequenceFlow id="flow1" sourceRef="exclusiveGw" targetRef="task1">
<conditionExpression xsi:type="tFormalExpression">${conditionA}</conditionExpression>
</sequenceFlow>
<sequenceFlow id="flow2" sourceRef="exclusiveGw" targetRef="task2"/>
<sequenceFlow id="flow3" sourceRef="exclusiveGw" targetRef="task3">
<conditionExpression xsi:type="tFormalExpression">${conditionB}</conditionExpression>
</sequenceFlow>对应下面的图示:
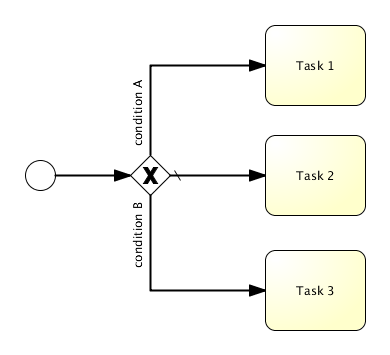
8.4. 网关
网关(gateway)用于控制执行的流向(或者按BPMN 2.0的用词:执行的“标志(token)”)。网关可以消费(consuming)与生成(generating)标志。
网关用其中带有图标的菱形表示。该图标显示了网关的类型。
8.4.1. 排他网关
描述
排他网关(exclusive gateway)(也叫异或网关 XOR gateway,或者更专业的,基于数据的排他网关 exclusive data-based gateway),用于对流程中的决策建模。当执行到达这个网关时,会按照所有出口顺序流定义的顺序对它们进行计算。选择第一个条件计算为true的顺序流(当没有设置条件时,认为顺序流为true)继续流程。
请注意这里出口顺序流的含义与BPMN 2.0中的一般情况不一样。一般情况下,会选择所有条件计算为true的顺序流,并行执行。而使用排他网关时,只会选择一条顺序流。当多条顺序流的条件都计算为true时,会且仅会选择在XML中最先定义的顺序流继续流程。如果没有可选的顺序流,会抛出异常。
图示
排他网关用内部带有’X’图标的标准网关(菱形)表示,'X’图标代表异或的含义。请注意内部没有图标的网关默认为排他网关。BPMN 2.0规范不允许在同一个流程中混合使用有及没有X的菱形标志。
XML表示
排他网关的XML表示格式很简洁:一行定义网关的XML。条件表达式定义在其出口顺序流上。查看条件顺序流章节了解这种表达式的可用选项。
以下面的模型为例:
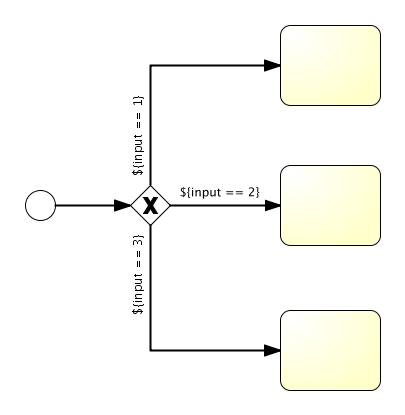
其XML表示如下:
<exclusiveGateway id="exclusiveGw" name="Exclusive Gateway" />
<sequenceFlow id="flow2" sourceRef="exclusiveGw" targetRef="theTask1">
<conditionExpression xsi:type="tFormalExpression">${input == 1}</conditionExpression>
</sequenceFlow>
<sequenceFlow id="flow3" sourceRef="exclusiveGw" targetRef="theTask2">
<conditionExpression xsi:type="tFormalExpression">${input == 2}</conditionExpression>
</sequenceFlow>
<sequenceFlow id="flow4" sourceRef="exclusiveGw" targetRef="theTask3">
<conditionExpression xsi:type="tFormalExpression">${input == 3}</conditionExpression>
</sequenceFlow>8.4.2. 并行网关
描述
网关也可以建模流程中的并行执行。在流程模型中引入并行的最简单的网关,就是并行网关(parallel gateway)。它可以将执行分支(fork)为多条路径,也可以合并(join)多条入口路径的执行。
并行网关的功能取决于其入口与出口顺序流:
-
分支:所有的出口顺序流都并行执行,为每一条顺序流创建一个并行执行。
-
合并:所有到达并行网关的并行执行都会在网关处等待,直到每一条入口顺序流都到达了有个执行。然后流程经过该合并网关继续。
请注意,如果并行网关同时具有多条入口与出口顺序流,可以同时具有分支与合并的行为。在这种情况下,网关首先合并所有入口顺序流,然后分裂为多条并行执行路径。
与其他网关类型有一个重要区别:并行网关不计算条件。如果连接到并行网关的顺序流上定义了条件,会直接忽略该条件。
图示
并行网关,用内部带有’加号’图标的网关(菱形)表示,代表与(AND)的含义。
XML表示
定义并行网关只需要一行XML:
<parallelGateway id="myParallelGateway" />实际行为(分支,合并或两者皆有),由连接到该并行网关的顺序流定义。
例如,上面的模型表示为下面的XML:
<startEvent id="theStart" />
<sequenceFlow id="flow1" sourceRef="theStart" targetRef="fork" />
<parallelGateway id="fork" />
<sequenceFlow sourceRef="fork" targetRef="receivePayment" />
<sequenceFlow sourceRef="fork" targetRef="shipOrder" />
<userTask id="receivePayment" name="Receive Payment" />
<sequenceFlow sourceRef="receivePayment" targetRef="join" />
<userTask id="shipOrder" name="Ship Order" />
<sequenceFlow sourceRef="shipOrder" targetRef="join" />
<parallelGateway id="join" />
<sequenceFlow sourceRef="join" targetRef="archiveOrder" />
<userTask id="archiveOrder" name="Archive Order" />
<sequenceFlow sourceRef="archiveOrder" targetRef="theEnd" />
<endEvent id="theEnd" />在上面的例子中,当流程启动后会创建两个任务:
ProcessInstance pi = runtimeService.startProcessInstanceByKey("forkJoin");
TaskQuery query = taskService.createTaskQuery()
.processInstanceId(pi.getId())
.orderByTaskName()
.asc();
List<Task> tasks = query.list();
assertEquals(2, tasks.size());
Task task1 = tasks.get(0);
assertEquals("Receive Payment", task1.getName());
Task task2 = tasks.get(1);
assertEquals("Ship Order", task2.getName());当这两个任务完成后,第二个并行网关会合并这两个执行。由于它只有一条出口顺序流,因此就不会再创建并行执行路径,而只是激活Archive Order(存档订单)任务。
请注意并行网关不需要“平衡”(也就是说,前后对应的两个并行网关,其入口/出口顺序流的数量不需要一致)。每个并行网关都会简单地等待所有入口顺序流,并为每一条出口顺序流创建并行执行,而不受流程模型中的其他结构影响。因此,下面的流程在BPMN 2.0中是合法的:
8.4.3. 包容网关
描述
可以把包容网关(inclusive gateway)看做排他网关与并行网关的组合。与排他网关一样,可以在包容网关的出口顺序流上定义条件,包容网关会计算条件。然而主要的区别是,包容网关与并行网关一样,可以同时选择多于一条出口顺序流。
包容网关的功能取决于其入口与出口顺序流:
-
分支:流程会计算所有出口顺序流的条件。对于每一条计算为true的顺序流,流程都会创建一个并行执行。
-
合并:所有到达包容网关的并行执行,都会在网关处等待。直到每一条具有流程标志(process token)的入口顺序流,都有一个执行到达。这是与并行网关的重要区别。换句话说,包容网关只会等待可以被执行的入口顺序流。在合并后,流程穿过合并并行网关继续。
请注意,如果包容网关同时具有多条入口与出口顺序流,可以同时具有分支与合并的行为。在这种情况下,网关首先合并所有具有流程标志的入口顺序流,然后为每一个条件计算为true的出口顺序流分裂出并行执行路径。
包容网关的汇聚行为比并行网关更复杂。所有到达包容网关的并行执行,都会在网关等待,直到所有“可以到达”包容网关的执行都“到达”包容网关。 判断方法为:计算当前流程实例中的所有执行,检查从其位置是否有一条到达包容网关的路径(忽略顺序流上的任何条件)。如果存在这样的执行(可到达但尚未到达),则不会触发包容网关的汇聚行为。
图示
包容网关,用内部带有’圆圈’图标的网关(菱形)表示。
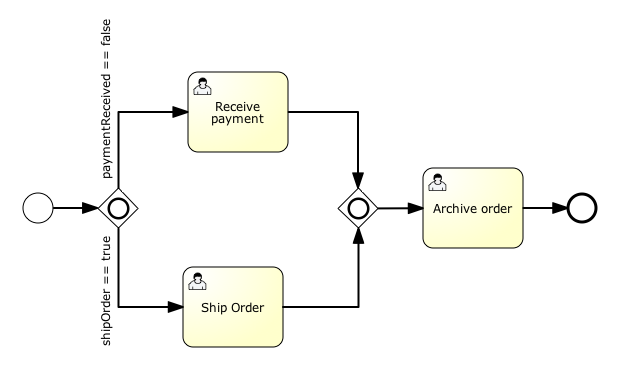
XML表示
定义包容网关需要一行XML:
<inclusiveGateway id="myInclusiveGateway" />实际行为(分支,合并或两者皆有),由连接到该包容网关的顺序流定义。
例如,上面的模型表现为下面的XML:
<startEvent id="theStart" />
<sequenceFlow id="flow1" sourceRef="theStart" targetRef="fork" />
<inclusiveGateway id="fork" />
<sequenceFlow sourceRef="fork" targetRef="receivePayment" >
<conditionExpression xsi:type="tFormalExpression">${paymentReceived == false}</conditionExpression>
</sequenceFlow>
<sequenceFlow sourceRef="fork" targetRef="shipOrder" >
<conditionExpression xsi:type="tFormalExpression">${shipOrder == true}</conditionExpression>
</sequenceFlow>
<userTask id="receivePayment" name="Receive Payment" />
<sequenceFlow sourceRef="receivePayment" targetRef="join" />
<userTask id="shipOrder" name="Ship Order" />
<sequenceFlow sourceRef="shipOrder" targetRef="join" />
<inclusiveGateway id="join" />
<sequenceFlow sourceRef="join" targetRef="archiveOrder" />
<userTask id="archiveOrder" name="Archive Order" />
<sequenceFlow sourceRef="archiveOrder" targetRef="theEnd" />
<endEvent id="theEnd" />在上面的例子中,当流程启动后,如果流程变量paymentReceived == false且shipOrder == true,会创建两个任务。如果只有一个流程变量等于true,则只会创建一个任务。如果没有条件计算为true,会抛出异常(可通过指定默出口顺序流避免)。在下面的例子中,只会创建ship order(传递订单)一个任务:
HashMap<String, Object> variableMap = new HashMap<String, Object>();
variableMap.put("receivedPayment", true);
variableMap.put("shipOrder", true);
ProcessInstance pi = runtimeService.startProcessInstanceByKey("forkJoin");
TaskQuery query = taskService.createTaskQuery()
.processInstanceId(pi.getId())
.orderByTaskName()
.asc();
List<Task> tasks = query.list();
assertEquals(1, tasks.size());
Task task = tasks.get(0);
assertEquals("Ship Order", task.getName());当这个任务完成后,第二个包容网关会合并这两个执行。并且由于它只有一条出口顺序流,所有不会再创建并行执行路径,而只会激活Archive Order(存档订单)任务。
请注意包容网关不需要“平衡”(也就是说,对应的包容网关,其入口/出口顺序流的数量不需要匹配)。包容网关会简单地等待所有入口顺序流,并为每一条出口顺序流创建并行执行,不受流程模型中的其他结构影响。
请注意包容网关不需要“平衡”(也就是说,前后对应的两个包容网关,其入口/出口顺序流的数量不需要一致)。每个包容网关都会简单地等待所有入口顺序流,并为每一条出口顺序流创建并行执行,不受流程模型中的其他结构影响。
8.4.4. 基于事件的网关
描述
基于事件的网关(event-based gateway)提供了根据事件做选择的方式。网关的每一条出口顺序流都需要连接至一个捕获中间事件。当流程执行到达基于事件的网关时,与等待状态类似,网关会暂停执行,并且为每一条出口顺序流创建一个事件订阅。
请注意:基于事件的网关的出口顺序流与一般的顺序流不同。这些顺序流从不实际执行。相反,它们用于告知流程引擎:当执行到达一个基于事件的网关时,需要订阅什么事件。有以下限制:
-
一个基于事件的网关,必须有两条或更多的出口顺序流。
-
基于事件的网关,只能连接至
intermediateCatchEvent(捕获中间事件)类型的元素(Flowable不支持在基于事件的网关之后连接“接收任务 Receive Task”)。 -
连接至基于事件的网关的
intermediateCatchEvent,必须只有一个入口顺序流。
图示
基于事件的网关,用内部带有特殊图标的网关(菱形)表示。
XML表示
用于定义基于事件的网关的XML元素为eventBasedGateway。
示例
下面是一个带有基于事件的网关的示例流程。当执行到达基于事件的网关时,流程执行暂停。流程实例订阅alert信号事件,并创建一个10分钟后触发的定时器。流程引擎会等待10分钟,并同时等待信号事件。如果信号在10分钟内触发,则会取消定时器,流程沿着信号继续执行,激活Handle alert用户任务。如果10分钟内没有触发信号,则会继续执行,并取消信号订阅。
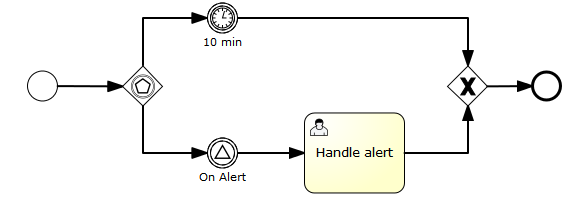
<definitions id="definitions"
xmlns="http://www.omg.org/spec/BPMN/20100524/MODEL"
xmlns:flowable="http://flowable.org/bpmn"
targetNamespace="Examples">
<signal id="alertSignal" name="alert" />
<process id="catchSignal">
<startEvent id="start" />
<sequenceFlow sourceRef="start" targetRef="gw1" />
<eventBasedGateway id="gw1" />
<sequenceFlow sourceRef="gw1" targetRef="signalEvent" />
<sequenceFlow sourceRef="gw1" targetRef="timerEvent" />
<intermediateCatchEvent id="signalEvent" name="Alert">
<signalEventDefinition signalRef="alertSignal" />
</intermediateCatchEvent>
<intermediateCatchEvent id="timerEvent" name="Alert">
<timerEventDefinition>
<timeDuration>PT10M</timeDuration>
</timerEventDefinition>
</intermediateCatchEvent>
<sequenceFlow sourceRef="timerEvent" targetRef="exGw1" />
<sequenceFlow sourceRef="signalEvent" targetRef="task" />
<userTask id="task" name="Handle alert"/>
<exclusiveGateway id="exGw1" />
<sequenceFlow sourceRef="task" targetRef="exGw1" />
<sequenceFlow sourceRef="exGw1" targetRef="end" />
<endEvent id="end" />
</process>
</definitions>8.5. 任务
8.5.1. 用户任务
描述
“用户任务(user task)”用于对需要人工执行的任务进行建模。当流程执行到达用户任务时,会为指派至该任务的用户或组的任务列表创建一个新任务。
图示
用户任务用左上角有一个小用户图标的标准任务(圆角矩形)表示。
XML表示
用户任务在XML中如下定义。其中id是必须属性,name是可选属性。
<userTask id="theTask" name="Important task" />也可以为用户任务添加描述(description)。事实上任何BPMN 2.0元素都可以有描述。描述由documentation元素定义。
<userTask id="theTask" name="Schedule meeting" >
<documentation>
Schedule an engineering meeting for next week with the new hire.
</documentation>可以使用标准Java方式获取描述文本:
task.getDescription()到期日期
每个任务都可以使用一个字段标志该任务的到期日期(due date)。可以使用查询API,查询在给定日期前或后到期的任务。
可以在任务定义中使用扩展指定表达式,以在任务创建时设定到期日期。该表达式必须解析为java.util.Date,java.util.String (ISO8601格式),ISO8601时间长度(例如PT50M),或者null。例如,可以使用在流程里前一个表单中输入的日期,或者由前一个服务任务计算出的日期。如果使用的是时间长度,则到期日期基于当前时间加上给定长度计算。例如当dueDate使用“PT30M”时,任务在从现在起30分钟后到期。
<userTask id="theTask" name="Important task" flowable:dueDate="${dateVariable}"/>任务的到期日期也可以使用TaskService,或者在TaskListener中使用传递的DelegateTask修改。
用户指派
用户任务可以直接指派(assign)给用户。可以定义humanPerformer子元素来实现。humanPerformer需要resourceAssignmentExpression来实际定义用户。目前,只支持formalExpressions。
<process >
...
<userTask id='theTask' name='important task' >
<humanPerformer>
<resourceAssignmentExpression>
<formalExpression>kermit</formalExpression>
</resourceAssignmentExpression>
</humanPerformer>
</userTask>只能指定一个用户作为任务的humanPerformer。在Flowable术语中,这个用户被称作办理人(assignee)。拥有办理人的任务,在其他人的任务列表中不可见,而只能在该办理人的个人任务列表中看到。
可以通过TaskService获取特定用户办理的任务:
List<Task> tasks = taskService.createTaskQuery().taskAssignee("kermit").list();任务也可以放在用户的候选任务列表中。在这个情况下,需要使用potentialOwner(潜在用户)结构。用法与humanPerformer结构类似。请注意需要指定表达式中的每一个元素为用户还是组(引擎无法自行判断)。
<process >
...
<userTask id='theTask' name='important task' >
<potentialOwner>
<resourceAssignmentExpression>
<formalExpression>user(kermit), group(management)</formalExpression>
</resourceAssignmentExpression>
</potentialOwner>
</userTask>可用如下方法获取定义了potentialOwner结构的任务:
List<Task> tasks = taskService.createTaskQuery().taskCandidateUser("kermit");将获取所有kermit作为候选用户的任务,也就是说,表达式含有user(kermit)的任务。同时也将获取所有指派给kermit为其成员的组的任务(例如,kermit时management组的成员,且任务指派给management组)。组在运行时解析,并可通过身份服务管理。
如果并未指定给定字符串是用户还是组,引擎默认其为组。下列代码与声明group(accountancy)效果一样。
<formalExpression>accountancy</formalExpression>用于任务指派的Flowable扩展
很明显,当指派关系不复杂时,这种用户与组的指派方式十分笨重。为避免这种复杂性,可以在用户任务上使用自定义扩展。
-
assignee(办理人)属性:这个自定义扩展用于直接将用户指派至用户任务。
<userTask id="theTask" name="my task" flowable:assignee="kermit" />与上面定义的humanPerformer结构效果完全相同。
-
candidateUsers(候选用户)属性:这个自定义扩展用于为任务指定候选用户。
<userTask id="theTask" name="my task" flowable:candidateUsers="kermit, gonzo" />与使用上面定义的potentialOwner结构效果完全相同。请注意不需要像在potentialOwner中一样,使用user(kermit)的声明,因为这个属性只能用于用户。
-
candidateGroups(候选组)attribute:这个自定义扩展用于为任务指定候选组。
<userTask id="theTask" name="my task" flowable:candidateGroups="management, accountancy" />与使用上面定义的potentialOwner结构效果完全相同。请注意不需要像在potentialOwner中一样,使用group(management)的声明,因为这个属性只能用于组。
-
可以定义在一个用户任务上同时定义candidateUsers与candidateGroups。
请注意:尽管Flowable提供了IdentityService身份管理组件,但并不会检查给定的用户是否实际存在。这是为了便于将Flowable嵌入应用时,与已有的身份管理解决方案进行集成。
自定义身份关联类型
在用户指派中已经介绍过,BPMN标准支持单个指派用户即humanPerformer,或者由一组用户构成potentialOwners潜在用户池。另外,Flowable为用户任务定义了扩展属性元素,用于代表任务的办理人或者候选用户。
Flowable支持的身份关联(identity link)类型有:
public class IdentityLinkType {
/* Flowable内置角色 */
public static final String ASSIGNEE = "assignee";
public static final String CANDIDATE = "candidate";
public static final String OWNER = "owner";
public static final String STARTER = "starter";
public static final String PARTICIPANT = "participant";
}BPMN标准及Flowable示例中,身份认证是用户与组。在前一章节提到过,Flowable的身份管理实现并不适用于生产环境,而需要在支持的认证概要下自行扩展。
如果需要添加额外的关联类型,可按照下列语法,使用自定义资源作为扩展元素:
<userTask id="theTask" name="make profit">
<extensionElements>
<flowable:customResource flowable:name="businessAdministrator">
<resourceAssignmentExpression>
<formalExpression>user(kermit), group(management)</formalExpression>
</resourceAssignmentExpression>
</flowable:customResource>
</extensionElements>
</userTask>自定义关联表达式添加至TaskDefinition类:
protected Map<String, Set<Expression>> customUserIdentityLinkExpressions =
new HashMap<String, Set<Expression>>();
protected Map<String, Set<Expression>> customGroupIdentityLinkExpressions =
new HashMap<String, Set<Expression>>();
public Map<String, Set<Expression>> getCustomUserIdentityLinkExpressions() {
return customUserIdentityLinkExpressions;
}
public void addCustomUserIdentityLinkExpression(
String identityLinkType, Set<Expression> idList) {
customUserIdentityLinkExpressions.put(identityLinkType, idList);
}
public Map<String, Set<Expression>> getCustomGroupIdentityLinkExpressions() {
return customGroupIdentityLinkExpressions;
}
public void addCustomGroupIdentityLinkExpression(
String identityLinkType, Set<Expression> idList) {
customGroupIdentityLinkExpressions.put(identityLinkType, idList);
}这些方法将在运行时,由UserTaskActivityBehavior的handleAssignments方法调用。
最后,需要扩展IdentityLinkType类,以支持自定义身份关联类型:
package com.yourco.engine.task;
public class IdentityLinkType extends org.flowable.engine.task.IdentityLinkType {
public static final String ADMINISTRATOR = "administrator";
public static final String EXCLUDED_OWNER = "excludedOwner";
}通过任务监听器自定义指派
如果上面的方式仍不能满足要求,可以在创建事件(create event)上使用任务监听器,调用自定义指派逻辑:
<userTask id="task1" name="My task" >
<extensionElements>
<flowable:taskListener event="create" class="org.flowable.MyAssignmentHandler" />
</extensionElements>
</userTask>传递至TaskListener的DelegateTask,可用于设置办理人与候选用户/组:
public class MyAssignmentHandler implements TaskListener {
public void notify(DelegateTask delegateTask) {
// 在这里执行自定义身份查询
// 然后调用如下命令:
delegateTask.setAssignee("kermit");
delegateTask.addCandidateUser("fozzie");
delegateTask.addCandidateGroup("management");
...
}
}当使用Spring时,可以按上面章节的介绍使用自定义指派属性,并交由使用任务监听器、带有表达式的Spring bean,监听任务创建事件。在下面的例子中,通过调用ldapService Spring bean的findManagerOfEmployee方法设置办理人。传递的emp参数是一个流程变量。
<userTask id="task" name="My Task" flowable:assignee="${ldapService.findManagerForEmployee(emp)}"/>也可以用于候选用户与组:
<userTask id="task" name="My Task" flowable:candidateUsers="${ldapService.findAllSales()}"/>请注意调用方法的返回类型必须是String或Collection<String>(候选用户或组):
public class FakeLdapService {
public String findManagerForEmployee(String employee) {
return "Kermit The Frog";
}
public List<String> findAllSales() {
return Arrays.asList("kermit", "gonzo", "fozzie");
}
}8.5.2. 脚本任务
描述
脚本任务(script task)是自动执行的活动。当流程执行到达脚本任务时,会执行相应的脚本。
图示
脚本任务用左上角有一个小“脚本”图标的标准BPMN 2.0任务(圆角矩形)表示。

XML表示
脚本任务使用script与scriptFormat元素定义。
<scriptTask id="theScriptTask" name="Execute script" scriptFormat="groovy">
<script>
sum = 0
for ( i in inputArray ) {
sum += i
}
</script>
</scriptTask>scriptFormat属性的值,必须是兼容JSR-223(Java平台脚本)的名字。默认情况下,JavaScript包含在每一个JDK中,因此不需要添加任何JAR文件。如果想使用其它(兼容JSR-223的)脚本引擎,则需要在classpath中添加相应的jar,并使用适当的名字。例如,Flowable单元测试经常使用Groovy,因为其语法与Java十分相似。
请注意Groovy脚本引擎与groovy-jsr223 JAR捆绑在一起。在Groovy 4.0版本以前,脚本引擎是Groovy JAR的一部分。因此,必须添加如下依赖:
<dependency>
<groupId>org.apache.groovy</groupId>
<artifactId>groovy-jsr223</artifactId>
<version>4.x.x<version>
</dependency>脚本中的变量
到达脚本引擎的执行中,所有的流程变量都可以在脚本中使用。在这个例子里,脚本变量'inputArray'实际上就是一个流程变量(一个integer的数组)。
<script>
sum = 0
for ( i in inputArray ) {
sum += i
}
</script>也可以简单地调用execution.setVariable("variableName", variableValue),在脚本中设置流程变量。默认情况下,变量不会自动储存(请注意,在一些早期版本中是会储存的!)。可以将scriptTask的autoStoreVariables参数设置为true,以自动保存任何在脚本中定义的变量(例如上例中的sum)。然而这并不是最佳实践。最佳实践是显式调用execution.setVariable(),因为在JDK近期的一些版本中,某些脚本语言不能自动保存变量。查看这个链接了解更多信息。
<scriptTask id="script" scriptFormat="JavaScript" flowable:autoStoreVariables="false">这个参数的默认值为false。也就是说如果在脚本任务定义中忽略这个参数,则脚本声明的所有变量将只在脚本执行期间有效。
在脚本中设置变量的例子:
<script>
def scriptVar = "test123"
execution.setVariable("myVar", scriptVar)
</script>请注意:下列名字是保留字,不能用于变量名:out,out:print,lang:import,context,elcontext。
脚本任务的结果
脚本任务的返回值,可以通过为脚本任务定义的'flowable:resultVariable'属性设置为流程变量。可以是已经存在的,或者新的流程变量。如果指定为已存在的流程变量,则流程变量的值会被脚本执行的结果值覆盖。如果不指定结果变量名,则脚本结果值将被忽略。
<scriptTask id="theScriptTask" name="Execute script" scriptFormat="juel" flowable:resultVariable="myVar">
<script>#{echo}</script>
</scriptTask>在上面的例子中,脚本执行的结果(解析表达式'#{echo}'的值),将在脚本完成后,设置为名为'myVar'的流程变量。
安全性
当使用javascript作为脚本语言时,可以使用“安全脚本(secure scripting)”。参见安全脚本章节。
8.5.3. Java服务任务
描述
Java服务任务(Java service task)用于调用Java类。
图示
服务任务用左上角有一个小齿轮图标的圆角矩形表示。

XML表示
有四种方法声明如何调用Java逻辑:
-
指定实现了JavaDelegate或ActivityBehavior的类
-
调用解析为委托对象(delegation object)的表达式
-
调用方法表达式(method expression)
-
对值表达式(value expression)求值
使用flowable:class属性提供全限定类名(fully qualified classname),指定流程执行时调用的类。
<serviceTask id="javaService"
name="My Java Service Task"
flowable:class="org.flowable.MyJavaDelegate" />查看实现章节,了解使用这种类的更多信息。
也可以使用解析为对象的表达式。该对象必须遵循的规则,与使用flowable:class创建的对象规则相同(查看更多)。
<serviceTask id="serviceTask" flowable:delegateExpression="${delegateExpressionBean}" />delegateExpressionBean是一个实现了JavaDelegate接口的bean,定义在Spring容器中。
使用flowable:expression属性指定需要计算的UEL方法表达式。
<serviceTask id="javaService"
name="My Java Service Task"
flowable:expression="#{printer.printMessage()}" />将在名为printer的对象上调用printMessage方法(不带参数)。
也可以为表达式中使用的方法传递变量。
<serviceTask id="javaService"
name="My Java Service Task"
flowable:expression="#{printer.printMessage(execution, myVar)}" />将在名为printer的对象上调用printMessage方法。传递的第一个参数为DelegateExecution,名为execution,在表达式上下文中默认可用。传递的第二个参数,是当前执行中,名为myVar变量的值。
可以使用flowable:expression属性指定需要计算的UEL值表达式。
<serviceTask id="javaService"
name="My Java Service Task"
flowable:expression="#{split.ready}" />会调用名为split的bean的ready参数的getter方法,getReady(不带参数)。该对象会被解析为执行的流程变量或(如果可用的话)Spring上下文中的bean。
实现
要实现可以在流程执行中调用的类,需要实现org.flowable.engine.delegate.JavaDelegate接口,并在execute方法中提供所需逻辑。当流程执行到达该活动时,会执行方法中定义的逻辑,并按照BPMN 2.0的默认方法离开活动。
下面是一个Java类的示例,用于将流程变量String改为大写。这个类需要实现org.flowable.engine.delegate.JavaDelegate接口,因此需要实现execute(DelegateExecution)方法。这个方法就是引擎将调用的方法,需要实现业务逻辑。可以通过DelegateExecution接口(点击链接获取该接口操作的详细Javadoc)访问流程实例信息,如流程变量等。
public class ToUppercase implements JavaDelegate {
public void execute(DelegateExecution execution) {
String var = (String) execution.getVariable("input");
var = var.toUpperCase();
execution.setVariable("input", var);
}
}请注意:只会为serviceTask上定义的Java类创建一个实例。所有流程实例共享同一个类实例,用于调用execute(DelegateExecution)。这意味着该类不能有任何成员变量,并需要是线程安全的,因为它可能会在不同线程中同时执行。这也影响了字段注入的使用方法。(译者注:原文可能较老,不正确。5.21中,flowable:class指定的类,会在流程实例启动时,为每个活动分别进行实例化。不过,当该活动在流程中重复执行,或者为多实例时,使用的都会是同一个类实例。)
在流程定义中引用(如flowable:class)的类,不会在部署时实例化。只有当流程执行第一次到达该类使用的地方时,才会创建该类的实例。如果找不到这个类,会抛出FlowableException。这是因为部署时的环境(更准确的说classpath),与实际运行的环境经常不一样。例如当使用ant或者Flowable应用中业务存档上传的方式部署的流程,其classpath中不会自动包含流程引用的类。
[内部:非公开实现类]也可以使用实现了org.flowable.engine.impl.delegate.ActivityBehavior接口的类。该实现可以访问更强大的引擎功能,例如,可以影响流程的控制流程。请注意这并不是很好的实践,需要避免这么使用。建议只有在高级使用场景下,并且你确知在做什么的时候,才使用ActivityBehavior接口。
字段注入
可以为委托类的字段注入值。支持下列注入方式:
-
字符串常量
-
表达式
如果可以的话,会按照Java Bean命名约定(例如,firstName成员使用setter setFirstName(…)),通过委托类的公有setter方法,注入变量。如果该字段没有可用的setter,会直接设置该委托类的私有成员的值。有的环境中,SecurityManagers不允许修改私有字段,因此为想要注入的字段暴露一个公有setter方法,是更安全的做法。
不论在流程定义中声明的是什么类型的值,注入对象的setter/私有字段的类型,总是org.flowable.engine.delegate.Expression。解析表达式后,可以被转型为合适的类型。
'flowable:class'属性支持字段注入。也可以在使用flowable:delegateExpression属性时,进行字段注入。然而考虑到线程安全,需要遵循特殊的规则(参见下一章节)。
下面的代码片段展示了如何为类中声明的字段注入常量值。请注意按照BPMN 2.0 XML概要的要求,在实际字段注入声明前,需要先声明’extensionElements’XML元素。
<serviceTask id="javaService"
name="Java service invocation"
flowable:class="org.flowable.examples.bpmn.servicetask.ToUpperCaseFieldInjected">
<extensionElements>
<flowable:field name="text" stringValue="Hello World" />
</extensionElements>
</serviceTask>ToUpperCaseFieldInjected类有一个字段text,为org.flowable.engine.delegate.Expression类型。当调用text.getValue(execution)时,会返回配置的字符串Hello World:
public class ToUpperCaseFieldInjected implements JavaDelegate {
private Expression text;
public void execute(DelegateExecution execution) {
execution.setVariable("var", ((String)text.getValue(execution)).toUpperCase());
}
}另外,对于较长文本(例如邮件正文),可以使用'flowable:string'子元素:
<serviceTask id="javaService"
name="Java service invocation"
flowable:class="org.flowable.examples.bpmn.servicetask.ToUpperCaseFieldInjected">
<extensionElements>
<flowable:field name="text">
<flowable:string>
This is a long string with a lot of words and potentially way longer even!
</flowable:string>
</flowable:field>
</extensionElements>
</serviceTask>可以使用表达式在运行时动态解析注入的值。这种表达式可以使用流程变量,或者(若使用Spring)Spring定义的Bean。在服务任务实现中提到过,当服务任务中使用flowable:class属性时,该Java类的实例在所有流程实例中共享。要动态地为字段注入值,可以在org.flowable.engine.delegate.Expression中注入值或方法表达式,它们会通过execute方法传递的DelegateExecution计算/调用。
下面的示例类使用了注入的表达式,并使用当前的DelegateExecution解析它们。调用genderBean方法时传递的是gender变量。完整的代码与测试可以在org.flowable.examples.bpmn.servicetask.JavaServiceTaskTest.testExpressionFieldInjection中找到
<serviceTask id="javaService" name="Java service invocation"
flowable:class="org.flowable.examples.bpmn.servicetask.ReverseStringsFieldInjected">
<extensionElements>
<flowable:field name="text1">
<flowable:expression>${genderBean.getGenderString(gender)}</flowable:expression>
</flowable:field>
<flowable:field name="text2">
<flowable:expression>Hello ${gender == 'male' ? 'Mr.' : 'Mrs.'} ${name}</flowable:expression>
</flowable:field>
</ extensionElements>
</ serviceTask>public class ReverseStringsFieldInjected implements JavaDelegate {
private Expression text1;
private Expression text2;
public void execute(DelegateExecution execution) {
String value1 = (String) text1.getValue(execution);
execution.setVariable("var1", new StringBuffer(value1).reverse().toString());
String value2 = (String) text2.getValue(execution);
execution.setVariable("var2", new StringBuffer(value2).reverse().toString());
}
}另外,为避免XML太过冗长,可以将表达式设置为属性,而不是子元素。
<flowable:field name="text1" expression="${genderBean.getGenderString(gender)}" />
<flowable:field name="text1" expression="Hello ${gender == 'male' ? 'Mr.' : 'Mrs.'} ${name}" />字段注入与线程安全
通常情况下,在服务任务中使用Java委托与字段注入是线程安全的。然而,有些情况下不能保证线程安全。这取决于设置,或Flowable运行的环境。
当使用flowable:class属性时,使用字段注入总是线程安全的(译者注:仍不完全安全,如对于多实例服务任务,使用的是同一个实例)。对于引用了某个类的每一个服务任务,都会实例化新的实例,并且在创建实例时注入一次字段。在不同的任务或流程定义中多次使用同一个类没有问题。
当使用flowable:expression属性时,不能使用字段注入。只能通过方法调用传递变量。总是线程安全的。
当使用flowable:delegateExpression属性时,委托实例的线程安全性,取决于表达式解析的方式。如果该委托表达式在多个任务或流程定义中重复使用,并且表达式总是返回相同的示例,则字段注入不是线程安全的。让我们看几个例子。
假设表达式为${factory.createDelegate(someVariable)},其中factory为引擎可用的Java bean(例如使用Spring集成时的Spring bean),并在每次表达式解析时创建新的实例。这种情况下,使用字段注入时,没有线程安全性问题:每次表达式解析时,都会注入新实例的字段。
然而,如果表达式为${someJavaDelegateBean},解析为JavaDelegate的实现,并且在创建单例的环境(如Spring)中运行。当在不同的任务或流程定义中使用这个表达式时,表达式总会解析为相同的实例。这种情况下,使用字段注入不是线程安全的。例如:
<serviceTask id="serviceTask1" flowable:delegateExpression="${someJavaDelegateBean}">
<extensionElements>
<flowable:field name="someField" expression="${input * 2}"/>
</extensionElements>
</serviceTask>
<!-- 其它流程定义元素 -->
<serviceTask id="serviceTask2" flowable:delegateExpression="${someJavaDelegateBean}">
<extensionElements>
<flowable:field name="someField" expression="${input * 2000}"/>
</extensionElements>
</serviceTask>这段示例代码有两个服务任务,使用同一个委托表达式,但是expression字段填写不同的值。如果该表达式解析为相同的实例,就会在并发场景下,注入someField字段时出现竞争条件。
最简单的解决方法是:
-
使用表达式代替直接使用Java委托,并将所需数据通过方法参数传递给委托。
-
或者,在每次委托表达式解析时,返回委托类的新实例。这意味着这个bean的scope必须是prototype(原型)(例如在委托类上加上@Scope(SCOPE_PROTOTYPE)注解)。
在Flowable 5.22版本中,可以通过配置流程引擎配置,禁用在委托表达式上使用字段注入。需要设置delegateExpressionFieldInjectionMode参数(取org.flowable.engine.imp.cfg.DelegateExpressionFieldInjectionMode枚举中的值)。
可使用下列选项:
-
DISABLED(禁用):当使用委托表达式时,完全禁用字段注入。不会再尝试进行字段注入。这是最安全的方式,保证线程安全。
-
COMPATIBILITY(兼容):在这个模式下,行为与V5.21之前完全一样:可以在委托表达式中使用字段注入,如果委托类中没有定义该字段,会抛出异常。这是最不线程安全的模式,但可以保证历史版本兼容性,也可以在委托表达式只在一个任务中使用的时候(因此不会产生并发竞争条件),安全使用。
-
MIXED(混合):可以在使用委托表达式时注入,但当委托中没有定义字段时,不会抛出异常。这样可以在部分委托(比如不是单例的实例)中使用注入,而在部分委托中不使用注入。
-
Flowable 5.x版本的默认模式为COMPATIBILITY。
-
Flowable 6.x版本的默认模式为MIXED。
例如,假设使用MIXED模式,并使用Spring集成,在Spring配置中定义了如下bean:
<bean id="singletonDelegateExpressionBean"
class="org.flowable.spring.test.fieldinjection.SingletonDelegateExpressionBean" />
<bean id="prototypeDelegateExpressionBean"
class="org.flowable.spring.test.fieldinjection.PrototypeDelegateExpressionBean"
scope="prototype" />第一个bean是一般的Spring bean,因此是单例的。第二个bean的scope为prototype,因此每次请求这个bean时,Spring容器都会返回一个新实例。
在以下流程定义中:
<serviceTask id="serviceTask1" flowable:delegateExpression="${prototypeDelegateExpressionBean}">
<extensionElements>
<flowable:field name="fieldA" expression="${input * 2}"/>
<flowable:field name="fieldB" expression="${1 + 1}"/>
<flowable:field name="resultVariableName" stringValue="resultServiceTask1"/>
</extensionElements>
</serviceTask>
<serviceTask id="serviceTask2" flowable:delegateExpression="${prototypeDelegateExpressionBean}">
<extensionElements>
<flowable:field name="fieldA" expression="${123}"/>
<flowable:field name="fieldB" expression="${456}"/>
<flowable:field name="resultVariableName" stringValue="resultServiceTask2"/>
</extensionElements>
</serviceTask>
<serviceTask id="serviceTask3" flowable:delegateExpression="${singletonDelegateExpressionBean}">
<extensionElements>
<flowable:field name="fieldA" expression="${input * 2}"/>
<flowable:field name="fieldB" expression="${1 + 1}"/>
<flowable:field name="resultVariableName" stringValue="resultServiceTask1"/>
</extensionElements>
</serviceTask>
<serviceTask id="serviceTask4" flowable:delegateExpression="${singletonDelegateExpressionBean}">
<extensionElements>
<flowable:field name="fieldA" expression="${123}"/>
<flowable:field name="fieldB" expression="${456}"/>
<flowable:field name="resultVariableName" stringValue="resultServiceTask2"/>
</extensionElements>
</serviceTask>有四个服务任务,第一、二个使用${prototypeDelegateExpressionBean}委托表达式,第三、四个使用${singletonDelegateExpressionBean}委托表达式。
先看原型bean:
public class PrototypeDelegateExpressionBean implements JavaDelegate {
public static AtomicInteger INSTANCE_COUNT = new AtomicInteger(0);
private Expression fieldA;
private Expression fieldB;
private Expression resultVariableName;
public PrototypeDelegateExpressionBean() {
INSTANCE_COUNT.incrementAndGet();
}
@Override
public void execute(DelegateExecution execution) {
Number fieldAValue = (Number) fieldA.getValue(execution);
Number fieldValueB = (Number) fieldB.getValue(execution);
int result = fieldAValue.intValue() + fieldValueB.intValue();
execution.setVariable(resultVariableName.getValue(execution).toString(), result);
}
}在运行上面流程定义的流程实例后,INSTANCE_COUNT的值为2。这是因为每次解析${prototypeDelegateExpressionBean}时,都会创建新实例。可以看到三个Expression成员字段的注入没有任何问题。
单例bean则有一点区别:
public class SingletonDelegateExpressionBean implements JavaDelegate {
public static AtomicInteger INSTANCE_COUNT = new AtomicInteger(0);
public SingletonDelegateExpressionBean() {
INSTANCE_COUNT.incrementAndGet();
}
@Override
public void execute(DelegateExecution execution) {
Expression fieldAExpression = DelegateHelper.getFieldExpression(execution, "fieldA");
Number fieldA = (Number) fieldAExpression.getValue(execution);
Expression fieldBExpression = DelegateHelper.getFieldExpression(execution, "fieldB");
Number fieldB = (Number) fieldBExpression.getValue(execution);
int result = fieldA.intValue() + fieldB.intValue();
String resultVariableName = DelegateHelper.getFieldExpression(execution,
"resultVariableName").getValue(execution).toString();
execution.setVariable(resultVariableName, result);
}
}在对于单例bean,INSTANCE_COUNT总是1。在这个委托中,没有Expression成员字段(使用MIXED模式)。而在COMPATIBILITY模式下,就会抛出异常,因为需要有成员字段。这个bean也可以使用DISABLED模式,但会禁用上面进行了字段注入的原型bean。
在委托的代码里,使用了org.flowable.engine.delegate.DelegateHelper。它提供了一些有用的工具方法,用于执行相同的逻辑,并且在单例中是线程安全的。与注入Expression不同,它通过getFieldExpression读取。这意味着在服务任务的XML里,字段定义与单例bean完全相同。查看上面的XML代码,可以看到定义是相同的,只是实现逻辑不同。
技术提示:getFieldExpression直接读取BpmnModel,并在方法执行时创建表达式,因此是线程安全的。
-
在Flowable V5.x版本中,(由于架构缺陷)不能在ExecutionListener或TaskListener中使用DelegateHelper。要保证监听器的线程安全,仍需使用表达式,或确保每次解析委托表达式时,都创建新实例。
-
在Flowable V6.x版本中,在ExecutionListener或TaskListener中可以使用DelegateHelper。例如在V6.x版本中,下列代码可以使用DelegateHelper:
<extensionElements>
<flowable:executionListener
delegateExpression="${testExecutionListener}" event="start">
<flowable:field name="input" expression="${startValue}" />
<flowable:field name="resultVar" stringValue="processStartValue" />
</flowable:executionListener>
</extensionElements>其中testExecutionListener解析为ExecutionListener接口的一个实现的实例:
@Component("testExecutionListener")
public class TestExecutionListener implements ExecutionListener {
@Override
public void notify(DelegateExecution execution) {
Expression inputExpression = DelegateHelper.getFieldExpression(execution, "input");
Number input = (Number) inputExpression.getValue(execution);
int result = input.intValue() * 100;
Expression resultVarExpression = DelegateHelper.getFieldExpression(execution, "resultVar");
execution.setVariable(resultVarExpression.getValue(execution).toString(), result);
}
}服务任务的结果
服务执行的返回值(仅对使用表达式的服务任务),可以通过为服务任务定义的'flowable:resultVariable'属性设置为流程变量。可以是已经存在的,或者新的流程变量。 如果指定为已存在的流程变量,则流程变量的值会被服务执行的结果值覆盖。 如果使用'flowable:useLocalScopeForResultVariable',则会将结果值设置为局部变量。 如果不指定结果变量名,则服务任务的结果值将被忽略。
<serviceTask id="aMethodExpressionServiceTask"
flowable:expression="#{myService.doSomething()}"
flowable:resultVariable="myVar" />在上例中,服务执行的结果(流程变量或Spring bean中,使用'myService'名字所获取的对象,调用'doSomething()'方法的返回值),在服务执行完成后,会设置为名为'myVar'的流程变量。
可触发
一种常见的模式是发送JMS消息或HTTP调用触发外部服务,然后流程实例进入等待状态。之后外部系统会回复响应,流程实例继续执行下一个活动。在默认的BPMN中,需要使用服务任务和接收任务(receive task)。但是这样会引入竞争条件:外部服务的响应可能会早于流程实例持久化及接收任务激活。为了解决这个问题,Flowable为服务任务增加了triggerable(可触发)属性,可以将服务任务转变为执行服务逻辑,并在继续执行之前等待外部触发的任务。如果在可触发服务任务上同时设置异步(async 为 true),则流程实例会先持久化,然后在异步作业中执行服务任务逻辑。在BPMN XML中,可以这样实现可触发服务任务:
<serviceTask id="aTriggerableServiceTask"
flowable:expression="#{myService.doSomething()}"
flowable:triggerable="true"
flowable:async="true" />外部服务可以同步或异步地触发等待中的流程实例。为了避免乐观锁异常,最好使用异步触发。默认情况下,异步作业是排他的,也就是说流程实例会被锁定,以保证流程实例中的其他活动不会影响到触发器的逻辑。可以使用RuntimeService的triggerAsync方法,异步触发等待中的流程实例。当然还是可以使用RuntimeService的trigger方法,同步触发。
处理异常
当执行自定义逻辑时,通常需要捕获并在流程中处理特定的业务异常。Flowable提供了多种选择。
抛出BPMN错误
可以在服务任务或脚本任务的用户代码中抛出BPMN错误。可以在Java委托、脚本、表达式与委托表达式中,抛出特殊的FlowableException:BpmnError。引擎会捕获这个异常,并将其转发至合适的错误处理器,如错误边界事件或错误事件子流程。
public class ThrowBpmnErrorDelegate implements JavaDelegate {
public void execute(DelegateExecution execution) throws Exception {
try {
executeBusinessLogic();
} catch (BusinessException e) {
throw new BpmnError("BusinessExceptionOccurred");
}
}
}构造函数的参数是错误代码。错误代码决定了处理这个错误的错误处理器。参见错误边界事件了解如何捕获BPMN错误。
这个机制只应该用于业务错误,需要通过流程中定义的错误边界事件或错误事件子流程处理。技术错误应该通过其他异常类型表现,并且通常不在流程内部处理。
异常映射
也可以使用mapException扩展,直接将Java异常映射至业务异常(错误)。单映射是最简单的形式:
<serviceTask id="servicetask1" name="Service Task" flowable:class="...">
<extensionElements>
<flowable:mapException
errorCode="myErrorCode1">org.flowable.SomeException</flowable:mapException>
</extensionElements>
</serviceTask>在上面的代码中,如果服务任务抛出org.flowable.SomeException的实例,引擎会捕获该异常,并将其转换为带有给定errorCode的BPMN错误。然后就可以像普通BPMN错误完全一样地处理。其他的异常没有映射,仍将抛出至API调用处。
也可以在单行中使用includeChildExceptions属性,映射特定异常的所有子异常。
<serviceTask id="servicetask1" name="Service Task" flowable:class="...">
<extensionElements>
<flowable:mapException errorCode="myErrorCode1"
includeChildExceptions="true">org.flowable.SomeException</flowable:mapException>
</extensionElements>
</serviceTask>上面的代码中,Flowable会将SomeException的任何直接或间接的子类,转换为带有指定错误代码的BPMN错误。
当未指定includeChildExceptions时,视为“false”。
默认映射最泛用。默认映射是一个不指定类的映射,可以匹配任何Java异常:
<serviceTask id="servicetask1" name="Service Task" flowable:class="...">
<extensionElements>
<flowable:mapException errorCode="myErrorCode1"/>
</extensionElements>
</serviceTask>除了默认映射,会按照从上至下的顺序检查映射,使用第一个匹配的映射。只在所有映射都不能成功匹配时使用默认映射。
只有第一个不指定类的映射会作为默认映射。默认映射忽略includeChildExceptions。
异常顺序流
也可以选择在发生异常时,将流程执行路由至另一条路径。下面是一个例子。
<serviceTask id="javaService"
name="Java service invocation"
flowable:class="org.flowable.ThrowsExceptionBehavior">
</serviceTask>
<sequenceFlow id="no-exception" sourceRef="javaService" targetRef="theEnd" />
<sequenceFlow id="exception" sourceRef="javaService" targetRef="fixException" />服务任务有两条出口顺序流,命名为exception与no-exception。在发生异常时,使用顺序流ID控制流程流向:
public class ThrowsExceptionBehavior implements ActivityBehavior {
public void execute(DelegateExecution execution) {
String var = (String) execution.getVariable("var");
String sequenceFlowToTake = null;
try {
executeLogic(var);
sequenceFlowToTake = "no-exception";
} catch (Exception e) {
sequenceFlowToTake = "exception";
}
DelegateHelper.leaveDelegate(execution, sequenceFlowToTake);
}
}在JavaDelegate中使用Flowable服务
有的时候,需要在Java服务任务中使用Flowable服务(例如调用活动(call activity)不满足需要的场景下,使用RuntimeService启动流程实例)。
public class StartProcessInstanceTestDelegate implements JavaDelegate {
public void execute(DelegateExecution execution) throws Exception {
RuntimeService runtimeService = Context.getProcessEngineConfiguration().getRuntimeService();
runtimeService.startProcessInstanceByKey("myProcess");
}
}可以使用这个接口访问所有Flowable服务API。
使用这些API调用造成的所有数据变更都在当前事务中。在依赖注入的环境(如Spring或CDI,无论是否使用启用JTA的数据源)下也可以使用这个接口。例如,下面的代码片段与上面的代码具有相同功能,但通过注入而不是org.flowable.engine.EngineServices接口获得RuntimeService。
@Component("startProcessInstanceDelegate")
public class StartProcessInstanceTestDelegateWithInjection {
@Autowired
private RuntimeService runtimeService;
public void startProcess() {
runtimeService.startProcessInstanceByKey("oneTaskProcess");
}
}重要技术提示:由于服务调用是在当前事务中完成的,因此在服务任务执行前产生或修改的数据尚未存入数据库。所有API调用都基于数据库数据处理,这意味着这些未提交的修改在服务任务的API调用中“不可见”。
8.5.4. Web服务任务
描述
Web服务任务(Web service task)用于同步地调用外部的Web服务。
图示
Web服务任务与Java服务任务图标一样。

XML表示
使用Web服务之前,需要导入其操作及复杂的类型。可以使用导入标签(import tag)指向Web服务的WSDL,自动处理:
<import importType="http://schemas.xmlsoap.org/wsdl/"
location="http://localhost:63081/counter?wsdl"
namespace="http://webservice.flowable.org/" />按照上面的声明,Flowable会导入定义,但不会创建条目定义(item definition)与消息。如果需要调用一个名为’prettyPrint’的方法,则需要先为请求及回复消息创建对应的消息与条目定义:
<message id="prettyPrintCountRequestMessage" itemRef="tns:prettyPrintCountRequestItem" />
<message id="prettyPrintCountResponseMessage" itemRef="tns:prettyPrintCountResponseItem" />
<itemDefinition id="prettyPrintCountRequestItem" structureRef="counter:prettyPrintCount" />
<itemDefinition id="prettyPrintCountResponseItem" structureRef="counter:prettyPrintCountResponse" />在声明服务任务前,需要定义实际引用Web服务的BPMN接口与操作。基本上,是定义“接口”与所需的“操作”。对每一个操作都可以重复使用之前定义的“传入”与“传出”消息。例如,下面的声明定义了“counter”接口及“prettyPrintCountOperation”操作:
<interface name="Counter Interface" implementationRef="counter:Counter">
<operation id="prettyPrintCountOperation" name="prettyPrintCount Operation"
implementationRef="counter:prettyPrintCount">
<inMessageRef>tns:prettyPrintCountRequestMessage</inMessageRef>
<outMessageRef>tns:prettyPrintCountResponseMessage</outMessageRef>
</operation>
</interface>这样就可以使用##WebService实现,声明Web服务任务,并引用Web服务操作。
<serviceTask id="webService"
name="Web service invocation"
implementation="##WebService"
operationRef="tns:prettyPrintCountOperation">Web服务任务IO规范
除非使用简化方法处理输入与输出数据关联(见下),否则需要为每个Web服务任务声明IO规范,指出任务的输入与输出是什么。这个方法很简单,也兼容BPMN 2.0。在prettyPrint例子中,根据之前声明的条目定义,定义输入与输出:
<ioSpecification>
<dataInput itemSubjectRef="tns:prettyPrintCountRequestItem" id="dataInputOfServiceTask" />
<dataOutput itemSubjectRef="tns:prettyPrintCountResponseItem" id="dataOutputOfServiceTask" />
<inputSet>
<dataInputRefs>dataInputOfServiceTask</dataInputRefs>
</inputSet>
<outputSet>
<dataOutputRefs>dataOutputOfServiceTask</dataOutputRefs>
</outputSet>
</ioSpecification>Web服务任务数据输入关联
有两种指定数据输入关联的方式:
-
使用表达式
-
使用简化方法
使用表达式指定数据输入关联,需要定义源及目标条目,并指定每个条目与字段的关联。下面的例子中,我们针对每个条目,指定prefix与suffix字段:
<dataInputAssociation>
<sourceRef>dataInputOfProcess</sourceRef>
<targetRef>dataInputOfServiceTask</targetRef>
<assignment>
<from>${dataInputOfProcess.prefix}</from>
<to>${dataInputOfServiceTask.prefix}</to>
</assignment>
<assignment>
<from>${dataInputOfProcess.suffix}</from>
<to>${dataInputOfServiceTask.suffix}</to>
</assignment>
</dataInputAssociation>也可以使用更简单明了的简化方法。'sourceRef’元素是一个Flowable变量名,'targetRef’是条目定义的参数。在下面的例子里,将’PrefixVariable’变量的值关联至’prefix’字段,并将’SuffixVariable’变量的值关联至’suffix’字段。
<dataInputAssociation>
<sourceRef>PrefixVariable</sourceRef>
<targetRef>prefix</targetRef>
</dataInputAssociation>
<dataInputAssociation>
<sourceRef>SuffixVariable</sourceRef>
<targetRef>suffix</targetRef>
</dataInputAssociation>Web服务任务数据输出关联
有两种指定数据输出关联的方式:
-
使用表达式
-
使用简化方法
使用表达式指定数据输出关联,需要定义目标变量及源表达式。这种方法很简单,与数据输入关联类似:
<dataOutputAssociation>
<targetRef>dataOutputOfProcess</targetRef>
<transformation>${dataOutputOfServiceTask.prettyPrint}</transformation>
</dataOutputAssociation>也可以使用更简单明了的简化方法。'sourceRef’是条目定义的参数,'targetRef’元素是Flowable变量名。这种方法很简单,与数据输入关联类似:
<dataOutputAssociation>
<sourceRef>prettyPrint</sourceRef>
<targetRef>OutputVariable</targetRef>
</dataOutputAssociation>8.5.5. 业务规则任务
描述
业务规则任务(business rule task)用于同步地执行一条或多条规则。Flowable使用名为Drools Expert的Drools规则引擎执行业务规则。目前,业务规则中包含的.drl文件,必须与定义了业务规则服务并执行规则的流程定义一起部署。这意味着流程中使用的所有.drl文件都需要打包在流程BAR文件中,与任务表单等类似。要了解如何为Drools Expert创建业务规则,请访问位于JBoss Drools的Drools文档。
如果想要使用自己的规则任务实现,比如希望通过不同方法使用Drools,或者想使用完全不同的规则引擎,则可以使用BusinessRuleTask的class或expression属性。这样它会与服务任务的行为完全相同。
图示
业务规则任务显示为带有表格图标的圆角矩形。

XML表示
要执行与流程定义在同一个BAR文件中部署的一条或多条业务规则,需要定义输入与结果变量。输入变量可以用流程变量的列表定义,使用逗号分隔。输出变量只能有一个变量名,将执行业务规则后的输出对象存储至流程变量。请注意结果变量会包含对象的List。如果没有指定结果变量名,默认为org.flowable.engine.rules.OUTPUT。
下面的业务规则任务,执行与流程定义一起部署的所有业务规则:
<process id="simpleBusinessRuleProcess">
<startEvent id="theStart" />
<sequenceFlow sourceRef="theStart" targetRef="businessRuleTask" />
<businessRuleTask id="businessRuleTask" flowable:ruleVariablesInput="${order}"
flowable:resultVariable="rulesOutput" />
<sequenceFlow sourceRef="businessRuleTask" targetRef="theEnd" />
<endEvent id="theEnd" />
</process>也可以将业务规则任务配置为只执行部署的.drl文件中的一组规则。要做到这一点,需要指定规则名字的列表,用逗号分隔。
<businessRuleTask id="businessRuleTask" flowable:ruleVariablesInput="${order}"
flowable:rules="rule1, rule2" />这样只会执行rule1与rule2。
也可以定义需要从执行中排除的规则列表。
<businessRuleTask id="businessRuleTask" flowable:ruleVariablesInput="${order}"
flowable:rules="rule1, rule2" exclude="true" />这个例子中,除了rule1与rule2之外,其它所有与流程定义一起部署在同一个BAR文件中的规则都会被执行。
前面提到过,还可以自行指定BusinessRuleTask的实现:
<businessRuleTask id="businessRuleTask" flowable:class="${MyRuleServiceDelegate}" />这样配置的业务规则任务与服务任务的行为完全一样,但仍保持业务规则任务的图标,代表在这里处理业务规则。
8.5.6. 邮件任务
Flowable让你可以通过自动的邮件服务任务(email task),增强业务流程。可以向一个或多个收信人发送邮件,支持cc,bcc,HTML文本,等等。请注意邮件任务不是BPMN 2.0规范的“官方”任务(所以也没有专用图标)。因此,在Flowable中,邮件任务实现为一种特殊的服务任务。
配置邮件服务器
Flowable引擎使用支持SMTP的外部邮件服务器发送邮件。为了发送邮件,引擎需要了解如何连接邮件服务器。可以在flowable.cfg.xml配置文件中设置下面的参数:
| 参数 | 必填? | 描述 |
|---|---|---|
mailServerHost |
否 |
邮件服务器的主机名(如mail.mycorp.com)。默认为 |
mailServerPort |
是,如果不使用默认端口 |
邮件服务器的SMTP端口。默认值为25 |
mailServerDefaultFrom |
否 |
若用户没有提供地址,默认使用的邮件发件人地址。默认为flowable@localhost_ |
mailServerUsername |
若服务器需要 |
部分邮件服务器发信时需要进行认证。默认为空。 |
mailServerPassword |
若服务器需要 |
部分邮件服务器发信时需要进行认证。默认为空。 |
mailServerUseSSL |
若服务器需要 |
部分邮件服务器要求ssl通信。默认设置为false。 |
mailServerUseTLS |
若服务器需要 |
部分邮件服务器要求TLS通信(例如gmail)。默认设置为false。 |
定义邮件任务
邮件任务实现为特殊的服务任务,将服务任务的type定义为'mail'进行设置。
<serviceTask id="sendMail" flowable:type="mail">邮件任务通过字段注入配置。这些参数的值可以使用EL表达式,并将在流程执行运行时解析。可以设置下列参数:
| 参数 | 必填? | 描述 |
|---|---|---|
to |
是 |
邮件的收信人。可以使用逗号分隔的列表定义多个接收人 |
from |
否 |
邮件的发信人地址。如果不设置,会使用默认配置的地址 |
subject |
否 |
邮件的主题 |
cc |
否 |
邮件的抄送人。可以使用逗号分隔的列表定义多个接收人 |
bcc |
否 |
邮件的密送人。可以使用逗号分隔的列表定义多个接收人 |
charset |
否 |
可以指定邮件的字符集,对许多非英语语言很必要。 |
html |
否 |
邮件的HTML文本 |
text |
否 |
邮件的内容,用于纯文本邮件。对于不支持富文本内容的客户端,可以与html一起使用。邮件客户端可以回退为显式纯文本格式。 |
htmlVar |
否 |
存储邮件HTML内容的流程变量名。与html参数的最大区别,是这个参数会在邮件任务发送前,使用其内容进行表达式替换。 |
textVar |
否 |
存储邮件纯文本内容的流程变量名。与text参数的最大区别,是这个参数会在邮件任务发送前,使用其内容进行表达式替换。 |
ignoreException |
否 |
处理邮件失败时,是忽略还是抛出FlowableException。默认设置为false。 |
exceptionVariableName |
否 |
如果设置ignoreException = true,而处理邮件失败时,则使用给定名字的变量保存失败信息 |
示例 usage
下面的XML代码片段是使用邮件任务的示例。
<serviceTask id="sendMail" flowable:type="mail">
<extensionElements>
<flowable:field name="from" stringValue="order-shipping@thecompany.com" />
<flowable:field name="to" expression="${recipient}" />
<flowable:field name="subject" expression="Your order ${orderId} has been shipped" />
<flowable:field name="html">
<flowable:expression>
<![CDATA[
<html>
<body>
Hello ${male ? 'Mr.' : 'Mrs.' } ${recipientName},<br/><br/>
As of ${now}, your order has been <b>processed and shipped</b>.<br/><br/>
Kind regards,<br/>
TheCompany.
</body>
</html>
]]>
</flowable:expression>
</flowable:field>
</extensionElements>
</serviceTask>8.5.7. Http任务
Http任务(Http task)用于发出HTTP请求,增强了Flowable的集成能力。请注意Http任务不是BPMN 2.0规范的“官方”任务(所以也没有专用图标)。因此,在Flowable中,Http任务实现为一种特殊的服务任务。
配置Http客户端
Flowable使用可配置的Http客户端发出Http请求。如果不进行设置,会使用默认配置。
示例配置:
<bean id="processEngineConfiguration"
class="org.flowable.engine.impl.cfg.StandaloneProcessEngineConfiguration">
<!-- http客户端配置 -->
<property name="httpClientConfig" ref="httpClientConfig"/>
</bean>
<bean id="httpClientConfig" class="org.flowable.engine.cfg.HttpClientConfig">
<property name="connectTimeout" value="5000"/>
<property name="socketTimeout" value="5000"/>
<property name="connectionRequestTimeout" value="5000"/>
<property name="requestRetryLimit" value="5"/>
</bean>| 参数 | 必填? | 描述 |
|---|---|---|
connectTimeout |
否 |
连接超时时间,以毫秒计。 |
socketTimeout |
否 |
Socket超时时间,以毫秒计。 |
connectionRequestTimeout |
否 |
请求连接超时时间。以毫秒计 |
requestRetryLimit |
否 |
请求重试次数(“0”代表不重试) |
disableCertVerify |
否 |
禁用SSL证书验证。 |
定义Http任务
Http任务实现为特殊的服务任务,将服务任务的type定义为'http'进行设置。
<serviceTask id="httpGet" flowable:type="http">可以使用自定义的实现,覆盖Http任务的默认行为。 需要扩展org.flowable.http.HttpActivityBehavior,并覆盖perform()方法。
需要在任务定义中设置httpActivityBehaviorClass字段(默认值为 org.flowable.http.impl.HttpActivityBehaviorImpl)。
当前使用的默认实现HttpActivityBehaviorImpl基于Apache Http Client。尽管Apache Http Client可以使用很多方法自定义,但我们并没有在Http客户端配置中使用全部选项。
参考 Http Client builder 创建自定义客户端。
<serviceTask id="httpGet" flowable:type="http">
<extensionElements>
<flowable:field name="httpActivityBehaviorClass">
<flowable:string>
<![CDATA[org.example.flowable.HttpActivityBehaviorCustomImpl]]>
</flowable:string>
</flowable:field>
</extensionElements>
</serviceTask>
配置Http任务
Http任务通过字段注入配置。所有参数都可以配置为EL表达式,在运行时进行解析。可以设置下列参数:
| 参数 | 必填? | 描述 |
|---|---|---|
requestMethod |
是 |
请求方法 |
requestUrl |
yes |
请求URL |
requestHeaders |
否 |
行分隔的Http请求头。 |
requestBody |
否 |
请求体 |
requestTimeout |
否 |
请求超时时间。单位为毫秒 |
disallowRedirects |
否 |
是否禁用Http重定向。 |
failStatusCodes |
否 |
逗号分隔的Http状态码,将令请求失败并抛出FlowableException。 |
handleStatusCodes |
否 |
逗号分隔的Http状态码,将令任务抛出BpmnError,并可用错误边界事件捕获。 |
ignoreException |
否 |
是否忽略异常。异常将被捕获,并存储在名为<taskId>.errorMessage的变量中。 |
saveRequestVariables |
否 |
是否保存请求变量。 |
saveResponseParameters |
否 |
是否保存全部的响应变量,包括HTTP状态码,响应头等。 |
resultVariablePrefix |
否 |
执行变量名的前缀。 |
saveResponseParametersTransient |
否 |
若为true,则会将响应体变量(如果设置了保存响应头,状态码,也包括在内)设置为瞬时变量。 |
saveResponseVariableAsJson |
否 |
若为true,则响应体会保存为JSON变量,而非String。如果HTTP服务返回JSON,并且想使用点注记方式使用字段(如myResponse.user.name),这个配置就很有用。 |
httpActivityBehaviorClass |
否 |
org.flowable.http.HttpActivityBehavior类的自定义扩展的全限定类名。 |
除了上面提到的字段,使用saveResponseParameters还会在执行成功后设置下列变量。
| 变量 | 可选? | 描述 |
|---|---|---|
responseProtocol |
是 |
Http版本。 |
responseReason |
是 |
Http响应原因短语。 |
responseStatusCode |
是 |
Http响应状态码(例如 - 200)。 |
responseHeaders |
是 |
行分隔的Http响应头。 |
responseBody |
是 |
字符串形式的响应体,若有。 |
errorMessage |
是 |
被忽略的异常信息,若有。 |
结果变量
请注意上述执行变量名都会使用resultVariablePrefix前缀。 例如,可以在其他活动中,使用task7.responseStatusCode获取响应状态码。 其中task7是服务任务的id。可以设置resultVariablePrefix覆盖这个行为。
示例
下面的XML片段是使用Http任务的例子。
<serviceTask id="httpGet" flowable:type="http">
<extensionElements>
<flowable:field name="requestMethod" stringValue="GET" />
<flowable:field name="requestUrl" stringValue="http://flowable.org" />
<flowable:field name="requestHeaders">
<flowable:expression>
<![CDATA[
Accept: text/html
Cache-Control: no-cache
]]>
</flowable:expression>
</flowable:field>
<flowable:field name="requestTimeout">
<flowable:expression>
<![CDATA[
${requestTimeout}
]]>
</flowable:expression>
</flowable:field>
<flowable:field name="resultVariablePrefix">
<flowable:string>task7</flowable:string>
</flowable:field>
</extensionElements>
</serviceTask>错误处理
默认情况下,当发生链接、IO或其他未处理的异常时,Http任务抛出FlowableException。 默认情况下,不会处理任何重定向/客户端/服务端错误状态码。
可以设置failStatusCodes及/或handleStatusCodes字段,配置Http任务处理异常及Http状态的方式。参见配置Http任务。
由handleStatusCodes抛出的BpmnError与其他BPMN异常一样,需要由对应的错误边界事件处理。 下面是一些Http任务错误处理及重试的例子。
400及5XX失败,异步执行,并按照failedJobRetryTimeCycle重试的Http任务
<serviceTask id="failGet" name="Fail test" flowable:async="true" flowable:type="http">
<extensionElements>
<flowable:field name="requestMethod">
<flowable:string><![CDATA[GET]]></flowable:string>
</flowable:field>
<flowable:field name="requestUrl">
<flowable:string><![CDATA[http://localhost:9798/api/fail]]></flowable:string>
</flowable:field>
<flowable:field name="failStatusCodes">
<flowable:string><![CDATA[400, 5XX]]></flowable:string>
</flowable:field>
<flowable:failedJobRetryTimeCycle>R3/PT5S</flowable:failedJobRetryTimeCycle>
</extensionElements>
</serviceTask>将400处理为BmpnError
<serviceTask id="handleGet" name="HTTP Task" flowable:type="http">
<extensionElements>
<flowable:field name="requestMethod">
<flowable:string><![CDATA[GET]]></flowable:string>
</flowable:field>
<flowable:field name="requestUrl">
<flowable:string><![CDATA[http://localhost:9798/api/fail]]></flowable:string>
</flowable:field>
<flowable:field name="handleStatusCodes">
<flowable:string><![CDATA[4XX]]></flowable:string>
</flowable:field>
</extensionElements>
</serviceTask>
<boundaryEvent id="catch400" attachedToRef="handleGet">
<errorEventDefinition errorRef="HTTP400"></errorEventDefinition>
</boundaryEvent>忽略异常
<serviceTask id="ignoreTask" name="Fail test" flowable:type="http">
<extensionElements>
<flowable:field name="requestMethod">
<flowable:string><![CDATA[GET]]></flowable:string>
</flowable:field>
<flowable:field name="requestUrl">
<flowable:string><![CDATA[http://nohost:9798/api]]></flowable:string>
</flowable:field>
<flowable:field name="ignoreException">
<flowable:string><![CDATA[true]]></flowable:string>
</flowable:field>
</extensionElements>
</serviceTask>异常映射
参见异常映射
8.5.8. Mule任务
Mule任务可以向Mule发送消息,增强Flowable的集成特性。请注意Mule任务不是BPMN 2.0规范的“官方”任务(所以也没有专用图标)。因此,在Flowable中,Mule任务实现为一种特殊的服务任务。
定义Mule任务
Mule任务实现为特殊的服务任务,将服务任务的type定义为'mule'进行设置。
<serviceTask id="sendMule" flowable:type="mule">Mule任务通过字段注入配置。这些参数的值可以使用EL表达式,将在流程执行运行时解析。可以设置下列参数:
| 参数 | 必填? | 描述 |
|---|---|---|
endpointUrl |
是 |
希望调用的Mule端点(endpoint)。 |
language |
是 |
计算payloadExpression字段所用的语言。 |
payloadExpression |
是 |
消息载荷的表达式。 |
resultVariable |
否 |
存储调用结果的变量名。 |
示例
下面的XML代码片段是使用Mule任务的例子。
<extensionElements>
<flowable:field name="endpointUrl">
<flowable:string>vm://in</flowable:string>
</flowable:field>
<flowable:field name="language">
<flowable:string>juel</flowable:string>
</flowable:field>
<flowable:field name="payloadExpression">
<flowable:string>"hi"</flowable:string>
</flowable:field>
<flowable:field name="resultVariable">
<flowable:string>theVariable</flowable:string>
</flowable:field>
</extensionElements>8.5.9. Camel任务
Camel任务(Camel task)可以向Camel发送消息,增强Flowable的集成特性。请注意Camel任务不是BPMN 2.0规范的“官方”任务(所以也没有专用图标)。因此,在Flowable中,Camel任务实现为一种特殊的服务任务。还请注意,需要在项目中包含Flowable Camel模块才能使用Camel任务。
定义Camel任务
Camel任务实现为特殊的服务任务,将服务任务的type定义为'camel'进行设置。
<serviceTask id="sendCamel" flowable:type="camel">只需要在流程定义的服务任务上定义Camel类型即可。集成逻辑都通过Camel容器委托。默认情况下Flowable引擎在Spring容器中查找camelContext Bean。camelContext Bean定义由Camel容器装载的Camel路由。在下面的例子中,按照指定的Java包装载路由。但也可以自行在Spring配置中直接定义路由。
<camelContext id="camelContext" xmlns="http://camel.apache.org/schema/spring">
<packageScan>
<package>org.flowable.camel.route</package>
</packageScan>
</camelContext>可以在Camel网站找到关于Camel路由的更多文档。下面只通过几个小例子展示基本概念。在第一个例子中,在Flowable工作流中进行最简单的Camel调用。叫做SimpleCamelCall。
如果想要定义多个Camel上下文Bean,或想使用不同的Bean名字,可以在Camel任务定义中像这样覆盖:
<serviceTask id="serviceTask1" flowable:type="camel">
<extensionElements>
<flowable:field name="camelContext" stringValue="customCamelContext" />
</extensionElements>
</serviceTask>简单Camel调用示例
这个例子相关的所有文件,都可以在flowable-camel模块的org.flowable.camel.examples.simpleCamelCall包中找到。目标是简单地启动一个Camel路由。首先需要一个配置了上面提到的路由的Spring上下文。下面的代码实现这个目的:
<camelContext id="camelContext" xmlns="http://camel.apache.org/schema/spring">
<packageScan>
<package>org.flowable.camel.examples.simpleCamelCall</package>
</packageScan>
</camelContext>public class SimpleCamelCallRoute extends RouteBuilder {
@Override
public void configure() throws Exception {
from("flowable:SimpleCamelCallProcess:simpleCall").to("log:org.flowable.camel.examples.SimpleCamelCall");
}
}路由只是记录消息体,不做更多事情。请注意from端点(endpoint)的格式,包含冒号分隔的三个部分:
| 端点URL部分 | 描述 |
|---|---|
flowable |
指向引擎端点 |
SimpleCamelCallProcess |
流程名 |
simpleCall |
流程中Camel服务的名字 |
现在已经配置好路由,可以访问Camel。下面需要像这样定义工作流:
<process id="SimpleCamelCallProcess">
<startEvent id="start"/>
<sequenceFlow id="flow1" sourceRef="start" targetRef="simpleCall"/>
<serviceTask id="simpleCall" flowable:type="camel"/>
<sequenceFlow id="flow2" sourceRef="simpleCall" targetRef="end"/>
<endEvent id="end"/>
</process>连通性测试示例
示例已经可以工作,但实际上Camel与Flowable之间并没有通信,因此没有太多价值。在这个例子里,将试着从Camel接收与发送消息。我们将发送一个字符串,Camel在其上附加一些文字并返回作为结果。发送部分比较普通,即以变量的格式将信息发送给Camel服务。这是我们的调用代码:
@Deployment
public void testPingPong() {
Map<String, Object> variables = new HashMap<String, Object>();
variables.put("input", "Hello");
Map<String, String> outputMap = new HashMap<String, String>();
variables.put("outputMap", outputMap);
runtimeService.startProcessInstanceByKey("PingPongProcess", variables);
assertEquals(1, outputMap.size());
assertNotNull(outputMap.get("outputValue"));
assertEquals("Hello World", outputMap.get("outputValue"));
}“input”变量是实际上是Camel路由的输入,而outputMap用于捕获Camel传回的结果。流程像是这样:
<process id="PingPongProcess">
<startEvent id="start"/>
<sequenceFlow id="flow1" sourceRef="start" targetRef="ping"/>
<serviceTask id="ping" flowable:type="camel"/>
<sequenceFlow id="flow2" sourceRef="ping" targetRef="saveOutput"/>
<serviceTask id="saveOutput" flowable:class="org.flowable.camel.examples.pingPong.SaveOutput" />
<sequenceFlow id="flow3" sourceRef="saveOutput" targetRef="end"/>
<endEvent id="end"/>
</process>请注意SaveOutput服务任务会从上下文中取出“Output”变量,并存储至上面提到的OutputMap。现在需要了解变量如何发送至Camel,以及如何返回。这就需要了解Camel行为(Behavior)的概念。变量与Camel通信的方式可以通过CamelBehavior配置。在这个例子里使用默认配置,其它配置在后面会进行简短介绍。可以使用类似的代码配置期望的Camel行为:
<serviceTask id="serviceTask1" flowable:type="camel">
<extensionElements>
<flowable:field name="camelBehaviorClass" stringValue="org.flowable.camel.impl.CamelBehaviorCamelBodyImpl" />
</extensionElements>
</serviceTask>如果不指定行为,则会设置为org.flowable.camel.impl.CamelBehaviorDefaultImpl。这个行为会将变量复制到相同名字的Camel参数。无论选择什么行为,对于返回值:如果Camel消息体是一个map,则其中的每个元素都将复制为变量;否则整个对象将复制为名为"camelBody"的特定变量。以第二个例子作为Camel路由的总结:
@Override
public void configure() throws Exception {
from("flowable:PingPongProcess:ping").transform().simple("${property.input} World");
}在这个路由中,字符串"world"会在结尾连接上名为“input”的参数,并将结果作为消息体返回。可以通过Java服务任务访问"camelBody"变量。也可以访问“outputMap”获取。除了这个例子中使用的默认行为之外,我们还可以看看其他的方式。在每个Camel路由开始时,流程实例ID会复制为名为"PROCESS_ID_PROPERTY"的Camel参数。之后会用于将流程实例与Camel路由相关联。也可以在Camel路由中直接使用。
Flowable提供了三种不同的行为。可以通过修改路由URL中特定的部分覆写行为。这里有个在URL中覆写已有行为的例子:
from("flowable:asyncCamelProcess:serviceTaskAsync2?copyVariablesToProperties=true").下表展示了三种可用的Camel行为:
| 行为 | URL中 | 描述 |
|---|---|---|
CamelBehaviorDefaultImpl |
copyVariablesToProperties |
将Flowable变量复制为Camel参数。 |
CamelBehaviorCamelBodyImpl |
copyCamelBodyToBody |
只将名为"camelBody"的Flowable变量复制为Camel消息体。 |
CamelBehaviorBodyAsMapImpl |
copyVariablesToBodyAsMap |
将一个map中的所有Flowable变量复制为Camel消息体。 |
上表展示了Flowable变量如何传递给Camel。下表展示Camel变量如何返回至Flowable。需要在路由URL中进行配置。
| URL | 描述 |
|---|---|
Default |
如果Camel消息体是一个map,则将其中每一对象复制为Flowable变量;否则将整个Camel消息体复制为"camelBody" Flowable变量。 |
copyVariablesFromProperties |
将Camel参数以同名复制为Flowable变量。 |
copyCamelBodyToBodyAsString |
与default相同,但如果Camel消息体不是map,则首先将其转换为字符串,然后再复制为"camelBody"。 |
copyVariablesFromHeader |
额外地,将Camel头复制为Flowable的同名变量。 |
返回变量
上面提到的变量传递,不论是从Camel到Flowable还是反向,都只用于变量传递的起始侧。
要特别注意,由于Flowable的行为是非阻塞的,Flowable不会自动向Camel返回变量。
为此提供了特殊的语法。可以在Camel路由URL中,以var.return.someVariableName的格式,指定一个或多个参数。与这些参数同名(但没有var.return部分)的变量会作为输出变量。因此将会以相同的名字复制回Camel参数。
例如在如下路由中:
from("direct:start").to("flowable:process?var.return.exampleVar").to("mock:result");
名为exampleVar的Flowable变量会作为输出变量。因此会以同名复制回Camel参数。
异步连通性测试示例
上面的例子全都是同步的。流程实例等待,直到Camel路由结束并返回。有时,需要Flowable流程实例继续运行。这时可以使用Camel服务任务的异步功能。可以将Camel服务任务的async参数设置为true,启用这个功能。
<serviceTask id="serviceAsyncPing" flowable:type="camel" flowable:async="true"/>设置这个参数后,Camel路由会由Flowable作业执行器异步启动。如果在Camel路由中定义了队列,Flowable流程实例会继续执行流程定义中Camel服务任务之后的活动。Camel路由会与流程执行完全异步地执行。如果需要在流程定义的某处等待Camel服务任务的响应,可以使用接收任务(receive task)。
<receiveTask id="receiveAsyncPing" name="Wait State" />流程实例会等待,直到接收到来自Camel的信号。可以在Camel中向特定的Flowable端点发送消息,来为流程实例发送信号。
from("flowable:asyncPingProcess:serviceAsyncPing").to("flowable:asyncPingProcess:receiveAsyncPing");-
“flowable”字符串常量
-
流程名
-
接收任务名
使用Camel路由实例化工作流
上面的例子都是先启动Flowable流程实例,然后在流程实例中启动Camel路由。也可以反过来,在已经启动的Camel路由中启动或调用流程实例。类似于为接收任务发送消息。例如,一个简单的路由:
from("direct:start").to("flowable:camelProcess");可以看到,URL包含两部分:第一部分是“flowable”字符串常量,第二部分是流程定义的名字。当然,需要提前在Flowable引擎中部署这个流程定义。
也可以在Camel头中,将流程实例起动人设置为某个已认证用户ID。为此,首先需要在流程定义中指定启动人变量:
<startEvent id="start" flowable:initiator="initiator" />然后使用Camel头CamelProcessInitiatorHeader指定用户ID。Camel路由定义如下:
from("direct:startWithInitiatorHeader")
.setHeader("CamelProcessInitiatorHeader", constant("kermit"))
.to("flowable:InitiatorCamelCallProcess?processInitiatorHeaderName=CamelProcessInitiatorHeader");8.5.10. 手动任务
描述
手动任务(manual task)定义在BPM引擎之外的任务。它用于建模引擎不需要了解,也不需要提供系统或用户界面的工作。对于引擎来说,手动任务将按直接穿过活动处理,在流程执行到达手动任务时,自动继续执行流程。
图示
手动任务用左上角有一个小“手”图标的标准BPMN 2.0任务(圆角矩形)表示。

XML表示
<manualTask id="myManualTask" name="Call client for more information" />8.5.11. Java接收任务
描述
接收任务(receive task),是等待特定消息到达的简单任务。目前,我们只为这个任务实现了Java语义。当流程执行到达接收任务时,流程状态将提交至持久化存储。这意味着流程将保持等待状态,直到引擎接收到特定的消息,触发流程穿过接收任务继续执行。
图示
接收任务用左上角有一个消息图标的标准BPMN 2.0任务(圆角矩形)表示。消息图标是白色的(对应的黑色消息图标代表发送的含义)。
XML表示
<receiveTask id="waitState" name="wait" />要使流程实例从接收任务的等待状态中继续执行,需要使用到达接收任务的执行id,调用runtimeService.signal(executionId)。下面的代码片段展示了如何操作:
ProcessInstance pi = runtimeService.startProcessInstanceByKey("receiveTask");
Execution execution = runtimeService.createExecutionQuery()
.processInstanceId(pi.getId())
.activityId("waitState")
.singleResult();
assertNotNull(execution);
runtimeService.trigger(execution.getId());8.5.12. Shell任务
描述
Shell任务(Shell task)可以运行Shell脚本与命令。请注意Shell任务不是BPMN 2.0规范的“官方”任务(因此也没有专用图标)。
定义Shell任务
Shell任务实现为特殊的服务任务,将服务任务的type定义为'shell'进行设置。
<serviceTask id="shellEcho" flowable:type="shell">Shell任务通过字段注入配置。这些参数的值可以使用EL表达式,将在流程执行运行时解析。可以设置下列参数:
| 参数 | 必填? | 类型 | 描述 | 默认值 |
|---|---|---|---|---|
command |
是 |
String |
要执行的Shell命令。 |
|
arg1-5 |
否 |
String |
参数1至参数5 |
|
wait |
否 |
true/false |
是否等待Shell进程终止。 |
true |
redirectError |
否 |
true/false |
是否将标准错误(standard error)并入标准输出(standard output)。 |
false |
cleanEnv |
否 |
true/false |
是否避免Shell进程继承当前环境。 |
false |
outputVariable |
否 |
String |
保存输出的变量名 |
不会记录输出。 |
errorCodeVariable |
否 |
String |
保存结果错误码的变量名 |
不会记录错误码。 |
directory |
否 |
String |
Shell进程的默认目录 |
当前目录 |
示例
下面的XML代码片段是使用Shell任务的例子。将会运行"cmd /c echo EchoTest" Shell脚本,等待其结束,并将其结果存入resultVar。
<serviceTask id="shellEcho" flowable:type="shell" >
<extensionElements>
<flowable:field name="command" stringValue="cmd" />
<flowable:field name="arg1" stringValue="/c" />
<flowable:field name="arg2" stringValue="echo" />
<flowable:field name="arg3" stringValue="EchoTest" />
<flowable:field name="wait" stringValue="true" />
<flowable:field name="outputVariable" stringValue="resultVar" />
</extensionElements>
</serviceTask>8.5.13. 执行监听器
执行监听器(execution listener)可以在流程执行中发生特定的事件时,执行外部Java代码或计算表达式。可以被捕获的事件有:
-
流程实例的启动和结束。
-
流程执行转移。
-
活动的启动和结束。
-
网关的启动和结束。
-
中间事件的启动和结束。
-
启动事件的结束,和结束事件的启动。
下面的流程定义包含了三个执行监听器:
<process id="executionListenersProcess">
<extensionElements>
<flowable:executionListener
class="org.flowable.examples.bpmn.executionlistener.ExampleExecutionListenerOne"
event="start" />
</extensionElements>
<startEvent id="theStart" />
<sequenceFlow sourceRef="theStart" targetRef="firstTask" />
<userTask id="firstTask" />
<sequenceFlow sourceRef="firstTask" targetRef="secondTask">
<extensionElements>
<flowable:executionListener
class="org.flowable.examples.bpmn.executionListener.ExampleExecutionListenerTwo" />
</extensionElements>
</sequenceFlow>
<userTask id="secondTask" >
<extensionElements>
<flowable:executionListener
expression="${myPojo.myMethod(execution.event)}"
event="end" />
</extensionElements>
</userTask>
<sequenceFlow sourceRef="secondTask" targetRef="thirdTask" />
<userTask id="thirdTask" />
<sequenceFlow sourceRef="thirdTask" targetRef="theEnd" />
<endEvent id="theEnd" />
</process>第一个执行监听器将在流程启动时收到通知。这个监听器是一个外部Java类(ExampleExecutionListenerOne),并且需要实现org.flowable.engine.delegate.ExecutionListener接口。当该事件发生时(这里是start事件),会调用notify(ExecutionListenerExecution execution)方法。
public class ExampleExecutionListenerOne implements ExecutionListener {
public void notify(ExecutionListenerExecution execution) throws Exception {
execution.setVariable("variableSetInExecutionListener", "firstValue");
execution.setVariable("eventReceived", execution.getEventName());
}
}也可以使用实现了org.flowable.engine.delegate.JavaDelegate接口的委托类。这些委托类也可以用于其他的结构,如服务任务的委托。
第二个执行监听器在流程执行转移时被调用。请注意listener元素并未定义event,因为在转移上只会触发take事件。当监听器定义在转移上时,event属性的值将被忽略。
最后一个执行监听器在secondTask活动结束时被调用。监听器声明中没有使用class,而是定义了expression。这个表达式将在事件触发时计算/调用。
<flowable:executionListener expression="${myPojo.myMethod(execution.eventName)}" event="end" />与其他表达式一样,可以使用与解析execution变量。execution对象提供了露事件名参数,可以使用execution.eventName向你的方法传递事件名。
与服务任务类似,执行监听器也支持使用delegateExpression。
<flowable:executionListener event="start" delegateExpression="${myExecutionListenerBean}" />较早之前,我们也引入了新的执行监听器类型,org.flowable.engine.impl.bpmn.listener.ScriptExecutionListener。这个脚本执行监听器可以为执行监听器事件执行一段脚本代码。
<flowable:executionListener event="start"
class="org.flowable.engine.impl.bpmn.listener.ScriptExecutionListener">
<flowable:field name="script">
<flowable:string>
def bar = "BAR"; // 局部变量
foo = "FOO"; // 将变量放入执行上下文
execution.setVariable("var1", "test"); // 测试访问执行实例
bar // 隐式返回值
</flowable:string>
</flowable:field>
<flowable:field name="language" stringValue="groovy" />
<flowable:field name="resultVariable" stringValue="myVar" />
</flowable:executionListener>执行监听器上的字段注入
使用通过class属性配置的执行监听器时,可以使用字段注入。与服务任务字段注入使用完全相同的机制,可以在那里看到字段注入的各种用法。
下面的代码片段展示了一个简单的示例流程,带有一个使用了字段注入的执行监听器。
<process id="executionListenersProcess">
<extensionElements>
<flowable:executionListener
class="org.flowable.examples.bpmn.executionListener.ExampleFieldInjectedExecutionListener"
event="start">
<flowable:field name="fixedValue" stringValue="Yes, I am " />
<flowable:field name="dynamicValue" expression="${myVar}" />
</flowable:executionListener>
</extensionElements>
<startEvent id="theStart" />
<sequenceFlow sourceRef="theStart" targetRef="firstTask" />
<userTask id="firstTask" />
<sequenceFlow sourceRef="firstTask" targetRef="theEnd" />
<endEvent id="theEnd" />
</process>public class ExampleFieldInjectedExecutionListener implements ExecutionListener {
private Expression fixedValue;
private Expression dynamicValue;
public void notify(ExecutionListenerExecution execution) throws Exception {
execution.setVariable("var", fixedValue.getValue(execution).toString() +
dynamicValue.getValue(execution).toString());
}
}ExampleFieldInjectedExecutionListener类将连接两个字段(一个是固定值-fixedValue,另一个是动态值-dynamicValue),并将其存储在'var'流程变量中。
@Deployment(resources = {
"org/flowable/examples/bpmn/executionListener/ExecutionListenersFieldInjectionProcess.bpmn20.xml"})
public void testExecutionListenerFieldInjection() {
Map<String, Object> variables = new HashMap<String, Object>();
variables.put("myVar", "listening!");
ProcessInstance processInstance = runtimeService.startProcessInstanceByKey(
"executionListenersProcess", variables);
Object varSetByListener = runtimeService.getVariable(processInstance.getId(), "var");
assertNotNull(varSetByListener);
assertTrue(varSetByListener instanceof String);
// 结果为固定注入字段及注入表达式的连接
assertEquals("Yes, I am listening!", varSetByListener);
}请注意,与服务任务使用相同的线程安全规则。请阅读相应章节了解更多信息。
8.5.14. 任务监听器
任务监听器(task listener)用于在特定的任务相关事件发生时,执行自定义的Java逻辑或表达式。
任务监听器只能在流程定义中作为用户任务的子元素。请注意,任务监听器是一个Flowable自定义结构,因此也需要作为BPMN 2.0 extensionElements,放在flowable命名空间下。
<userTask id="myTask" name="My Task" >
<extensionElements>
<flowable:taskListener event="create" class="org.flowable.MyTaskCreateListener" />
</extensionElements>
</userTask>任务监听器包含下列属性:
-
event(事件)(必填):触发任务监听器的任务事件类型。可用的事件有:
-
create(创建):当任务已经创建,并且所有任务参数都已经设置时触发。
-
assignment(指派):当任务已经指派给某人时触发。请注意:当流程执行到达用户任务时,在触发create事件之前,会首先触发assignment事件。这顺序看起来不太自然,但是有实际原因的:当收到create事件时,我们通常希望能看到任务的所有参数,包括办理人。
-
complete(完成):当任务已经完成,从运行时数据中删除前触发。
-
delete(删除):在任务即将被删除前触发。请注意任务由completeTask正常完成时也会触发。
-
-
class:需要调用的委托类。这个类必须实现
org.flowable.task.service.delegate.TaskListener接口。
public class MyTaskCreateListener implements TaskListener {
public void notify(DelegateTask delegateTask) {
// 这里是要实现的业务逻辑
}
}也可以使用字段注入,为委托类传递流程变量或执行。请注意委托类的实例在流程部署时创建(与Flowable中其它的委托类一样),这意味着该实例会在所有流程实例执行中共享。
-
expression:(不能与class属性一起使用):指定在事件发生时要执行的表达式。可以为被调用的对象传递
DelegateTask对象与事件名(使用task.eventName)作为参数。
<flowable:taskListener event="create" expression="${myObject.callMethod(task, task.eventName)}" />-
delegateExpression:指定一个能够解析为
TaskListener接口实现类的对象的表达式。与服务任务类似。
<flowable:taskListener event="create" delegateExpression="${myTaskListenerBean}" />-
较早之前,我们也引入了新的执行监听器类型,org.flowable.engine.impl.bpmn.listener.ScriptTaskListener。这个脚本任务监听器可以为一个任务监听器事件执行一段脚本代码。
<flowable:taskListener event="complete" class="org.flowable.engine.impl.bpmn.listener.ScriptTaskListener" >
<flowable:field name="script">
<flowable:string>
def bar = "BAR"; // 局部变量
foo = "FOO"; // 将变量放入执行上下文
task.setOwner("kermit"); // 测试访问任务实例
bar // 隐式返回值
</flowable:string>
</flowable:field>
<flowable:field name="language" stringValue="groovy" />
<flowable:field name="resultVariable" stringValue="myVar" />
</flowable:taskListener>8.5.15. 多实例(for each)
描述
多实例活动(multi-instance activity)是在业务流程中,为特定步骤定义重复的方式。在编程概念中,多实例类似for each结构:可以为给定集合中的每一条目,顺序或并行地,执行特定步骤,甚至是整个子流程。
多实例是一个普通活动,加上定义(被称作“多实例特性的”)额外参数,会使得活动在运行时被多次执行。下列活动可以成为多实例活动:
按照BPMN2.0规范的要求,用于为每个实例创建执行的父执行,会提供下列变量:
-
nrOfInstances:实例总数。
-
nrOfActiveInstances:当前活动的(即未完成的),实例数量。对于顺序多实例,这个值总为1。
-
nrOfCompletedInstances:已完成的实例数量。
可以调用execution.getVariable(x)方法获取这些值。
另外,每个被创建的执行,都有局部变量(对其他执行不可见,也不存储在流程实例级别):
-
loopCounter:给定实例在for-each循环中的index。可以通过Flowable的elementIndexVariable属性为loopCounter变量重命名。
图示
如果一个活动是多实例,将通过在该活动底部的三条短线表示。三条竖线代表实例会并行执行,而三条横线代表顺序执行。
XML表示
要将活动变成多实例,该活动的XML元素必须有multiInstanceLoopCharacteristics子元素
<multiInstanceLoopCharacteristics isSequential="false|true">
...
</multiInstanceLoopCharacteristics>isSequential属性代表了活动的实例为顺序还是并行执行。
实例的数量在进入活动时,计算一次。有几种不同方法可以配置数量。一个方法是通过loopCardinality子元素,直接指定数字。
<multiInstanceLoopCharacteristics isSequential="false|true">
<loopCardinality>5</loopCardinality>
</multiInstanceLoopCharacteristics>也可以使用解析为正整数的表达式:
<multiInstanceLoopCharacteristics isSequential="false|true">
<loopCardinality>${nrOfOrders-nrOfCancellations}</loopCardinality>
</multiInstanceLoopCharacteristics>另一个定义实例数量的方法,是使用loopDataInputRef子元素,指定一个集合型流程变量的名字。对集合中的每一项,都会创建一个实例。可以使用inputDataItem子元素,将该项设置给该实例的局部变量。在下面的XML示例中展示:
<userTask id="miTasks" name="My Task ${loopCounter}" flowable:assignee="${assignee}">
<multiInstanceLoopCharacteristics isSequential="false">
<loopDataInputRef>assigneeList</loopDataInputRef>
<inputDataItem name="assignee" />
</multiInstanceLoopCharacteristics>
</userTask>假设变量assigneeList包含[kermit, gonzo, fozzie]。上面的代码会创建三个并行的用户任务。每一个执行都有一个名为assignee的(局部)流程变量,含有集合中的一项,并在这个例子中被用于指派用户任务。
loopDataInputRef与inputDataItem的缺点是名字很难记,并且由于BPMN 2.0概要的限制,不能使用表达式。Flowable通过在multiInstanceCharacteristics上提供collection与elementVariable属性解决了这些问题:
<userTask id="miTasks" name="My Task" flowable:assignee="${assignee}">
<multiInstanceLoopCharacteristics isSequential="true"
flowable:collection="${myService.resolveUsersForTask()}" flowable:elementVariable="assignee" >
</multiInstanceLoopCharacteristics>
</userTask>请注意collection属性会作为表达式进行解析。如果表达式解析为字符串而不是一个集合,不论是因为本身配置的就是静态字符串值,还是表达式计算结果为字符串,这个字符串都会被当做变量名,在流程变量中用于获取实际的集合。
例如,下面的代码片段会要求集合存储在assigneeList流程变量中:
<userTask id="miTasks" name="My Task" flowable:assignee="${assignee}">
<multiInstanceLoopCharacteristics isSequential="true"
flowable:collection="assigneeList" flowable:elementVariable="assignee" >
</multiInstanceLoopCharacteristics>
</userTask>假如myService.getCollectionVariableName()返回字符串值,引擎就会用这个值作为变量名,获取流程变量保存的集合。
<userTask id="miTasks" name="My Task" flowable:assignee="${assignee}">
<multiInstanceLoopCharacteristics isSequential="true"
flowable:collection="${myService.getCollectionVariableName()}" flowable:elementVariable="assignee" >
</multiInstanceLoopCharacteristics>
</userTask>多实例活动在所有实例都完成时结束。然而,也可以指定一个表达式,在每个实例结束时进行计算。当表达式计算为true时,将销毁所有剩余的实例,并结束多实例活动,继续执行流程。这个表达式必须通过completionCondition子元素定义。
<userTask id="miTasks" name="My Task" flowable:assignee="${assignee}">
<multiInstanceLoopCharacteristics isSequential="false"
flowable:collection="assigneeList" flowable:elementVariable="assignee" >
<completionCondition>${nrOfCompletedInstances/nrOfInstances >= 0.6 }</completionCondition>
</multiInstanceLoopCharacteristics>
</userTask>在这个例子里,会为assigneeList集合中的每个元素创建并行实例。当60%的任务完成时,其他的任务将被删除,流程继续运行。
边界事件与多实例
多实例是普通活动,因此可以在其边界定义边界事件。如果是中断边界事件,当其捕获事件时,会销毁活动中的所有实例。以下面的多实例子流程为例:
当定时器触发时,子流程的所有实例都会被销毁,无论有多少实例,或者实例的内部活动是否完成。
多实例与执行监听器
执行监听器与多实例一起使用时需要特别注意。以下面的BPMN 2.0 XML代码片段为例。这段XML定义在与multiInstanceLoopCharacteristics XML元素相同的级别:
<extensionElements>
<flowable:executionListener event="start" class="org.flowable.MyStartListener"/>
<flowable:executionListener event="end" class="org.flowable.MyEndListener"/>
</extensionElements>对于普通的BPMN活动,会在活动开始与结束时调用一次监听器。
但是当该活动为多实例时,行为有区别:
-
当进入多实例活动时,在任何内部活动执行前,抛出一个启动事件。loopCounter变量还未设置(为null)。
-
进入每个实际执行的活动时,抛出一个启动事件。loopCounter变量已经设置。
结束事件类似:
-
离开每个实际执行的活动后,抛出一个结束事件。loopCounter变量已经设置。
-
多实例活动整体完成后,抛出一个结束事件。loopCounter变量未设置。
例如:
<subProcess id="subprocess1" name="Sub Process">
<extensionElements>
<flowable:executionListener event="start" class="org.flowable.MyStartListener"/>
<flowable:executionListener event="end" class="org.flowable.MyEndListener"/>
</extensionElements>
<multiInstanceLoopCharacteristics isSequential="false">
<loopDataInputRef>assignees</loopDataInputRef>
<inputDataItem name="assignee"></inputDataItem>
</multiInstanceLoopCharacteristics>
<startEvent id="startevent2" name="Start"></startEvent>
<endEvent id="endevent2" name="End"></endEvent>
<sequenceFlow id="flow3" name="" sourceRef="startevent2" targetRef="endevent2"></sequenceFlow>
</subProcess>在这个例子中,假设assignees有三项。在运行时会发生如下事情:
-
多实例整体抛出一个启动事件。调用一次start执行监听器,loopCounter与assignee变量均未设置(即为null)。
-
每一个活动实例抛出一个启动事件。调用三次start执行监听器,loopCounter与assignee变量均已设置(也就是说不为null)。
-
因此启动执行监听器总共被调用四次。
请注意,即使multiInstanceLoopCharacteristics不是定义在子流程上,也是一样。例如,如果上面的例子中只是一个简单的用户任务,抛出事件的行为也是一样。
8.5.16. 补偿处理器
描述
如果要使用一个活动补偿另一个活动的影响,可以将其声明为补偿处理器(compensation handler)。补偿处理器不在正常流程中执行,而只在流程抛出补偿事件时才会执行。
补偿处理器不得有入口或出口顺序流。
补偿处理器必须通过单向的连接,关联一个补偿边界事件。
图示
如果一个活动是补偿处理器,则会在其下部中间显示补偿事件图标。下面摘录的流程图展示了一个带有补偿边界事件的服务任务,并关联至一个补偿处理器。请注意补偿处理器图标显示在"cancel hotel reservation(取消酒店预订)"服务任务的下部中间。
XML表示
要将一个活动声明为补偿处理器,需要将isForCompensation属性设置为true:
<serviceTask id="undoBookHotel" isForCompensation="true" flowable:class="...">
</serviceTask>8.6. 子流程与调用活动
8.6.1. 子流程
描述
子流程(sub-process)是包含其他的活动、网关、事件等的活动。其本身构成一个流程,并作为更大流程的一部分。子流程完全在父流程中定义(这就是为什么经常被称作嵌入式子流程)。
子流程有两个主要的使用场景:
-
子流程可以分层建模。很多建模工具都可以折叠子流程,隐藏子流程的所有细节,而只显示业务流程的高层端到端总览。
-
子流程会创建新的事件范围。在子流程执行中抛出的事件可以通过子流程边界上的边界事件捕获,为该事件创建了限制在子流程内的范围。
使用子流程也要注意以下几点:
-
子流程只能有一个空启动事件,而不允许有其他类型的启动事件。请注意BPMN 2.0规范允许省略子流程的启动与结束事件,但目前Flowable的实现尚不支持省略。
-
顺序流不能跨越子流程边界。
图示
子流程表示为标准活动(圆角矩形)。若折叠了子流程,则只显示其名字与一个加号,以展示流程的高层概览:
若展开了子流程,则在子流程内显示子流程的所有步骤:
使用子流程的一个主要原因是为事件定义范围。下面的流程模型展示了这种用法:investigate software(调查硬件)/investigate hardware(调查软件)两个任务需要并行执行,且需要在给定时限内,在Level 2 support(二级支持)响应前完成。在这里,定时器的范围(即需要按时完成的活动)通过子流程进行限制。
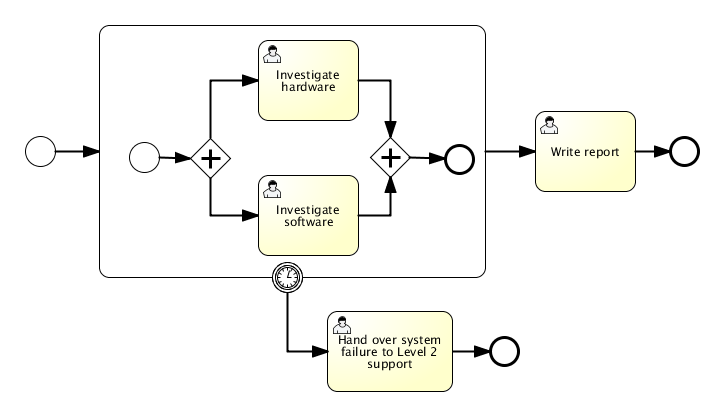
XML表示
子流程通过subprocess元素定义。子流程中的所有活动、网关、事件等,都需要定义在这个元素内。
<subProcess id="subProcess">
<startEvent id="subProcessStart" />
... 其他子流程元素 ...
<endEvent id="subProcessEnd" />
</subProcess>8.6.2. 事件子流程
描述
事件子流程(event sub-process)是BPMN 2.0新定义的。事件子流程是通过事件触发的子流程。可以在流程级别,或者任何子流程级别,添加事件子流程。用于触发事件子流程的事件,使用启动事件进行配置。因此可知,不能在事件子流程中使用空启动事件。事件子流程可以通过消息事件、错误事件、信号时间、定时器事件或补偿事件等触发。在事件子流程的宿主范围(流程实例或子流程)创建时,创建对启动事件的订阅。当该范围销毁时,删除订阅。
事件子流程可以是中断或不中断的。中断的子流程将取消当前范围内的任何执行。非中断的事件子流程将创建新的并行执行。宿主范围内的每个活动,只能触发一个中断事件子流程,而非中断事件子流程可以多次触发。子流程是否是中断的,通过触发事件子流程的启动事件配置。
事件子流程不能有任何入口或出口顺序流。事件子流程是由事件触发的,因此入口顺序流不合逻辑。当事件子流程结束时,要么同时结束当前范围(中断事件子流程的情况),要么是非中断子流程创建的并行执行结束。
目前的限制:
-
Flowable支持错误、定时器、信号与消息启动事件触发事件子流程。

XML表示
事件子流程的XML表示形式与嵌入式子流程相同。但需要将triggeredByEvent属性设置为true:
<subProcess id="eventSubProcess" triggeredByEvent="true">
...
</subProcess>示例
下面是使用错误启动事件触发事件子流程的例子。该事件子流程处于“流程级别”,即流程实例的范围:
事件子流程在XML中是这样的:
<subProcess id="eventSubProcess" triggeredByEvent="true">
<startEvent id="catchError">
<errorEventDefinition errorRef="error" />
</startEvent>
<sequenceFlow id="flow2" sourceRef="catchError" targetRef="taskAfterErrorCatch" />
<userTask id="taskAfterErrorCatch" name="Provide additional data" />
</subProcess>前面已经指出,事件子流程也可以添加到嵌入式子流程内。若添加到嵌入式子流程内,可以代替边界事件的功能。例如在下面两个流程图中,嵌入式子流程都抛出错误事件。错误事件都被捕获,并由用户任务处理。
对比:
两种情况下都执行相同的任务。然而,两种模型有如下不同:
-
嵌入式(事件)子流程使用其宿主范围的执行来执行。这意味着嵌入式(事件)子流程可以访问其范围的局部变量。当使用边界事件时,执行嵌入式子流程的执行,会被边界事件的出口顺序流删除。意味着嵌入式子流程创建的变量将不再可用。
-
使用事件子流程时,事件完全由其所在的子流程处理。当使用边界事件时,事件由其父流程处理。
这两点可以帮助你判断哪种方式更适合解决特定的流程建模或实现问题,以选择使用边界事件还是嵌入式(事件)子流程。
8.6.3. 事务子流程
描述
事务子流程(transaction sub-process)是一种嵌入式子流程,用于将多个活动组织在一个事务里。事务是工作的逻辑单元,可以组织一组独立活动,使得它们可以一起成功或失败。
事务的可能结果:事务有三种不同的结果:
-
若未被取消,或被意外终止,则事务成功(successful)。若事务子流程成功,将使用出口顺序流离开。若流程后面抛出了补偿事件,成功的事务可以被补偿。请注意:与“普通”嵌入式子流程一样,可以使用补偿抛出中间事件,在事务成功完成后补偿。
-
若执行到达取消结束事件时,事务被取消(canceled)。在这种情况下,所有执行都将被终止并移除。只会保留一个执行,设置为取消边界事件,并将触发补偿。在补偿完成后,事务子流程通过取消边界事件的出口顺序流离开。
-
若由于抛出了错误结束事件,且未被事务子流程所在的范围捕获,则事务会被意外(hazard)终止。错误被事件子流程的边界捕获也一样。在这种情况下,不会进行补偿。
下面的流程图展示这三种不同的结果:
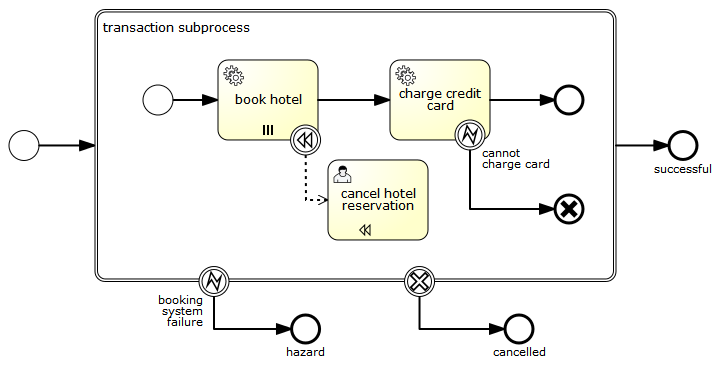
与ACID事务的关系:要注意不要将BPMN事务子流程与技术(ACID)事务混淆。BPMN事务子流程不是划分技术事务范围的方法。要理解Acitivit中的事务管理,请阅读并发与事务章节。BPMN事务与ACID事务有如下区别:
-
ACID事务生存期一般比较短,而BPMN事务可以持续几小时,几天甚至几个月才完成。考虑一个场景:事务包括的活动中有一个用户任务。通常人的响应时间要比程序长。或者,在另一个场景下,BPMN事务可能等待某些业务事件发生,像是特定订单的填写完成。这些操作通常要比更新数据库字段、使用事务队列存储消息等,花长得多的时间完成。
-
不可能将业务活动的持续时间限定为ACID事务的范围,因此一个BPMN事务通常会生成多个ACID事务。
-
一个BPMN事务可以生成多个ACID事务,也就不能使用ACID特性。例如,考虑上面的流程例子。假设"book hotel(预订酒店)"与"charge credit card(信用卡付款)"操作在分开的ACID事务中处理。再假设"book hotel(预订酒店)"活动已经成功。这时,因为已经进行了预订酒店操作,而还没有进行信用卡扣款,就处在中间不一致状态(intermediary inconsistent state)。在ACID事务中,会顺序进行不同的操作,因此也处在中间不一致状态。在这里不一样的是,不一致状态在事务范围外可见。例如,如果通过外部预订服务进行预定,则使用该预订服务的其他部分将能看到酒店已被预订。这意味着,当使用业务事务时,完全不会使用隔离参数(的确,当使用ACID事务时,我们通常也会降低隔离级别,以保证高并发级别。但ACID事务可以细粒度地进行控制,而中间不一致状态也只会存在于一小段时间内)。
-
BPMN业务事务不使用传统方式回滚。这是因为它生成多个ACID事务,在BPMN事务取消时,部分ACID事务可能已经提交。这样它们没法回滚。
因为BPMN事务天生需要长时间运行,因此就需要使用不同的方式缺乏隔离与回滚机制造成的问题。在实际使用中,通常只能通过领域特定(domain specific)的方式解决这些问题:
-
通过补偿实现回滚。如果在事务范围内抛出了取消事件,就补偿所有成功执行并带有补偿处理器的活动所造成的影响。
-
缺乏隔离通常使用特定领域的解决方案来处理。例如,在上面的例子里,在我们确定第一个客户可以付款前,一个酒店房间可能被第二个客户预定。这可能不满足业务预期,因此预订服务可能会选择允许一定量的超量预定。
-
另外,由于事务可以由于意外而终止,预订服务需要处理这种情况,比如酒店房间已经预定,但从未付款(因为事务可能已经终止)。在这种情况下,预定服务可能选择这种策略:一个酒店房间有最大预留时间,若到时还未付款,则取消预订。
总结一下:尽管ACID事务提供了对回滚、隔离级别,与启发式结果(heuristic outcomes)等问题的通用解决方案,但仍然需要在实现业务事务时,为这些问题寻找特定领域的解决方案。
目前的限制:
-
BPMN规范要求,流程引擎响应底层事务协议提交的事务。如果在底层协议中发生了取消事件,则取消事务。作为嵌入式的引擎,Flowable当前不支持这点。查看下面介绍一致性的段落,了解其后果。
基于ACID事务与乐观锁(optimistic concurrency)的一致性:BPMN事务在如下情况保证一致性:所有活动都成功完成;或若部分活动不能执行,则所有已完成活动都被补偿。两种方法都可以达到最终一致性状态。然而需要了解的是:Flowable中BPMN事务的一致性模型,以流程执行的一致性模型为基础。Flowable以事务的方式执行流程,并通过乐观锁标记处理并发。在Flowable中,BPMN的错误、取消与补偿事件,都建立在相同的ACID事务与乐观锁之上。例如,只有在实际到达时,取消结束事件才能触发补偿。如果服务任务抛出了非受检异常,导致并未实际到达取消结束事件;或者,由于底层ACID事务中的其他操作,将事务设置为rollback-only(回滚)状态,导致补偿处理器的操作不能提交;或者,当两个并行执行到达一个取消结束事件时,补偿会被两次触发,并由于乐观锁异常而失败。这些情况下都不能真正完成补偿。想说明的是,当在Flowable中实现BPMN事务时,与实施“普通”流程与子流程,需要遵守相同的规则。因此实现流程时需要有效地保证一致性,需要将乐观锁、事务执行模型纳入考虑范围。

XML表示
事务子流程在XML中通过transaction标签表示:
<transaction id="myTransaction" >
...
</transaction>示例
下面是一个事务子流程的例子:
8.6.4. 调用活动(子流程)
描述
尽管看起来很相像,但在BPMN 2.0中,调用活动(call activity)有别于一般的子流程——通常也称作嵌入式子流程。从概念上说,两者都在流程执行到达该活动时,调用一个子流程。
两者的区别为,调用活动引用一个流程定义外部的流程,而子流程嵌入在原有流程定义内。调用活动的主要使用场景是,在多个不同流程定义中调用一个可复用的流程定义。
当流程执行到达调用活动时,会创建一个新的执行,作为到达调用活动的执行的子执行。这个子执行用于执行子流程,也可用于创建并行子执行(与普通流程中行为类似)。父执行将等待子流程完成,之后沿原流程继续执行。

XML表示
调用活动是一个普通活动,在calledElement中通过key引用流程定义。在实际使用中,通常在calledElement中配置流程的ID。
<callActivity id="callCheckCreditProcess" name="Check credit" calledElement="checkCreditProcess" />请注意子流程的流程定义在运行时解析。这意味着如果需要的话,子流程可以与调用流程分别部署。
传递变量
可以向子流程传递与接收流程变量。数据将在子流程启动时复制到子流程,并在其结束时复制回主流程。
<callActivity id="callSubProcess" calledElement="checkCreditProcess">
<extensionElements>
<flowable:in source="someVariableInMainProcess"
target="nameOfVariableInSubProcess" />
<flowable:out source="someVariableInSubProcess"
target="nameOfVariableInMainProcess" />
</extensionElements>
</callActivity>可以将inheritVariables设置为true,将所有流程变量传递给子流程。
<callActivity id="callSubProcess" calledElement="checkCreditProcess" flowable:inheritVariables="true"/>除了需要按照BPMN 2.0标准的方式声明流程变量的BPMN标准元素dataInputAssociation与dataOutputAssociation之外, Flowable还提供了扩展作为快捷方式。
也可以在这里使用表达式:
<callActivity id="callSubProcess" calledElement="checkCreditProcess" >
<extensionElements>
<flowable:in sourceExpression="${x+5}" target="y" />
<flowable:out source="${y+5}" target="z" />
</extensionElements>
</callActivity>因此最终 z = y+5 = x+5+5 。
调用活动元素还提供了一个自定义Flowable属性扩展,businessKey,用于设置子流程实例的businessKey。
<callActivity id="callSubProcess" calledElement="checkCreditProcess" flowable:businessKey="${myVariable}">
...
</callActivity>
将inheritBusinessKey属性设置为true,会将子流程的businessKey值设置为调用流程的businessKey的值。
<callActivity id="callSubProcess" calledElement="checkCreditProcess" flowable:inheritBusinessKey="true"> ... </callActivity>
引用同一部署中的流程
默认会使用引用流程最后部署的流程定义版本。但有的时候也会想引用与主流程一起部署的引用流程定义。这需要将主流程与引用流程放在同一个部署单元中,以便引用相同的部署。
在callActivity元素中,将sameDeployment属性设置为true,即可引用相同部署的流程。
如下例所示:
<callActivity id="callSubProcess" calledElement="checkCreditProcess" flowable:sameDeployment="true"> ... </callActivity>
sameDeployment默认值为false。
示例
下面的流程图展示了简单的订单处理流程。因为检查客户的信用额度的操作在许多其他流程中都通用,因此将check credit step(检查信用额度步骤)建模为调用活动。
流程像是下面这样:
<startEvent id="theStart" />
<sequenceFlow id="flow1" sourceRef="theStart" targetRef="receiveOrder" />
<manualTask id="receiveOrder" name="Receive Order" />
<sequenceFlow id="flow2" sourceRef="receiveOrder" targetRef="callCheckCreditProcess" />
<callActivity id="callCheckCreditProcess" name="Check credit" calledElement="checkCreditProcess" />
<sequenceFlow id="flow3" sourceRef="callCheckCreditProcess" targetRef="prepareAndShipTask" />
<userTask id="prepareAndShipTask" name="Prepare and Ship" />
<sequenceFlow id="flow4" sourceRef="prepareAndShipTask" targetRef="end" />
<endEvent id="end" />子流程像是下面这样:
与子流程的流程定义相比没什么特别。但调用活动的流程也可以不通过其他流程调用而直接使用。
8.7. 事务与并发
8.7.1. 异步延续
(Asynchronous Continuations)
Flowable以事务方式执行流程,并可按照你的需求配置。让我们从Flowable一般如何为事务划分范围开始介绍。如果Flowable被触发(启动流程,完成任务,为执行发送信号),Flowable将沿流程执行,直到到达每个执行路径的等待状态。更具体地说,它以深度优先方式搜索流程图,并在每个执行分支都到达等待状态时返回。等待状态是“之后”再执行的任务,也就是说着Flowable将当前执行持久化,并等待再次触发。触发可以来自外部来源如用户任务或消息接受任务,也可以来自Flowable自身如定时器事件。以下面的图片说明:

这是一个BPMN流程的片段,有一个用户任务、一个服务任务,与一个定时器事件。用户任务的完成操作与验证地址(validate address)在同一个工作单元内,因此需要原子性地(atomically)成功或失败。这意味着如果服务任务抛出了异常,我们会想要回滚当前事务,以便执行返回到用户任务,并希望用户任务仍然保存在数据库中。这也是Flowable的默认行为。在(1)中,应用或客户端线程完成任务。在相同的线程中,Flowable执行服务并继续,直到到达等待状态,在这个例子中,是定时器事件(2)。然后将控制权返回至调用者(3),同时提交事务(如果事务由Flowable开启)。
在有的情况下,我们不想要这样。有时我们需要在流程中自定义地控制事务边界,以便为工作的逻辑单元划分范围。这就需要使用异步延续。考虑下面的流程(片段):

完成用户任务,生成发票,并将发票发送给客户。这次发票的生成不再是同一个工作单元的一部分,因此我们不希望当发票生成失败时,回滚用户任务。所以我们希望Flowable做的,是完成用户任务(1),提交事务,并将控制权返回给调用程序。然后我们希望在后台线程中,异步地生成发票。这个后台线程就是Flowable作业执行器(事实上是一个线程池),它周期性地将作业保存至数据库。因此在幕后,当到达"generate invoice(生成发票)"任务时,Flowable会创建“消息”作业并将其持久化到数据库中,用于继续执行流程。这个作业之后会被作业执行器选中并执行。Flowable也会向本地的作业执行器进行提示,告知其有新作业到来,以提升性能。
要使用这个特性,可以使用flowable:async="true"扩展。因此,一个示例的服务任务会像是这样:
<serviceTask id="service1" name="Generate Invoice"
flowable:class="my.custom.Delegate"
flowable:async="true" />可以为下列BPMN任务类型指定flowable:async:任务,服务任务,脚本任务,业务规则任务,发送任务,接收任务,用户任务,子流程,调用活动。
对于用户任务、接收任务与其他等待状态来说,异步操作允许我们在一个独立的线程/事务中启动执行监听器。
8.7.2. 失败重试
默认配置下,如果作业执行中有任何异常,Flowable将三次重试执行作业。对异步作业也是这样。需要更灵活的配置时可以使用这两个参数:
-
重试的次数
-
重试的间隔
这两个参数可以通过flowable:failedJobRetryTimeCycle元素配置。这有一个简单的例子:
<serviceTask id="failingServiceTask" flowable:async="true"
flowable:class="org.flowable.engine.test.jobexecutor.RetryFailingDelegate">
<extensionElements>
<flowable:failedJobRetryTimeCycle>R5/PT7M</flowable:failedJobRetryTimeCycle>
</extensionElements>
</serviceTask>时间周期表达式与定时器事件表达式一样遵循ISO 8601标准。上面的例子会让作业执行器重试5次,并在每次重试前等待7分钟。
8.7.3. 排他作业
从近期版本开始,JobExecutor确保同一个流程实例的作业永远不会并发执行。为什么这样?
为什么使用排他作业?
考虑下面的流程定义:
一个并行网关,之后是三个服务任务,都使用异步操作执行。其结果是在数据库中添加了三个作业。当作业储存在数据库后,就由JobExecutor处理。JobExecutor获取作业,并将其委托至工作线程的线程池,由它们实际执行作业。这意味着通过使用异步操作,可以将工作分发至线程池(在集群场景下,甚至会在集群中跨越多个线程池)。通常这都是好事。但也有其固有问题:一致性。考虑服务任务后的并行合并:当服务任务的执行完成时到达并行合并,并需要决定等待其他执行,还是需要继续向前。这意味着,对于每一个到达并行合并的分支,都需要选择继续执行,还是需要等待其他分支上的一个或多个其他执行。
为什么这是问题呢?这是因为服务任务配置为使用异步延续,有可能所有相应的作业都同时被作业执行器处理,并委托至不同的工作线程。结果是服务执行的事务,与到达并行合并的3个独立执行所在的事务会发生重叠。如果这样,每一个独立事务都“看不到”其他事物已经并发地到达了同样的并行合并,并因此判断自己需要等待其他事务。然而,如果每个事务都判断需要等待其他事务,在并行合并后不会有继续流程的事务,而流程实例也就会永远保持这个状态。
Flowable如何解决这个问题呢?Flowable使用乐观锁。每当需要基于数据进行判断,而数据可能不是最新值(因为其他事务可能在我们提交前修改了这个数据)时,我们确保会在每个事务中都增加同一个数据库记录行的版本号。这样,无论哪个事务第一个提交,都将成功,而其他的会抛出乐观锁异常并失败。这样就解决了上面流程中讨论的问题:如果多个执行并发到达并行合并,它们都判断需要等待,增加其父执行(流程实例)的版本号并尝试提交。无论哪个执行第一个提交,都可以成功提交,而其他的将会抛出乐观锁异常并失败。因为这些执行由作业触发,Flowable会在等待给定时间后,重试执行相同的作业,期望这一次通过这个同步的网关。
这是好的解决方案么?我们可以看到乐观锁使Flowable避免不一致状态。它确保了我们不会“在合并网关卡住”,也就是说:要么所有的执行都通过网关,要么数据库中的作业能确保可以重试通过它。然而,尽管这是一个持久化与一致性角度的完美解决方案,但从更高层次看,仍然不一定总是理想行为:
-
Flowable只会为同一个作业重试一个固定的最大次数(默认配置为3次)。在这之后,作业仍然保存在数据库中,但不会再重试。这就需要手动操作来触发作业。
-
如果一个作业有非事务性的副作用,则副作用将不会由于事务失败而回滚。例如,如果"book concert tickets(预定音乐会门票)"服务与Flowable不在同一个事务中,则重试执行作业将预定多张票。
什么是排他作业?
排他作业不能与同一个流程实例中的其他排他作业同时执行。考虑上面展示的流程:如果我们将服务任务都声明为排他的,则JobExecutor将确保相关的作业都不会并发执行。相反,它将确保不论何时从特定流程实例中获取了排他作业,都会从同一个流程实例中获取所有其他的排他作业,并将它们委托至同一个工作线程。这保证了作业的顺序执行。
如何启用这个特性?从近期版本开始,排他作业成为默认配置。所有异步操作与定时器事件都默认为排他的。另外,如果希望作业成为非排他的,可以使用flowable:exclusive="false"配置。例如,下面的服务任务是异步,但非排他的。
<serviceTask id="service" flowable:expression="${myService.performBooking(hotel, dates)}"
flowable:async="true" flowable:exclusive="false" />这是好的解决方案么?有很多人都在问这个问题。他们的顾虑是,这将阻止并行操作,因此会有性能问题。但也需要考虑以下两点:
-
如果你是专家,并且知道你在做什么(并理解“为什么排他作业?”章节的内容),可以关掉排他。否则,对大多数用户来说,异步操作与定时器能够正常工作才更重要。
-
事实上不会有性能问题。只有在重负载下才会有性能问题。重负载意味着作业执行器的所有的工作线程都一直忙碌。对于排他作业,Flowable会简单的根据负载不同进行分配。排他作业意味着同一个流程实例的作业都将在同一个线程中顺序执行。但是请想一下:我们有不止一个流程实例。其他流程实例的作业将被委托至其他线程,并与本实例的作业并发执行。也就是说Flowable不会并发执行同一个流程实例的排他作业,但会并发执行多个实例。从总吞吐量角度来看,可以期望大多数场景下都可以保证实例很快地完成。此外,执行同一个流程实例中下一个作业所需的数据,已经缓存在同一个执行集群节点中。如果作业与节点没有关联关系,则可能需要重新从数据库中获取数据。
8.8. 流程启动认证
默认情况下,任何人都可以启动已部署流程定义的新流程实例。可以使用流程启动认证功能定义用户与组,让Web客户端可以选择性的限制能够启动新流程实例的用户。请注意Flowable引擎不会用任何方式验证认证定义。这个功能只是为了开发人员可以简化Web客户端认证规则的实现。语法与为用户任务指派用户的语法类似:可以使用<flowable:potentialStarter>标签,将用户或组指派为流程的潜在启动者。这里有一个例子:
<process id="potentialStarter">
<extensionElements>
<flowable:potentialStarter>
<resourceAssignmentExpression>
<formalExpression>group2, group(group3), user(user3)</formalExpression>
</resourceAssignmentExpression>
</flowable:potentialStarter>
</extensionElements>
<startEvent id="theStart"/>
...在上面的XML中,user(user3)直接引用用户user3,而group(group3)引用组group3。不显式标明的话,默认为组。也可以使用<process>标签提供的<flowable:candidateStarterUsers>与<flowable:candidateStarterGroups>的属性。这里有一个例子:
<process id="potentialStarter" flowable:candidateStarterUsers="user1, user2"
flowable:candidateStarterGroups="group1">
...这些属性可以同时使用。
在流程启动认证定义后,开发者可以使用下列方法获取该认证定义。 这段代码获取可以由给定用户启动的流程定义列表:
processDefinitions = repositoryService.createProcessDefinitionQuery().startableByUser("userxxx").list();也可以获取给定流程定义中,所有定义为潜在启动者的身份关联
identityLinks = repositoryService.getIdentityLinksForProcessDefinition("processDefinitionId");下面的例子展示了如何获取能够启动给定流程的用户列表:
List<User> authorizedUsers = identityService().createUserQuery()
.potentialStarter("processDefinitionId")
.list();用完全相同的方法,可以获取配置为给定流程定义的潜在启动者的组列表:
List<Group> authorizedGroups = identityService().createGroupQuery()
.potentialStarter("processDefinitionId")
.list();8.9. 数据对象
BPMN提供了将数据对象定义为流程或子流程元素的一部分的可能性。根据BPMN规范,数据对象可以包含复杂的XML结构,并可以从XSD定义中引入。下列XSD类型为Flowable支持的第一批数据对象:
<dataObject id="dObj1" name="StringTest" itemSubjectRef="xsd:string"/>
<dataObject id="dObj2" name="BooleanTest" itemSubjectRef="xsd:boolean"/>
<dataObject id="dObj3" name="DateTest" itemSubjectRef="xsd:datetime"/>
<dataObject id="dObj4" name="DoubleTest" itemSubjectRef="xsd:double"/>
<dataObject id="dObj5" name="IntegerTest" itemSubjectRef="xsd:int"/>
<dataObject id="dObj6" name="LongTest" itemSubjectRef="xsd:long"/>数据对象定义使用name属性值作为新变量的名字,将其自动转换为流程变量。另外,Flowable也提供了为变量设置默认值的扩展元素。下面的BPMN代码片段示例:
<process id="dataObjectScope" name="Data Object Scope" isExecutable="true">
<dataObject id="dObj123" name="StringTest123" itemSubjectRef="xsd:string">
<extensionElements>
<flowable:value>Testing123</flowable:value>
</extensionElements>
</dataObject>
...9. 表单
Flowable提供了一种简便灵活的方式,用来为业务流程中的人工步骤添加表单。 有两种使用表单的方法:使用(由表单设计器创建的)表单定义的内置表单渲染,以及外部表单渲染。 使用外部表单渲染时,可以使用(自Explorer web应用V5版本支持的)表单参数;也可以使用表单key定义,引用外部的、使用自定义代码解析的表单。
9.1. 表单定义
表单引擎用户手册中提供了关于表单定义与Flowable表单引擎的完整信息。 可以使用Flowable表单设计器创建表单定义。表单设计器是Flowable Modeler web应用的一部分。也可以直接使用JSON编辑器创建表单定义。 表单引擎用户手册中介绍了表单定义JSON的完整结构。表单支持下列表单字段类型:
-
Text: 渲染为文本框
-
Multiline text: 渲染为多行文本框
-
Number: 渲染为只允许数字值的文本框
-
CheckBox: 渲染为复选框
-
Date: 渲染为日期框
-
Dropdown: 渲染为下拉选择框,候选值由字段定义配置
-
Radio buttons: 渲染为单选按钮,候选值由字段定义配置
-
People: 渲染为选人框,可以选择用户身份表中的用户
-
Group of people: 渲染为选组框,可以选择组身份表中的组
-
Upload: 渲染为上传框
-
Expression: 渲染为一个标签,可以在标签文字中使用JUEL表达式,以使用变量及/或其他动态值
Flowable Task应用可以用表单定义JSON渲染出html表单。 也可以使用Flowable API,自行获取表单定义JSON。
FormModel RuntimeService.getStartFormModel(String processDefinitionId, String processInstanceId)或
FormModel TaskService.getTaskFormModel(String taskId)FormModel对象是一个代表了表单定义JSON的Java对象。
可以调用下列API,使用启动表单定义以启动流程实例:
ProcessInstance RuntimeService.startProcessInstanceWithForm(String processDefinitionId, String outcome,
Map<String, Object> variables, String processInstanceName)如果在流程定义的(某一个或多个)启动事件上定义了表单定义,则可以使用这个方法,使用启动表单中填写的值启动流程实例。 Flowable Task应用使用同样的方法,用表单启动流程实例。 通过变量map传入所有需要的表单值,也可以指定表单输出字符串及流程实例名。
类似的,可以调用下列API,使用表单完成用户任务:
void TaskService.completeTaskWithForm(String taskId, String formDefinitionId,
String outcome, Map<String, Object> variables)再次强调,要获取关于表单定义的更多信息,请查看表单引擎用户手册。
9.2. 表单参数
所有与业务流程相关的信息,要么包含在流程变量里,要么可以通过流程变量引用。Flowable也支持将复杂的Java对象,以Serializable对象、JPA实体,或整个XML文档存储为String等方式,存储为流程变量。
启动流程与完成用户任务是用户参与流程的地方,所以需要使用UI界面渲染表单。为了简化UI设计,可以在流程定义中,将流程变量中的复杂的Java对象转换为Map<String,String>格式的参数。
这样UI就可以使用Flowable API方法,在这些参数的基础上构建表单。这些参数可看做是专用(也更受限)的流程变量视图。可以使用FormData返回值,获取用于显示表单的参数。如
StartFormData FormService.getStartFormData(String processDefinitionId)或
TaskFormData FormService.getTaskFormData(String taskId)默认情况下,内建表单引擎能够“看到”参数与流程变量。因此如果任务表单参数一对一对应流程变量,则不需要专门进行声明。例如,对于如下声明:
<startEvent id="start" />当执行到达startEvent时,所有流程变量都可用。但
formService.getStartFormData(String processDefinitionId).getFormProperties()将为空,因为并未指定映射。
在上面的例子中,所有提交的参数都存储为流程变量。也就是说,只要简单地在表单中添加输入框,就可以存储新变量。
参数从流程变量衍生而来,但并不是必须存储为流程变量。例如,流程变量可以是Address类的JPA实体。而UI使用的StreetName表单参数,则通过#{address.street}表达式获取。
类似的,表单中用户需要提交的参数,可以存储为流程变量,也可以使用UEL值表达式,保存至某个流程变量的参数。如#{address.street}。
除非使用formProperty声明,否则提交参数时,默认将其存储为流程变量。
在表单参数与流程变量的处理过程中,也可以进行类型转换。
例如:
<userTask id="task">
<extensionElements>
<flowable:formProperty id="room" />
<flowable:formProperty id="duration" type="long"/>
<flowable:formProperty id="speaker" variable="SpeakerName" writable="false" />
<flowable:formProperty id="street" expression="#{address.street}" required="true" />
</extensionElements>
</userTask>-
room表单参数将作为String,映射为room流程变量 -
duration表单参数将作为java.lang.Long,映射为duration流程变量 -
speaker表单参数将被映射为SpeakerName流程变量。将只在TaskFormData对象中可用。若提交了speaker参数,将抛出FlowableException。对应地,使用readable="false"属性,参数可以提交,但不会在FormData中提供。 -
street表单参数将作为String,映射为address流程变量的Java bean参数street。如果在提交时没有提供这个字段,required="true"将抛出异常。
StartFormData FormService.getStartFormData(String processDefinitionId)与TaskFormdata FormService.getTaskFormData(String taskId)方法返回的FormData同样提供类型元数据。
支持下列表单参数类型:
-
string(org.flowable.engine.impl.form.StringFormType -
long(org.flowable.engine.impl.form.LongFormType) -
double(org.flowable.engine.impl.form.DoubleFormType) -
enum(org.flowable.engine.impl.form.EnumFormType) -
date(org.flowable.engine.impl.form.DateFormType) -
boolean(org.flowable.engine.impl.form.BooleanFormType)
可以通过List<FormProperty> formService.getStartFormData(String processDefinitionId).getFormProperties()与List<FormProperty> formService.getTaskFormData(String taskId).getFormProperties()方法,获取每个表单参数的下列FormProperty信息:
public interface FormProperty {
/**
* 在{@link FormService#submitStartFormData(String, java.util.Map)}
* 或{@link FormService#submitTaskFormData(String, java.util.Map)}
* 中提交参数时使用的key
*/
String getId();
/** 显示标签 */
String getName();
/** 在本接口中定义的类型,例如{@link #TYPE_STRING} */
FormType getType();
/** 可选。这个参数需要显示的值 */
String getValue();
/** 这个参数是否可以读取:在表单中显示,并可通过
* {@link FormService#getStartFormData(String)}
* 与{@link FormService#getTaskFormData(String)}
* 方法访问。
*/
boolean isReadable();
/** 用户提交表单时是否可以包含这个参数? */
boolean isWritable();
/** 输入框中是否必填这个参数 */
boolean isRequired();
}例如:
<startEvent id="start">
<extensionElements>
<flowable:formProperty id="speaker"
name="Speaker"
variable="SpeakerName"
type="string" />
<flowable:formProperty id="start"
type="date"
datePattern="dd-MMM-yyyy" />
<flowable:formProperty id="direction" type="enum">
<flowable:value id="left" name="Go Left" />
<flowable:value id="right" name="Go Right" />
<flowable:value id="up" name="Go Up" />
<flowable:value id="down" name="Go Down" />
</flowable:formProperty>
</extensionElements>
</startEvent>所有这些信息都可以通过API获取:用formProperty.getType().getName()获取类型名、formProperty.getType().getInformation("datePattern")获取日期格式、formProperty.getType().getInformation("values")获取枚举值。
下面的XML代码片段
<startEvent>
<extensionElements>
<flowable:formProperty id="numberOfDays" name="Number of days" value="${numberOfDays}" type="long" required="true"/>
<flowable:formProperty id="startDate" name="First day of holiday (dd-MM-yyy)" value="${startDate}" datePattern="dd-MM-yyyy hh:mm" type="date" required="true" />
<flowable:formProperty id="vacationMotivation" name="Motivation" value="${vacationMotivation}" type="string" />
</extensionElements>
</userTask>可以在自定义应用中用于渲染流程启动表单。
9.3. 外部表单渲染
也可以使用API,在Flowable引擎之外,自行渲染任务表单。下面的步骤介绍在自行渲染任务表单时,可以使用的钩子。
实际上,渲染表单所需的所有数据都组装在:StartFormData FormService.getStartFormData(String processDefinitionId)与TaskFormdata FormService.getTaskFormData(String taskId)这两个方法中。
可以通过ProcessInstance FormService.submitStartFormData(String processDefinitionId, Map<String,String> properties)与void FormService.submitTaskFormData(String taskId, Map<String,String> properties)提交表单参数。
查看表单参数了解如何将表单参数映射至流程变量。
如果希望按版本将表单与流程存储在一起,可以将表单模板资源放在部署的业务存档中,并可以使用String ProcessDefinition.getDeploymentId()与InputStream RepositoryService.getResourceAsStream(String deploymentId, String resourceName);,作为部署中的资源获取,在你的应用中渲染/显示表单。
除了任务表单之外,也可以获取其他部署资源。
String FormService.getStartFormData(String processDefinitionId).getFormKey()与String FormService.getTaskFormData(String taskId).getFormKey()API提供<userTask flowable:formKey="…"属性。可以用它保存部署中模板的全名(如org/flowable/example/form/my-custom-form.xml),但这并非唯一选择。例如,也可以在formKey中保存通用的key,通过算法或转换得到实际需要使用的模板。在你需要在不同的UI界面渲染不同的表单时很方便。例如,在普通屏幕尺寸的Web应用中显示一个表单,在手机等小屏幕中显示另一个表单。甚至可以为IM表单或邮件表单提供专门的模板。
10. JPA
(Java Persistence API Java持久化API)
可以使用JPA实体作为流程变量,这样可以:
-
使用流程变量更新已有的JPA实体。流程变量可以在用户任务的表单中填写,或者通过服务任务生成。
-
重用已有的领域模型,而不需要写专门的服务用于读取与更新实体。
-
基于已有实体做决策(网关)。
-
…
10.1. 需求
只支持完全满足下列条件的实体:
-
实体需要使用JPA注解配置,字段与参数访问器都可以。也可以使用映射的父类。
-
实体需要有使用
@Id注解的主键,不支持复合主键(@EmbeddedId与@IdClass)。Id字段/参数可以是任何JPA规范支持的类型:原生类型与其包装器(除了boolean)、String、BigInteger、BigDecimal、java.util.Date与java.sql.Date。
10.2. 配置
引擎必须引用EntityManagerFactory才能使用JPA实体,可以配置引用,或者配置持久化单元名(Persistence Unit Name)。引擎会自动检测用作变量的JPA实体,并按需处理。
下面的示例配置使用jpaPersistenceUnitName:
<bean id="processEngineConfiguration"
class="org.flowable.engine.impl.cfg.StandaloneInMemProcessEngineConfiguration">
<!-- 数据库配置 -->
<property name="databaseSchemaUpdate" value="true" />
<property name="jdbcUrl" value="jdbc:h2:mem:JpaVariableTest;DB_CLOSE_DELAY=1000" />
<property name="jpaPersistenceUnitName" value="flowable-jpa-pu" />
<property name="jpaHandleTransaction" value="true" />
<property name="jpaCloseEntityManager" value="true" />
<!-- 作业执行器配置 -->
<property name="asyncExecutorActivate" value="false" />
<!-- 邮件服务器配置 -->
<property name="mailServerPort" value="5025" />
</bean>下面的示例配置使用自定义的EntityManagerFactory(open-jpa实体管理器)。请注意这段代码只包含了与本例相关的bean,而省略了其他的bean。使用open-jpa实体管理器的完整可用示例,可以在flowable-spring-examples (/flowable-spring/src/test/java/org/flowable/spring/test/jpa/JPASpringTest.java)中找到。
<bean id="entityManagerFactory" class="org.springframework.orm.jpa.LocalContainerEntityManagerFactoryBean">
<property name="persistenceUnitManager" ref="pum"/>
<property name="jpaVendorAdapter">
<bean class="org.springframework.orm.jpa.vendor.OpenJpaVendorAdapter">
<property name="databasePlatform" value="org.apache.openjpa.jdbc.sql.H2Dictionary" />
</bean>
</property>
</bean>
<bean id="processEngineConfiguration" class="org.flowable.spring.SpringProcessEngineConfiguration">
<property name="dataSource" ref="dataSource" />
<property name="transactionManager" ref="transactionManager" />
<property name="databaseSchemaUpdate" value="true" />
<property name="jpaEntityManagerFactory" ref="entityManagerFactory" />
<property name="jpaHandleTransaction" value="true" />
<property name="jpaCloseEntityManager" value="true" />
<property name="asyncExecutorActivate" value="false" />
</bean>也可以使用相同的配置,以编程方式构建引擎。例如:
ProcessEngine processEngine = ProcessEngineConfiguration
.createProcessEngineConfigurationFromResourceDefault()
.setJpaPersistenceUnitName("flowable-pu")
.buildProcessEngine();配置参数:
-
jpaPersistenceUnitName:要使用的持久化单元的名字。(需要确保该持久化单元在classpath中可用。根据规范,默认位置为/META-INF/persistence.xml)。jpaEntityManagerFactory与jpaPersistenceUnitName二选一。 -
jpaEntityManagerFactory:用于载入实体及刷入更新的,实现javax.persistence.EntityManagerFactory的bean。jpaEntityManagerFactory与jpaPersistenceUnitName二选一。 -
jpaHandleTransaction:标示是否需要由引擎负责开启及提交/回滚EntityManager上的事务。当使用Java Transaction API (JTA)时,需设置为false。 -
jpaCloseEntityManager:标示是否需要由引擎负责关闭从EntityManagerFactory获取的EntityManager实例。当EntityManager由容器管理时(例如,使用扩展持久化上下文 Extended Persistence Context,而不将实体范围限制为单一事务时)需设置为false。
10.3. 使用
10.3.1. 简单示例
可以在Flowable源代码的JPAVariableTest中找到使用JPA变量的例子。下面逐步解释JPAVariableTest.testUpdateJPAEntityValues。
首先,基于META-INF/persistence.xml为持久化单元创建EntityManagerFactory。包括需要包含在持久化单元内的类及一些(数据库)厂商特定配置。
在这个测试里使用的是简单实体,包括id以及一个String值参数。在运行测试前,先创建一个实体并保存。
@Entity(name = "JPA_ENTITY_FIELD")
public class FieldAccessJPAEntity {
@Id
@Column(name = "ID_")
private Long id;
private String value;
public FieldAccessJPAEntity() {
// JPA需要的空构造方法
}
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
public String getValue() {
return value;
}
public void setValue(String value) {
this.value = value;
}
}启动一个新的流程实例,将这个实体加入变量。与其他变量一样,它们都会在引擎中持久化存储。当下一次请求这个变量时,将会根据类及Id,从EntityManager载入。
Map<String, Object> variables = new HashMap<String, Object>();
variables.put("entityToUpdate", entityToUpdate);
ProcessInstance processInstance = runtimeService.startProcessInstanceByKey(
"UpdateJPAValuesProcess", variables);流程定义的第一个节点是服务任务,将调用entityToUpdate上的setValue方法。entityToUpdate将解析为之前启动流程实例时设置的JPA变量,并使用当前引擎的上下文中关联的EntityManager载入。
<serviceTask id='theTask' name='updateJPAEntityTask'
flowable:expression="${entityToUpdate.setValue('updatedValue')}" />当服务任务完成时,流程实例在流程定义中的用户任务处等待,以便我们可以查看流程实例。在这时,EntityManager已经刷入,对实体的修改也已经存入数据库。当获取entityToUpdate变量的值时,将重新载入实体。所以可以得到value参数设置为updatedValue的实体。
// 流程'UpdateJPAValuesProcess'中的服务任务已经设置了entityToUpdate的值。
Object updatedEntity = runtimeService.getVariable(processInstance.getId(), "entityToUpdate");
assertTrue(updatedEntity instanceof FieldAccessJPAEntity);
assertEquals("updatedValue", ((FieldAccessJPAEntity)updatedEntity).getValue());10.3.2. 查询JPA流程变量
可以查询以特定JPA实体作为变量值的流程实例与执行。请注意ProcessInstanceQuery与ExecutionQuery中,只有variableValueEquals(name, entity)方法支持JPA实体查询。而variableValueNotEquals、variableValueGreaterThan、variableValueGreaterThanOrEqual、variableValueLessThan与variableValueLessThanOrEqual等方法都不支持JPA,并会在值传递为JPA实体时,抛出FlowableException。
ProcessInstance result = runtimeService.createProcessInstanceQuery()
.variableValueEquals("entityToQuery", entityToQuery).singleResult();10.3.3. 使用Spring bean与JPA的高级示例
可以在flowable-spring-examples中找到高级用法的示例——JPASpringTest。它描述了一个简单的用例:
-
使用一个已有的Spring bean及已定义的JPA实体,用于存储贷款申请。
-
Flowable通过该bean获取该实体,并将其用作流程中的变量。流程定义如下步骤:
-
使用
LoanRequestBean,并使用启动流程时(从启动表单)接收的变量创建LoanRequest(贷款申请)实体的服务任务。使用flowable:resultVariable将表达式结果,即所创建的实体存储为流程变量。 -
经理用于审核并批准/驳回申请的用户任务,并将审核结论存储为boolean变量
approvedByManager。 -
更新贷款申请实体的服务任务,使实体与流程同步。
-
使用一个排他网关,依据
approved实体参数的值选择下一步采用哪条路径:若申请被批准,结束流程;否则,生成一个额外任务(Send rejection letter 发送拒信),以便客户可以收到拒信得到通知。
-
请注意这个流程只用于单元测试,而不包含任何表单。
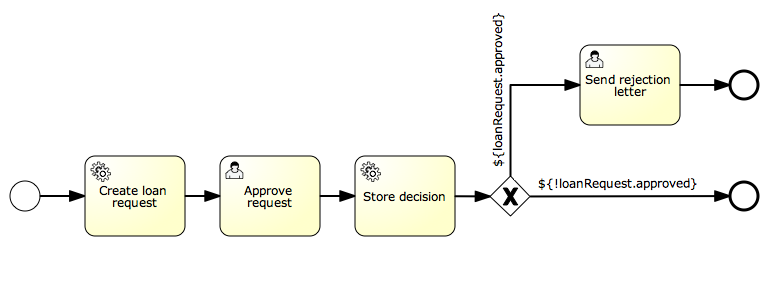
<?xml version="1.0" encoding="UTF-8"?>
<definitions id="taskAssigneeExample"
xmlns="http://www.omg.org/spec/BPMN/20100524/MODEL"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:flowable="http://flowable.org/bpmn"
targetNamespace="org.flowable.examples">
<process id="LoanRequestProcess" name="Process creating and handling loan request">
<startEvent id='theStart' />
<sequenceFlow id='flow1' sourceRef='theStart' targetRef='createLoanRequest' />
<serviceTask id='createLoanRequest' name='Create loan request'
flowable:expression="${loanRequestBean.newLoanRequest(customerName, amount)}"
flowable:resultVariable="loanRequest"/>
<sequenceFlow id='flow2' sourceRef='createLoanRequest' targetRef='approveTask' />
<userTask id="approveTask" name="Approve request" />
<sequenceFlow id='flow3' sourceRef='approveTask' targetRef='approveOrDissaprove' />
<serviceTask id='approveOrDissaprove' name='Store decision'
flowable:expression="${loanRequest.setApproved(approvedByManager)}" />
<sequenceFlow id='flow4' sourceRef='approveOrDissaprove' targetRef='exclusiveGw' />
<exclusiveGateway id="exclusiveGw" name="Exclusive Gateway approval" />
<sequenceFlow id="endFlow1" sourceRef="exclusiveGw" targetRef="theEnd">
<conditionExpression xsi:type="tFormalExpression">${loanRequest.approved}</conditionExpression>
</sequenceFlow>
<sequenceFlow id="endFlow2" sourceRef="exclusiveGw" targetRef="sendRejectionLetter">
<conditionExpression xsi:type="tFormalExpression">${!loanRequest.approved}</conditionExpression>
</sequenceFlow>
<userTask id="sendRejectionLetter" name="Send rejection letter" />
<sequenceFlow id='flow5' sourceRef='sendRejectionLetter' targetRef='theOtherEnd' />
<endEvent id='theEnd' />
<endEvent id='theOtherEnd' />
</process>
</definitions>尽管上面的例子很简单,但也展示了JPA与Spring结合,以及带参数方法表达式的威力。这个流程本身完全不需要写Java代码(当然还是需要写Spring bean),大幅加速了开发。
11. 历史
历史是记录流程执行过程中发生的事情,并将其永久存储的组件。与运行时数据不同,历史数据在流程实例完成以后仍保存在数据库中。
有6个历史实体:
-
HistoricProcessInstance保存当前及已结束流程实例的信息。 -
HistoricVariableInstance保存流程变量或任务变量的最新值。 -
HistoricActivityInstance保存活动(流程中的节点)的一次执行的信息。 -
HistoricTaskInstance保存当前与历史(完成及删除的)任务实例的信息。 -
HistoricIdentityLink保存任务及流程实例、当前及历史的身份关联的信息。 -
HistoricDetail保存与历史流程实例、活动实例或任务实例等有关的多种信息。
历史与当前进行中的流程实例都在数据库中保存历史实体,因此可以选择直接查询历史表,以减少对运行时流程实例数据的访问,并提高运行时执行的性能。
11.1. 查询历史
可以使用HistoryServiceAPI提供的createHistoricProcessInstanceQuery()、createHistoricVariableInstanceQuery()、createHistoricActivityInstanceQuery()、 getHistoricIdentityLinksForTask()、getHistoricIdentityLinksForProcessInstance()、createHistoricDetailQuery()与createHistoricTaskInstanceQuery()方法,查询全部6种历史实体。
下面用一些例子展示历史查询API的部分用法。可以在javadoc的org.flowable.engine.history包中找到全部用法。
11.1.1. 历史流程实例查询
获取所有流程中,完成所花费时间(持续时间)排名前10的、流程定义为XXX的、已完成的HistoricProcessInstances(历史流程实例)。
historyService.createHistoricProcessInstanceQuery()
.finished()
.processDefinitionId("XXX")
.orderByProcessInstanceDuration().desc()
.listPage(0, 10);11.1.2. 历史变量实例查询
获取已完成的、id为’XXX’的流程实例中,所有的HistoricVariableInstances(历史变量实例),并以变量名排序。
historyService.createHistoricVariableInstanceQuery()
.processInstanceId("XXX")
.orderByVariableName.desc()
.list();11.1.3. 历史活动实例查询
获取最新的、已完成的、流程定义的id为XXX的、服务任务类型的HistoricActivityInstance(历史活动实例)。
historyService.createHistoricActivityInstanceQuery()
.activityType("serviceTask")
.processDefinitionId("XXX")
.finished()
.orderByHistoricActivityInstanceEndTime().desc()
.listPage(0, 1);11.1.4. 历史详情查询
下面的的例子获取id为123的流程中所有的变量更新记录。这个查询只会返回HistoricVariableUpdate(历史变量更新)。请注意一个变量名可能会有多个HistoricVariableUpdate实体,这代表了流程中的每一次变量更新。可以使用orderByTime(按变量更新的时间)或orderByVariableRevision(按变量更新的版本号)对这些更新记录进行排序。
historyService.createHistoricDetailQuery()
.variableUpdates()
.processInstanceId("123")
.orderByVariableName().asc()
.list()下面的例子获取流程id为"123"的、启动时提交或任何任务中提交的所有表单参数。这个查询只会返回HistoricFormProperties(历史表单参数)。
historyService.createHistoricDetailQuery()
.formProperties()
.processInstanceId("123")
.orderByVariableName().asc()
.list()最后一个例子获取id为"123"的任务进行的所有变量更新操作。将返回该任务设置的所有变量(任务局部变量)的HistoricVariableUpdates,而不会返回流程实例中设置的变量。
historyService.createHistoricDetailQuery()
.variableUpdates()
.taskId("123")
.orderByVariableName().asc()
.list()可以在TaskListener中使用TaskService或DelegateTask设置任务局部变量:
taskService.setVariableLocal("123", "myVariable", "Variable value");public void notify(DelegateTask delegateTask) {
delegateTask.setVariableLocal("myVariable", "Variable value");
}11.1.5. 历史任务实例查询
获取所有任务中,完成所花费时间(持续时间)排名前10的、已完成的HistoricTaskInstance(历史任务实例)。
historyService.createHistoricTaskInstanceQuery()
.finished()
.orderByHistoricTaskInstanceDuration().desc()
.listPage(0, 10);获取删除原因包含"invalid"的、最终指派给kermit用户的HistoricTaskInstance。
historyService.createHistoricTaskInstanceQuery()
.finished()
.taskDeleteReasonLike("%invalid%")
.taskAssignee("kermit")
.listPage(0, 10);11.2. 配置历史
可以使用org.flowable.engine.impl.history.HistoryLevel枚举(或在5.11之前的版本中,ProcessEngineConfiguration中定义的HISTORY常量),以编程方式配置历史级别:
ProcessEngine processEngine = ProcessEngineConfiguration
.createProcessEngineConfigurationFromResourceDefault()
.setHistory(HistoryLevel.AUDIT.getKey())
.buildProcessEngine();也可以在flowable.cfg.xml或Spring上下文中配置级别:
<bean id="processEngineConfiguration" class="org.flowable.engine.impl.cfg.StandaloneInMemProcessEngineConfiguration">
<property name="history" value="audit" />
...
</bean>可以配置下列历史级别:
-
none(无):跳过所有历史的存档。这是流程执行性能最高的配置,但是不会保存任何历史信息。 -
activity(活动):存档所有流程实例与活动实例。在流程实例结束时,将顶级流程实例变量的最新值复制为历史变量实例。但不会存档细节。 -
audit(审计):默认级别。将存档所有流程实例及活动实例,并保持变量值与提交的表单参数的同步,以保证所有通过表单进行的用户操作都可追踪、可审计。 -
full(完全):历史存档的最高级别,因此也最慢。这个级别存储所有audit级别存储的信息,加上所有其他细节(主要是流程变量的更新)。
在Flowable 5.11版本以前,历史级别保存在数据库中(ACT_GE_PROPERTY 表,参数名为historyLevel)。从5.11开始,这个值不再使用,并从数据库中忽略/删除。现在可以在引擎每次启动时切换历史级别。不会由于前一次启动时修改了级别,而导致本次启动抛出异常。
11.3. 配置异步历史
[实验性] Flowable 6.1.0引入了异步历史,使用历史作业执行器异步地进行历史数据的持久化。
<bean id="processEngineConfiguration" class="org.flowable.engine.impl.cfg.StandaloneInMemProcessEngineConfiguration">
<property name="asyncHistoryEnabled" value="true" />
<property name="asyncHistoryExecutorNumberOfRetries" value="10" />
<property name="asyncHistoryExecutorActivate" value="true" />
...
</bean>配置asyncHistoryExecutorActivate参数后,流程引擎启动时会自动启动历史作业执行器。只有在测试(或不使用异步历史时)才应该设置为false。
asyncHistoryExecutorNumberOfRetries参数用于配置异步历史作业的重试次数。这个参数与普通的异步作业有些不同,因为历史作业可能需要更多周期才能成功完成。比如,首先需要在ACT_HI_TASK_表中创建一个历史的任务,然后才能在另一个历史作业中记录其办理人的更新。流程引擎配置中,这个参数的默认值为10。到达重试次数后,会忽略这个历史作业(且不会写入死信作业表中)。
另外,可以使用asyncHistoryExecutor参数配置异步执行器,与普通的异步作业执行器类似。
如果不在默认的历史表中保存历史数据,而是在NoSQL数据库(Elasticsearch、MongoDb、Cassandra等)或其他什么地方保存,可以覆盖处理作业的处理器:
-
使用
historyJobHandlers参数,配置全部自定义历史作业处理器的map -
或者,配置
customHistoryJobHandlers列表。启动时会将列表中的所有处理器加入historyJobHandlersmap中。
另外,也可以使用消息队列,让引擎在产生新的历史作业时发送消息。这样,历史数据就可以在另外的服务器中进行处理。也可以配置引擎及消息队列使用JTA(以及JMS),这样就可以不用在作业中记录历史数据,而可以将所有数据发送至全局事务的消息队列中。
Flowable异步历史示例提供了配置异步历史的不同示例,包括默认方式、JMS队列、JTA,还有使用消息队列,并使用Spring Boot应用作为消息监听器。
11.4. 用于审计的历史
如果历史至少配置为audit级别,则会记录由FormService.submitStartFormData(String processDefinitionId, Map<String, String> properties)与FormService.submitTaskFormData(String taskId, Map<String, String> properties)方法提交的所有参数。
表单参数可以像这样通过查询API读取:
historyService
.createHistoricDetailQuery()
.formProperties()
...
.list();这段代码只会返回HistoricFormProperty类型的历史详情。
如果在调用提交方法前,使用IdentityService.setAuthenticatedUserId(String)设置了认证用户,那么也可以在历史中获取该认证用户信息。使用HistoricProcessInstance.getStartUserId()获取启动表单的认证用户信息,任务表单则需使用HistoricActivityInstance.getAssignee()。
12. 身份管理
从Flowable V6起,身份管理(IDM IDentity Management)组件从Flowable引擎模块中抽出,并将其逻辑移至几个不同的模块:flowable-idm-api、flowable-idm-engine、flowable-idm-spring及flowable-idm-engine-configurator。分离IDM主要是因为它并不是Flowable引擎的核心,并且在很多将Flowable引擎嵌入应用的用例中,并不使用或需要这部分身份管理逻辑。
默认情况下,IDM引擎在Flowable引擎启动时初始化并启动。这样身份管理逻辑在Flowable V5中也可以使用。IDM引擎管理自己的数据库表结构及下列实体:
-
User与UserEntity,用户信息。
-
Group与GroupEntity,组信息。
-
MembershipEntity,组中的用户成员。
-
Privilege与PrivilegeEntity,权限定义(例如在Flowable Modeler与Flowable Task应用中,用于控制应用界面的访问)。
-
PrivilegeMappingEntity,将用户及/或组与权限关联。
-
Token与TokenEntity,应用界面程序使用的认证令牌。
历史与当前进行中的流程实例都在数据库中保存历史实体,因此可以选择直接查询历史表,以减少对运行时流程实例数据的访问,并提高运行时执行的性能。
12.1. 配置IDM引擎
默认情况下,IDM引擎使用org.flowable.engine.impl.cfg.IdmEngineConfigurator启动。这个配置器使用Flowable流程引擎配置中相同的数据源配置。这样使用身份管理就不需要进行额外的配置,就像在Flowable V5中一样。
如果Flowable引擎不需要身份管理,可以在流程引擎配置中禁用IDM引擎。
<bean id="processEngineConfiguration" class="org.flowable.engine.impl.cfg.StandaloneInMemProcessEngineConfiguration">
<property name="disableIdmEngine" value="true" />
...
</bean>这意味着不能使用用户与组进行查询,也不能在任务查询中,按用户查询其所在的候选组。
默认情况下,用户的密码以明文保存在IDM数据库表中。可以在流程引擎配置中定义一个加密算法,以确保密码加密。
<bean id="bCryptEncoder"
class="org.springframework.security.crypto.bcrypt.BCryptPasswordEncoder"/>
<bean id="passwordEncoder" class="org.flowable.idm.spring.authentication.SpringEncoder">
<constructor-arg ref="bCryptEncoder"/>
</bean>
<bean id="processEngineConfiguration" class="org.flowable.engine.impl.cfg.StandaloneInMemProcessEngineConfiguration">
<property name="passwordEncoder" ref="passwordEncoder" />
...
</bean>这里使用的是ShaPasswordEncoder,但也可以使用其他的加密算法,如org.springframework.security.crypto.bcrypt.BCryptPasswordEncoder,不使用Spring的话也可以改用org.flowable.idm.engine.impl.authentication.ApacheDigester。
也可以覆盖默认的IDM引擎配置器,使用自定义方式初始化IDM引擎。LDAPConfigurator的实现就是一个很好的例子。它覆盖了默认的IDM引擎,使用LDAP服务代替了默认的IDM数据库表。流程引擎配置的idmProcessEngineConfigurator参数用于设置自定义的配置器,如LDAPConfigurator
<bean id="processEngineConfiguration" class="...SomeProcessEngineConfigurationClass">
...
<property name="idmProcessEngineConfigurator">
<bean class="org.flowable.ldap.LDAPConfigurator">
<!-- 服务器连接参数 -->
<property name="server" value="ldap://localhost" />
<property name="port" value="33389" />
<property name="user" value="uid=admin, ou=users, o=flowable" />
<property name="password" value="pass" />
<!-- 查询参数 -->
<property name="baseDn" value="o=flowable" />
<property name="queryUserByUserId" value="(&(objectClass=inetOrgPerson)(uid={0}))" />
<property name="queryUserByFullNameLike" value="(&(objectClass=inetOrgPerson)(|({0}=*{1}*)({2}=*{3}*)))" />
<property name="queryGroupsForUser" value="(&(objectClass=groupOfUniqueNames)(uniqueMember={0}))" />
<!-- 配置参数 -->
<property name="userIdAttribute" value="uid" />
<property name="userFirstNameAttribute" value="cn" />
<property name="userLastNameAttribute" value="sn" />
<property name="userEmailAttribute" value="mail" />
<property name="groupIdAttribute" value="cn" />
<property name="groupNameAttribute" value="cn" />
</bean>
</property>
</bean>13. Eclipse Designer
Flowable提供了名为Flowable Eclipse Designer的Eclipse插件,可以用于图形化地建模、测试与部署BPMN 2.0流程。
13.1. 安装
下面的安装指导在Eclipse Mars与Neon下进行了验证。
选择Help → Install New Software。在下图面板中,点击Add按钮,并填写下列字段:
-
Name: Flowable BPMN 2.0 designer
-
Location: http://www.flowable.org/designer/update/
确保已选中"Contact all updates sites.."复选框。这样Eclipse就可以下载需要的所有插件。
13.2. Flowable Designer编辑器功能
-
创建Flowable项目与流程图(diagram)。
-
Flowable Designer在创建新的Flowable流程图时,会创建一个.bpmn文件。当使用Flowable Diagram Editor(Flowable流程图编辑器)视图打开时,将提供图形化的模型画布与画板。这个文件也可以使用XML编辑器打开,将显示流程定义的BPMN 2.0 XML元素。也就是说,Flowable Designer只用一个文件,既是流程图,也是BPMN 2.0 XML。请注意在早期版本中,不支持使用.bpmn扩展名作为流程定义的部署包。可以使用Flowable Designer的"create deployment artifacts(创建部署包)"功能,生成一个BAR文件,其中有一个.bpmn20.xml文件,包含.bpmn文件的内容。也可以方便的自己重命名。请注意,也可以使用Flowable Diagram Editor打开.bpmn20.xml文件。
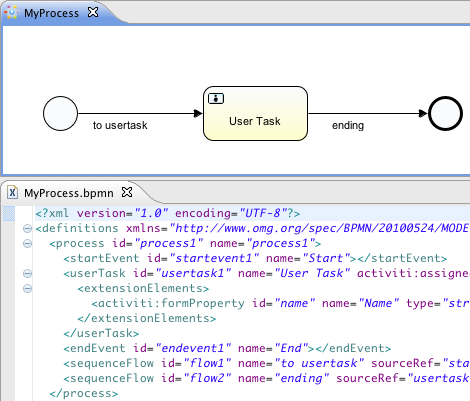
-
BPMN 2.0 XML文件导入Flowable Designer会自动显示流程图。只需要将BPMN 2.0 XML文件复制到项目中,并使用Flowable Diagram Editor视图打开它。Flowable Designer使用文件中的BPMN DI信息来创建流程图。如果BPMN 2.0 XML文件中没有BPMN DI信息,会使用Flowable BPMN自动布局模块,创建流程图。
-
可以使用Flowable Designer创建BAR文件或JAR文件进行部署。在包浏览器中的Flowable项目上点击右键,在弹出菜单的下方选择Create deployment artifacts(创建部署包)选项。要了解关于Designer部署功能的更多信息,请查看部署章节。
-
生成单元测试(在包浏览器中的BPMN 2.0 XML文件上点击右键,选择generate unit test 生成单元测试)。将创建一个单元测试及运行在嵌入式H2数据库上的Flowable配置。这样就可以运行单元测试,来测试你的流程定义。
-
Flowable项目可以生成为Maven项目。要配置依赖,需要运行mvn eclipse:eclipse。请注意在流程设计时不需要Maven依赖。只在运行单元测试时才需要依赖。
13.3. Flowable Designer BPMN功能
-
支持空启动事件,错误启动事件,定时器启动事件,空结束事件,错误结束事件,顺序流,并行网关,排他网关,包容网关,事件网关,嵌入式子流程,事件子流程,调用活动,泳池,泳道,脚本任务,用户任务,服务任务,邮件任务,手动任务,业务规则任务,接收任务,定时器边界事件,错误边界事件,信号边界事件,定时器捕获事件,信号捕获事件,信号抛出事件,空抛出事件,以及四个Flowable特殊元素(用户,脚本,邮件任务与启动事件)。
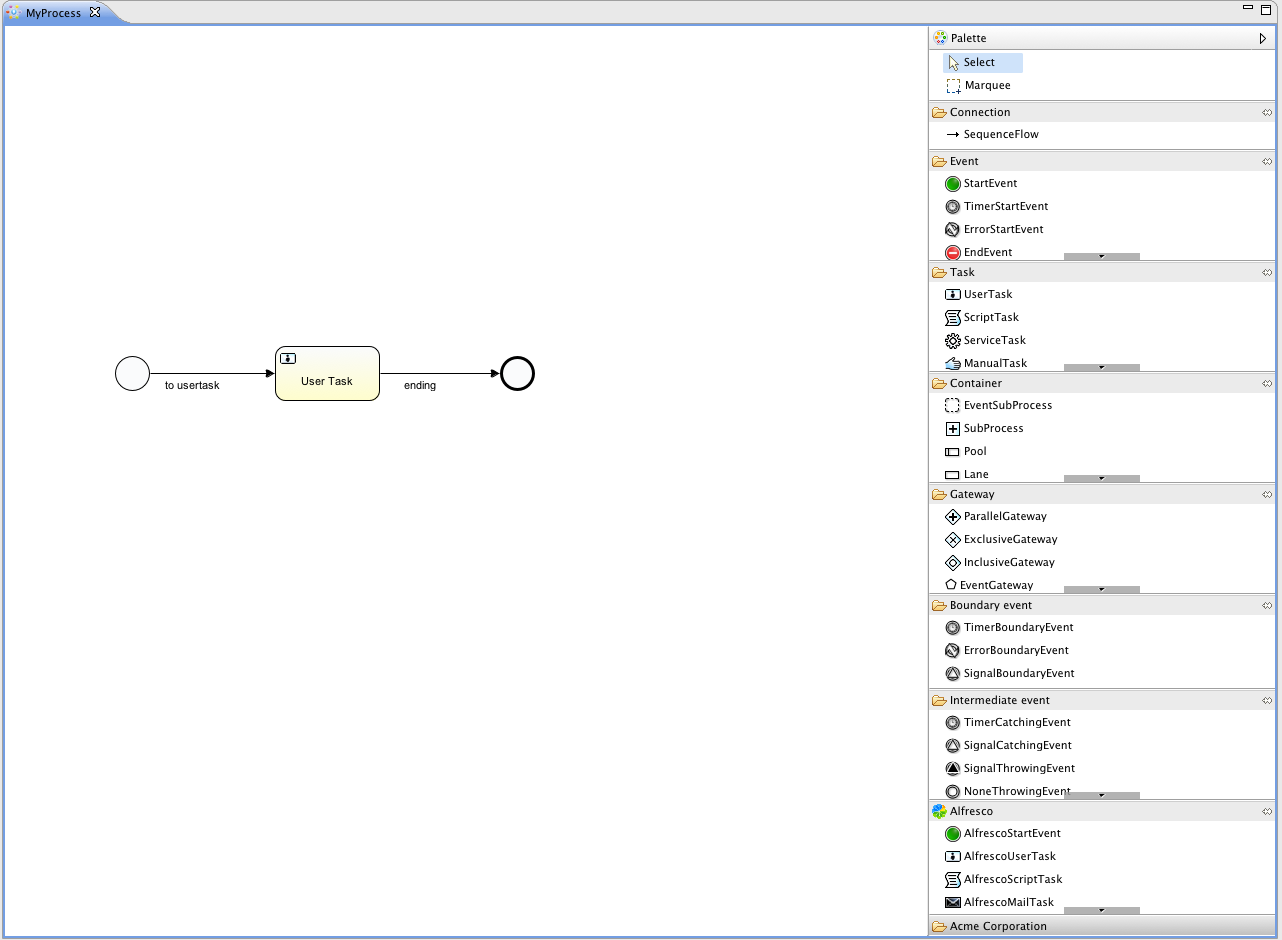
-
可以在元素上悬停并选择新的任务类型,快速改变任务的类型。
-
可以在元素上悬停并选择新的元素类型,快速添加新的元素。
-
Java服务任务支持Java类,表达式或代理表达式配置。另外也可以配置字段扩展。
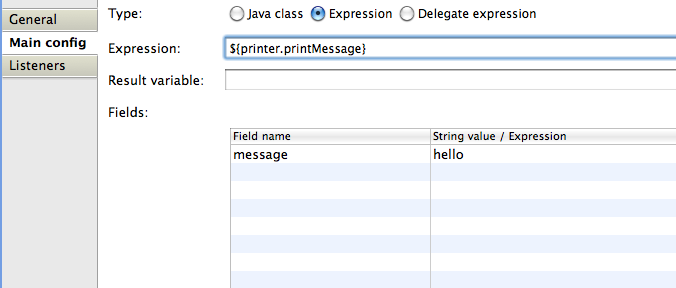
-
支持泳池与泳道。但由于Flowable会将不同的泳池认作不同的流程定义,因此最好只使用一个泳池。如果使用多个泳池,要小心不要在泳池间画顺序流,否则会在Flowable引擎中部署流程时发生错误。可以在一个泳池中添加任意多的泳道。

-
可以通过填写name参数,为顺序流添加标签。可以决定放置标签的位置,位置将保存为BPMN 2.0 XML DI信息的一部分。
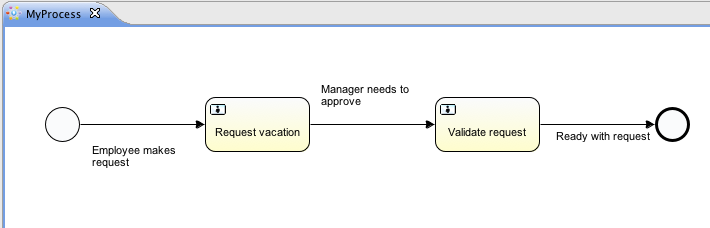
-
支持事件子流程。
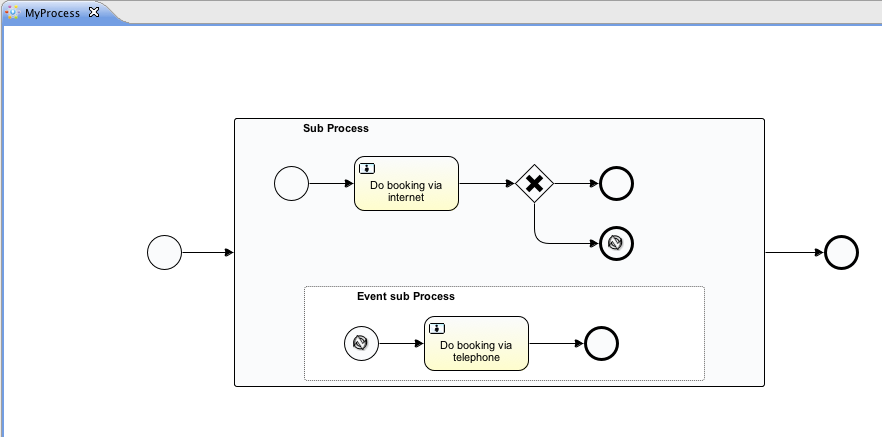
-
支持展开嵌入式子流程。也可以在一个嵌入式子流程中加入另一个嵌入式子流程。
-
支持在任务与嵌入式子流程上的定时器边界事件。然而,在Flowable Designer中,在用户任务或嵌入式子流程上使用定时器边界事件最合理。
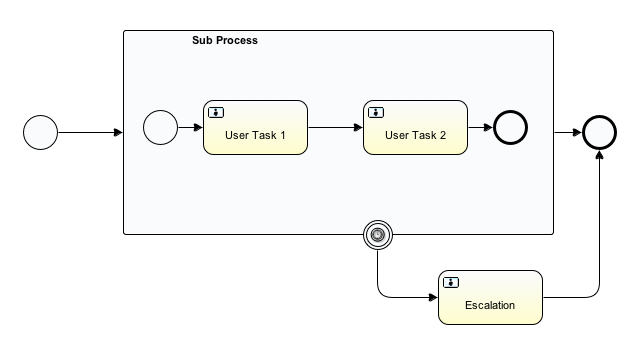
-
支持额外的Flowable扩展,例如邮件任务,用户任务的候选人配置,或脚本任务配置。
-
支持Flowable执行与任务监听器。也可以为执行监听器添加字段扩展。
-
支持在顺序流上添加条件。
13.4. Flowable Designer部署功能
在Flowable引擎上部署流程定义与任务表单并不困难。只需要提供一个包含有流程定义BPMN 2.0 XML文件的BAR文件,与可选的用于在Flowable应用中查看的任务表单和流程图片。在Flowable Designer中,创建BAR文件十分简单。在完成流程实现后,只要在包浏览器中的Flowable项目上点击右键,在弹出菜单下方选择Create deployment artifacts(创建部署包)选项。
然后就会创建一个部署目录,包含BAR文件与可能的JAR文件。其中JAR文件包含Flowable项目中的Java类。
这样就可以在Flowable Admin应用的部署页签中,将这个文件上传至Flowable引擎。
如果项目包含Java类,部署时要多做一些工作。在这种情况下,Flowable Designer的Create deployment artifacts(创建部署包)操作也会创建包含编译后类的JAR文件。这个JAR文件必须部署在Flowable Tomcat(或其它容器)安装目录的flowable-XXX/WEB-INF/lib目录下。这样Flowable引擎的classpath就会添加这些类。
13.5. 扩展Flowable Designer
可以扩展Flowable Designer提供的默认功能。这段文档介绍了可以使用哪些扩展,如何使用,并提供了一些例子。在建模业务流程时,如果默认功能不能满足需要,需要额外的功能,或有领域专门需求的时候,扩展Flowable Designer就很有用。扩展Flowable Designer分为两个不同领域,扩展画板与扩展输出格式。两者都需要专门的方法,与不同的技术知识。
|
扩展Flowable Designer需要专业知识,更确切地说,Java编程的知识。取决于你想要创建的扩展类型,你可能需要熟悉Maven,Eclipse,OSGi,Eclipse扩展与SWT。 |
13.5.1. 自定义画板
可以自定义为用户建模流程提供的画板。画板是形状的集合,显示在画布的右侧,可以将形状拖放至画布中的流程图上。在默认画板中可以看到,默认形状进行了分组(被称为“抽屉 drawer”),如事件,网关,等等。Flowable Designer提供了两种选择,用于自定义画板中的抽屉与形状:
-
将你自己的形状/节点添加到已有或新建的抽屉
-
禁用Flowable Designer提供的部分或全部BPMN 2.0默认形状,除了连线与选择工具
要自定义画板,需要创建一个JAR文件,并将其加入每一个Flowable Designer的安装目录(后面介绍如何做)。这个JAR文件叫做扩展(extension)。通过编写扩展中包含的类,就能让Flowable Designer知道需要自定义的形状。为此需要实现特定的接口。Flowable提供了一个集成类库,包含这些接口以及用于扩展的基类。
可以在下列地方找到代码示例:Flowable 源码,flowable-designer仓库下的examples/money-tasks目录。
|
可以使用你喜欢的任何工具设置项目,并使用你选择的构建工具构建JAR。在下面的介绍中,假设使用Eclipse Mars或Neon,并使用Maven(3.x)作为构建工具。但任何设置都可以创建相同的结果。 |
设置扩展 (Eclipse/Maven)
下载并解压缩Eclipse(应该可以使用最新版本),与Apache Maven近期的版本(3.x)。如果使用2.x版本的Maven,可能会在构建项目时遇到错误,因此请确保版本是最新的。我们假设你已经熟悉Eclipse中的基本功能以及Java编辑器。可以使用Eclipse的Maven功能,或直接从命令行运行Maven命令。
在Eclipse中创建一个新项目。可以是通用类型项目。在项目的根路径创建一个pom.xml文件,以包含Maven项目配置。同时创建src/main/java与src/main/resources目录,这是Maven约定的Java源文件与资源文件目录。打开pom.xml文件并添加下列行:
<project
xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.acme</groupId>
<artifactId>money-tasks</artifactId>
<version>1.0.0</version>
<packaging>jar</packaging>
<name>Acme Corporation Money Tasks</name>
...
</project>可以看到,这只是一个基础的pom.xml文件,为项目定义了一个groupId、artifactId与version。我们会创建一个定制项,包含一个money业务要用的自定义节点。
在pom.xml文件中为项目添加这些集成库依赖:
<dependencies>
<dependency>
<groupId>org.flowable.designer</groupId>
<artifactId>org.flowable.designer.integration</artifactId>
<version>5.22.0</version> <!-- 使用当前的Flowable Designer版本 -->
<scope>compile</scope>
</dependency>
</dependencies>
...
<repositories>
<repository>
<id>Flowable</id>
</repository>
</repositories>最后,在pom.xml文件中,添加maven-compiler-plugin配置,设置Java源码级别为1.5以上(参见下面的代码片段)。要使用注解需要这个配置。也可以为Maven包含用于生成JAR的MANIFEST.MF文件。这不是必须的,但可以在这个manifest中使用特定参数,为你的扩展提供名字(这个名字可以在设计器的特定位置显示,主要用于在设计器中有多个扩展时使用)。如果想要这么做,在pom.xml中添加下列代码片段:
<build>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>1.8</source>
<target>1.8</target>
<showDeprecation>true</showDeprecation>
<showWarnings>true</showWarnings>
<optimize>true</optimize>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-jar-plugin</artifactId>
<version>2.3.2</version>
<configuration>
<archive>
<index>true</index>
<manifest>
<addClasspath>false</addClasspath>
<addDefaultImplementationEntries>true</addDefaultImplementationEntries>
</manifest>
<manifestEntries>
<FlowableDesigner-Extension-Name>Acme Money</FlowableDesigner-Extension-Name>
</manifestEntries>
</archive>
</configuration>
</plugin>
</plugins>
</build>扩展的名字使用FlowableDesigner-Extension-Name参数描述。现在只剩下让Eclipse按照pom.xml的指导设置项目。因此打开命令行,并转到Eclipse工作空间中你项目的根目录。然后执行下列Maven命令:
mvn eclipse:eclipse
等待构建完成。刷新项目(使用项目上下文菜单(右键点击),并选择Refresh 刷新)。现在Eclipse项目中应该已经建立了src/main/java与src/main/resources源码目录。
|
当然也可以使用m2eclipse插件,并简单地在项目的上下文菜单(右键点击)中启用Maven依赖管理。然后在项目的上下文菜单中选择 |
这就完成了配置。现在可以开始为Flowable Designer创建自定义项了!
在Flowable Designer中应用你的扩展
你也许想知道如何将你的扩展加入Flowable Designer,以便应用你的自定义项。需要这些步骤:
-
创建扩展JAR(例如,使用Maven构建时,在项目中运行mvn install)后,需要将扩展传递至Flowable Designer安装的计算机;
-
将扩展存储在硬盘上,方便记忆的位置。请注意:必须保存在Flowable Designer的Eclipse工作空间之外——将扩展保存在工作空间内,会导致弹出错误消息弹框,扩展将不可用;
-
启动Flowable Designer,从菜单中,选择
Window>Preferences,或Eclipse>Preferences -
在Preferences界面,键入
user作为关键字。将可以看到在Eclipse中Java段落内,User Libraries的选项。
-
选择
User Libraries选项,将在右侧显示树形界面,可以添加库。应该可以看到一个默认组,可以用于添加Flowable Designer的扩展(根据Eclipse安装不同,也可能看到几个其他的)。

-
选择
Flowable Designer Extensions组,并点击Add JARs…或Add External JARs…按钮。跳转至存储扩展的目录,并选择希望添加的扩展文件。完成后,配置界面会将扩展作为Flowable Designer Extensions组的成员进行显示,像下面这样。
-
点击
OK按钮保存并关闭配置对话框。Flowable Designer Extensions会自动添加至你创建的新Flowable项目。可以在导航条或包管理器的项目树下的用户库条目中看到。如果工作空间中已经有了Flowable项目,也可以看到组中显示了新扩展,像下面这样。

打开的流程图将在其画板上显示新扩展的图形(或者禁用部分图形,取决于扩展中的配置)。如果已经打开了流程图,关闭并重新打开就能在画板上看到变化。
为画板添加图形
项目配置完后,可以很轻松的为画板添加图形。每个添加的图形都表现为JAR中的一个类。请注意这些类并不是Flowable引擎运行时会使用的类。在扩展中可以为每个图形描述Flowable Designer可用的参数。在这些图形中,也可以定义运行时特性,并将由引擎在流程实例到达该节点时使用。运行时特性可以使用任何Flowable对普通ServiceTask支持的选项。查看这个章节了解更多信息。
图形的类是简单的Java类,加上一些注解。这个类需要实现CustomServiceTask接口,但不应该直接实现这个接口,而应该扩展AbstractCustomServiceTask基类(目前必须直接扩展这个类,而不能在中间使用abstract类)。在这个类的Javadoc中,可以看到其默认提供的,与需要覆盖的方法介绍。覆盖可以实现很多功能,例如为画板及画布中的图形提供图标(两个可以不一样),或者指定你希望节点实现的基图形(活动,时间,网关)。
/**
* @author John Doe
* @version 1
* @since 1.0.0
*/
public class AcmeMoneyTask extends AbstractCustomServiceTask {
...
}需要实现getName()方法,来决定节点在画板上的名字。也可以将节点放在自己的抽屉中,并提供图标,只需要覆盖AbstractCustomServiceTask的对应方法就可以。如果希望提供图标,请确保放在JAR的src/main/resources包中,需要是16X16像素的JPEG或PNG格式图片。你要提供的路径是到这个目录的相对路径。
可以通过在类中添加成员,并使用@Property注解,来为形状添加参数。像这样:
@Property(type = PropertyType.TEXT, displayName = "Account Number")
@Help(displayHelpShort = "提供一个账户编码 Provide an account number", displayHelpLong = HELP_ACCOUNT_NUMBER_LONG)
private String accountNumber;可以使用多种PropertyType值,在这个章节中详细描述。可以通过将required属性设置为true,将一个字段设为必填。如果用户没有填写这个字段,将会提示消息,背景也会变红。
如果想要调整类中多个参数在参数界面上的显示顺序,需要指定@Property注解的order属性。
可以看到有个@Help注解,它用于为用户提供一些填写字段的指导。也可以在类本身上使用@Help注解——这个信息将在显示给用户的参数表格最上面显示。
下面是MoneyTask详细介绍的列表。添加了一个备注字段,也可以看到节点包含了一个图标。
/**
* @author John Doe
* @version 1
* @since 1.0.0
*/
@Runtime(javaDelegateClass = "org.acme.runtime.AcmeMoneyJavaDelegation")
@Help(displayHelpShort = "创建一个新的账户 Creates a new account", displayHelpLong =
"使用给定的账户编码,创建一个新的账户 Creates a new account using the account number specified")
public class AcmeMoneyTask extends AbstractCustomServiceTask {
private static final String HELP_ACCOUNT_NUMBER_LONG =
"提供一个可用作账户编码的编码。 Provide a number that is suitable as an account number.";
@Property(type = PropertyType.TEXT, displayName = "Account Number", required = true)
@Help(displayHelpShort = "提供一个账户编码 Provide an account number", displayHelpLong = HELP_ACCOUNT_NUMBER_LONG)
private String accountNumber;
@Property(type = PropertyType.MULTILINE_TEXT, displayName = "Comments")
@Help(displayHelpShort = "提供备注 Provide comments", displayHelpLong =
"可以为节点添加备注,以提供详细说明。 You can add comments to the node to provide a brief description.")
private String comments;
@Override
public String contributeToPaletteDrawer() {
return "Acme Corporation";
}
@Override
public String getName() {
return "Money node";
}
@Override
public String getSmallIconPath() {
return "icons/coins.png";
}
}如果使用这个图形扩展Flowable Designer,画板与相应的图形将像是这样:
money任务的参数界面在下面显示。请注意accountNumber字段的必填信息。
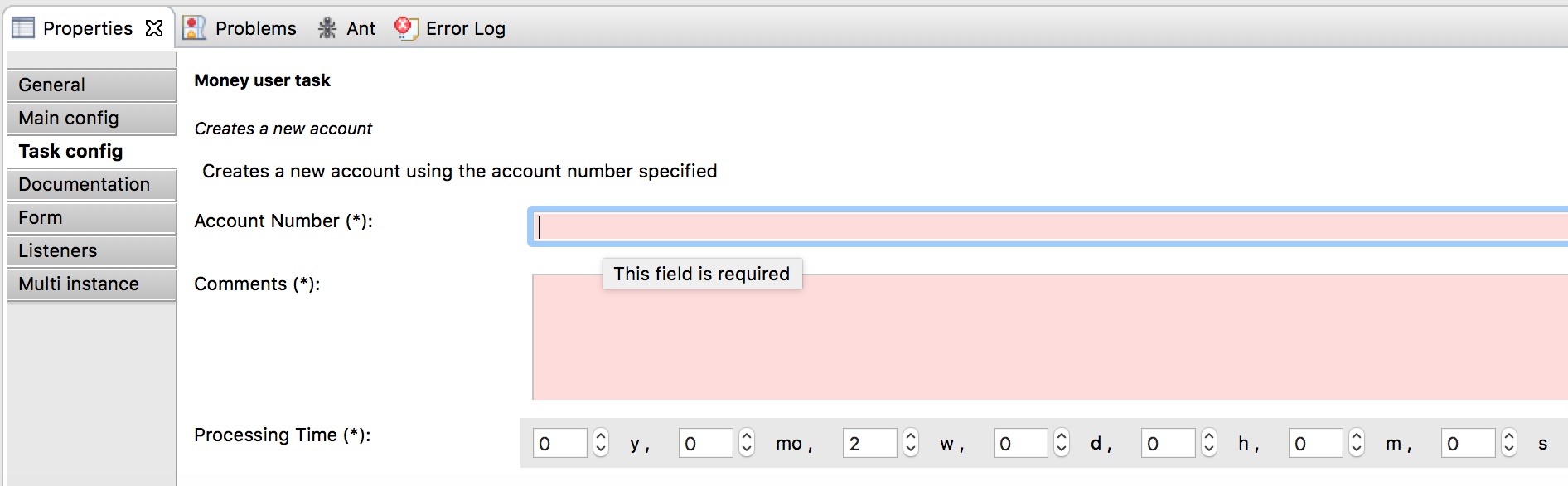
在创建流程图、填写参数字段时,用户可以使用静态文本,或者使用流程变量的表达式(如"This little piggy went to ${piggyLocation}")。一般来说,用户可以在text字段自由填写任何文本。如果你希望用户使用表达式,并(使用@Runtime)为CustomServiceTask添加运行时行为,请确保在代理类中使用Expression字段,以便表达式可以在运行时正确解析。可以在这个章节找到更多关于运行时行为的信息。
字段的帮助信息由每个参数右侧的按钮提供。点击该按钮将弹出显示下列内容。

配置自定义服务任务的运行时执行
当设置好字段,并将扩展应用至Designer后,用户就可以在建模流程时,配置服务任务的这些参数。在大多数情况下,会希望在Flowable执行流程时,使用这些用户配置参数。要做到这一点,必须告诉Flowable,当流程到达你CustomServiceTask时,需要使用哪个类。
有一个特别的注解,@Runtime,用于指定CustomServiceTask的运行时特性。这里有些如何使用的例子:
@Runtime(javaDelegateClass = "org.acme.runtime.AcmeMoneyJavaDelegation")使用时,CustomServiceTask将会表现为流程建模BPMN中的一个普通的ServiceTask。Flowable提供了多种方法定义ServiceTask的运行时特性。因此,@Runtime可以使用Flowable提供的三个属性中的一个:
-
javaDelegateClass在BPMN输出中映射为flowable:class。指定一个实现了JavaDelegate的类的全限定类名。 -
expression在BPMN输出中映射为flowable:expression。指定一个需要执行的方法的表达式,例如一个Spring Bean中的方法。当使用这个选项时,不应在字段上指定任何@Property注解。下面有更详细的说明。 -
javaDelegateExpression在BPMN输出中映射为flowable:delegateExpression。指定一个实现了JavaDelegate的类的表达式。
如果在类中为Flowable提供了可以注入的成员,就可以将用户的参数至注入到运行时类中。名字需要与CustomServiceTask的成员名一致。查看用户手册的这个部分了解更多信息。请注意从Designer的5.11.0版本开始,可以为动态字段值使用Expression接口。这意味着Flowable Designer中参数的值必须要是表达式,并且这个表达式将在之后注入JavaDelegate实现类的Expression参数中。
|
可以在 |
|
请注意不应该在你的扩展JAR中包括运行时类,因为它与Flowable库是分离的。Flowable需要在运行时能够找到它们,因此需要将其放在Flowable引擎的classpath中。 |
Designer代码树中的示例项目包含了配置@Runtime的不同选项的例子。可以从查看money-tasks项目开始。引用代理类的示例在money-delegates项目中。
参数类型
这个章节介绍了CustomServiceTask能够使用的参数类型,可以将类型设置为PropertyType的值。
PropertyType.TEXT
创建如下所示的单行文本字段。可以是必填字段,并将验证消息作为提示信息显示。验证失败会将字段的背景变为浅红色。

PropertyType.MULTILINE_TEXT
创建如下所示的多行文本字段(高度固定为80像素)。可以是必填字段,并将验证消息作为提示信息显示。验证失败会将字段的背景变为浅红色。

PropertyType.PERIOD
创建一个组合编辑框,可以使用转盘控件编辑每一个单位的数量,来指定一段时间长度,结果如下所示。可以是必填字段(含义是不能所有的值都是0,也就是至少有一个部分要有非零值),并将验证消息作为提示信息显示。验证失败会将整个字段的背景变为浅红色。字段的值保存为1y 2mo 3w 4d 5h 6m 7s格式的字符串,代表1年,2月,3周,4天,6分钟及7秒。即使有部分为0,也总是存储整个字符串。

PropertyType.BOOLEAN_CHOICE
创建一个单独的boolean复选框,或者开关选择。请注意可以在Property注解上指定required属性,但不会生效,不然用户就无法选择是否选中复选框。流程图中存储的值为java.lang.Boolean.toString(boolean),其结果为"true"或"false"。

PropertyType.RADIO_CHOICE
创建如下所示的一组单选按钮。选中任何一个单选按钮都自动排除任何其他的选择(也就是说,单选)。可以是必填字段,并将验证消息作为提示信息显示。验证失败会将组的背景变为浅红色。
这个参数类型需要注解的类成员同时使用@PropertyItems注解(例如如下所示)。可以使用这个额外的注解,以字符串数组的方式,指定条目的列表。需要为每一个条目添加两个数组项:第一个,用于显示的标签;第二个,用于存储的值。
@Property(type = PropertyType.RADIO_CHOICE, displayName = "Withdrawl limit", required = true)
@Help(displayHelpShort = "最大每日提款限额 The maximum daily withdrawl amount ",
displayHelpLong = "选择从该账户中每日最大能提取的额度。 Choose the maximum daily amount that can be withdrawn from the account.")
@PropertyItems({ LIMIT_LOW_LABEL, LIMIT_LOW_VALUE, LIMIT_MEDIUM_LABEL, LIMIT_MEDIUM_VALUE,
LIMIT_HIGH_LABEL, LIMIT_HIGH_VALUE })
private String withdrawlLimit;

PropertyType.COMBOBOX_CHOICE
创建如下所示的,带有固定选项的下拉框。可以是必填字段,并将验证消息作为提示信息显示。验证失败会将下拉框的背景变为浅红色。
这个参数类型需要注解的类成员同时使用@PropertyItems注解(例如如下所示)。可以使用这个额外的注解,以字符串数组的方式,指定条目的列表。需要为每一个条目添加两个数组项:第一个,用于显示的标签;第二个,用于存储的值。
@Property(type = PropertyType.COMBOBOX_CHOICE, displayName = "Account type", required = true)
@Help(displayHelpShort = "账户的类型 The type of account",
displayHelpLong = "从选项列表中选择账户的类型 Choose a type of account from the list of options")
@PropertyItems({ ACCOUNT_TYPE_SAVINGS_LABEL, ACCOUNT_TYPE_SAVINGS_VALUE, ACCOUNT_TYPE_JUNIOR_LABEL,
ACCOUNT_TYPE_JUNIOR_VALUE, ACCOUNT_TYPE_JOINT_LABEL, ACCOUNT_TYPE_JOINT_VALUE,
ACCOUNT_TYPE_TRANSACTIONAL_LABEL, ACCOUNT_TYPE_TRANSACTIONAL_VALUE, ACCOUNT_TYPE_STUDENT_LABEL,
ACCOUNT_TYPE_STUDENT_VALUE, ACCOUNT_TYPE_SENIOR_LABEL, ACCOUNT_TYPE_SENIOR_VALUE })
private String accountType;

PropertyType.DATE_PICKER
创建如下所示的日期选择控件。可以是必填字段,并将验证消息作为提示信息显示(请注意,这个控件会自动填入当前系统时间,因此值很难为空)。验证失败会将控件的背景变为浅红色。
这个参数类型需要注解的类成员同时使用@DatePickerProperty注解(例如如下所示)。可以使用这个额外的注解,指定在流程图中存储日期时使用的日期格式,以及要用于显示的日期选择类型。这些属性都是可选的,当没有指定时会使用默认值(DatePickerProperty注解的静态变量)。dateTimePattern属性应该使用SimpleDateFormat类支持的格式。当使用swtStyle属性时,应该指定SWT的DateTime控件支持的整形值,因为将使用这个控件渲染这个类型的参数。
@Property(type = PropertyType.DATE_PICKER, displayName = "Expiry date", required = true)
@Help(displayHelpShort = "账户过期的日期 The date the account expires.",
displayHelpLong = "选择一个日期,如果账户未在该日期前延期,则将过期。Choose the date when the account will expire if not extended before the date.")
@DatePickerProperty(dateTimePattern = "MM-dd-yyyy", swtStyle = 32)
private String expiryDate;
PropertyType.DATA_GRID
创建一个如下所示的数据表格控件。数据表格可以让用户输入任意行数据,并为每一行输入固定列数的值(每一组行列的组合代表一个单元格)。用户可以添加与删除行。
这个参数类型需要注解的类成员同时使用@DataGridProperty注解(例如如下所示)。可以使用这个额外的注解,指定数据表格的细节属性。需要用itemClass属性引用另一个类,来决定表格中有哪些列。Flowable Designer期望其成员类型为List。按照约定,可以将itemClass属性的类用作其泛型类型。如果,例如,在表格中编辑一个杂货清单,用GroceryListItem类定义表格的列。在CustomServiceTask中,可以这样引用它:
@Property(type = PropertyType.DATA_GRID, displayName = "Grocery List")
@DataGridProperty(itemClass = GroceryListItem.class)
private List<GroceryListItem> groceryList;与CustomServiceTask一样,"itemClass"可以使用相同的注解指定字段类型(除了数据表格)。目前支持TEXT,MULTILINE_TEXT 与PERIOD。你会注意到不论其PropertyType是什么,表格都会为每个字段创建一个单行文本控件。这是为了表格保持整洁与可读。如果考虑下PERIOD这种PropertyType的显示模式,就可以想象出它绝不适合在表格的单元格中显示。对于 MULTILINE_TEXT 与PERIOD,会为每个字段添加双击机制,并会为该PropertyType弹出更大的编辑器。数值将在用户点击OK后存储至字段,因此可以在表格中显示。
必选属性使用与普通TEXT字段类似的方式处理,当任何字段失去焦点时,会验证整个表格。验证失败的单元格,背景色将变为浅红色。
默认情况下,这个组件允许用户添加行,但不能决定行的顺序。如果希望允许排序,需要将orderable属性设置为true,这将在每一行末尾启用按钮,以将该行在表格内上移或下移。
|
目前,这个参数类型不能正确注入运行时类。 |

在画板中禁用默认图形
这种自定义需要在你的扩展中引入一个实现了DefaultPaletteCustomizer接口的类。不应该直接实现这个接口,而要扩展AbstractDefaultPaletteCustomizer基类。目前,这个类不提供任何功能,但DefaultPaletteCustomizer未来的版本中会提供更多功能,这样基类将提供更多合理的默认值。因此最好使用它的子类,这样你的扩展将可以兼容未来的版本。
扩展AbstractDefaultPaletteCustomizer需要实现一个方法,disablePaletteEntries(),并必须返回一个PaletteEntry值的list。请注意如果从默认集合中移除图形,导致某个抽屉中没有图形,则该抽屉也会被移除。如果需要禁用所有的默认图形,只需要在结果中添加PaletteEntry.ALL。作为例子,下面的代码禁用了画板中的手动任务和脚本任务图形。
public class MyPaletteCustomizer extends AbstractDefaultPaletteCustomizer {
@Override
public List<PaletteEntry> disablePaletteEntries() {
List<PaletteEntry> result = new ArrayList<PaletteEntry>();
result.add(PaletteEntry.MANUAL_TASK);
result.add(PaletteEntry.SCRIPT_TASK);
return result;
}
}应用这个扩展的结果在下图显示。可以看到,在Tasks抽屉中不再显示手动任务与脚本任务图形。
要禁用所有默认图形,需要使用类似下面的代码。
public class MyPaletteCustomizer extends AbstractDefaultPaletteCustomizer {
@Override
public List<PaletteEntry> disablePaletteEntries() {
List<PaletteEntry> result = new ArrayList<PaletteEntry>();
result.add(PaletteEntry.ALL);
return result;
}
}结果像是这样(请注意画板中不再显示默认图形所在的抽屉):
13.5.2. 验证流程图与输出为自定义格式
除了自定义画板,也可以为Flowable Designer创建扩展,来进行流程图验证,以及将流程图的信息保存为Eclipse工作空间中的自定义资源。可以通过内建的扩展点实现 ,这个章节将介绍如何做。
|
保存功能最近正在重构。我们仍在开发验证功能。下面的文档记录的是旧的情况,并将在新功能可用后更新。 |
Flowable Designer可以编写用于验证流程图的扩展。默认情况已经可以在工具中验证BPMN结构,但你也可以添加自己的,如果希望验证额外的条目,例如建模约定,或者CustomServiceTask中的参数值。这些扩展被称作Process Validators。
也可以自定义配置,在Flowable Designer保存流程图时,发布为其它格式。这些扩展被称作Export Marshallers,将在每次用户进行保存操作时,由Flowable Designer自动调用。这个行为可以在Eclipse配置对话框中,为每一种扩展检测出的格式,分别启用或禁用。Designer会根据用户的配置,确保在保存流程图时,调用你的ExportMarshaller。
通常,会想要将ProcessValidator与ExportMarshaller一起使用。例如有一些CustomServiceTask,带有一些希望在流程中使用的参数。然而,在生成流程前,希望验证其中一些值。联合使用ProcessValidator与ExportMarshaller是最佳的方式,Flowable Designer也允许你无缝拼接扩展。
要创建一个ProcessValidator或ExportMarshaller,需要创建与扩展画板不同的扩展类型。原因很简单:你的代码会需访问比集成库中提供的更多的API。特别是,会需要使用Eclipse的类。因此从一开始,就需要创建一个Eclipse插件(可以使用Eclipse的PDE支持完成),并将其打包为自定义Eclipse产品或特性。解释开发Eclipse插件的所有细节,已经不是本用户手册的范畴,因此下面的介绍仅限于扩展Flowable Designer的功能。
扩展包需要依赖下列库:
-
org.eclipse.core.runtime
-
org.eclipse.core.resources
-
org.flowable.designer.eclipse
-
org.flowable.designer.libs
-
org.flowable.designer.util
可选的,如果希望在扩展中使用,可以通过Designer使用org.apache.commons.lang包。
ProcessValidator与ExportMarshaller都是通过扩展基类创建的。这些基类从其父类AbstractDiagramWorker继承了一些有用的方法。使用这些方法,可以创建在Eclipse问题视图中显示的提示信息,警告,错误标记,以便用户了解错误与重要的信息。可以以Resources与InputStreams的格式获取流程图的信息,这些信息由DiagramWorkerContext提供,在AbstractDiagramWorker中可用。
不论是ProcessValidator还是ExportMarshaller中,做任何事情前最好调用clearMarkers();这将清除任何已有的标记(标记自动连接至操作,清除一个操作的标记不会影响其他操作的标记)。例如:
// 首先清除流程图的标记 Clear markers for this diagram first
clearMarkersForDiagram();也需要使用(DiagramWorkerContext中)提供的进度监控,将你的进度报告给用户,因为验证与保存操作可能花费很多时间,而用户只能等待。报告进度需要了解如何使用Eclipse的功能。查看这篇文章了解详细概念与用法。
创建ProcessValidator扩展
在你的plugin.xml文件中,创建一个org.flowable.designer.eclipse.extension.validation.ProcessValidator扩展点的扩展。这个扩展点需要扩展AbstractProcessValidator类。
<?eclipse version="3.6"?>
<plugin>
<extension
point="org.flowable.designer.eclipse.extension.validation.ProcessValidator">
<ProcessValidator
class="org.acme.validation.AcmeProcessValidator">
</ProcessValidator>
</extension>
</plugin>public class AcmeProcessValidator extends AbstractProcessValidator {
}需要实现一些方法。最重要的是实现getValidatorId(),为验证器返回全局唯一ID。这将使你可以在ExportMarshaller中调用它,或者允许其他ExportMarshaller调用你的验证器。实现getValidatorName(),为验证器返回逻辑名字。这个名字将在对话框中显示给用户。getFormatName()可以返回这个验证器通常验证的流程图类型。
验证工作通过validateDiagram()方法实现。从这里开始,就是你自己的功能代码了。然而,通常你会想从获取流程中的所有节点开始,这样就可以迭代访问,收集、比较与验证数据了。这段代码展示了如何进行这些操作:
final EList<EObject> contents = getResourceForDiagram(diagram).getContents();
for (final EObject object : contents) {
if (object instanceof StartEvent ) {
// 验证启动事件 Perform some validations for StartEvents
}
// 其它节点类型与验证 Other node types and validations
}别忘了在验证过程中调用addProblemToDiagram()与/或addWarningToDiagram()等等。确保在结束时返回正确的boolean结果,以指示验证成功还是失败。可以由后续调用的ExportMarshaller判断下一步操作。
创建ExportMarshaller扩展
在你的plugin.xml文件中,创建一个org.flowable.designer.eclipse.extension.ExportMarshaller扩展点的扩展。这个扩展点需要扩展AbstractExportMarshaller类。这个基类提供了一些在保存为你自己的格式时有用的方法,但最重要的是提供了将资源保存至工作空间,以及调用验证器的功能。
Designer的示例目录下有一个示例实现。这个示例展示了如何使用基类中的方法完成基本操作,例如访问流程图的InputStream,使用其BpmnModel,以及将资源保存至工作空间。
<?eclipse version="3.6"?>
<plugin>
<extension
point="org.flowable.designer.eclipse.extension.ExportMarshaller">
<ExportMarshaller
class="org.acme.export.AcmeExportMarshaller">
</ExportMarshaller>
</extension>
</plugin>public class AcmeExportMarshaller extends AbstractExportMarshaller {
}需要实现一些方法,例如getMarshallerName()与getFormatName()。这些方法用来为用户显示选项,并在流程对话框中显示信息,因此请确保你返回的描述反映了正在进行的操作。
大部分工作主要在doMarshallDiagram()方法中进行。
如果需要先进行一些验证,可以直接从保存器中调用验证器。从验证器可以获得boolean结果,就可以知道验证是否成功。在大多数情况下,在流程图验证失败时不会想要进行保存,但你也可以选择仍然继续,甚至在验证失败时创建不同的资源。
一旦获取了所有需要的数据,就可以调用saveResource()方法创建保存有数据的文件。在一个保存器中,可以调用saveResource()任意多次;因此一个验证器可以创建多于一个输出文件。
可以使用AbstractDiagramWorker类的saveResource()方法构建输出资源的文件名。可以使用一些有用的变量用于创建文件名,例如_original-filename__my-format-name.xml。这些变量在Javadocs中描述,通过ExportMarshaller接口定义。如果希望自行解析保存位置,也可以在一个字符串(例如一个路径)上使用resolvePlaceholders()。getURIRelativeToDiagram()会为你调用它。
应该使用提供的进度监控将你的进度报告给用户。这个文章描述了如何做。
14. Flowable UI应用
Flowable提供了几个web应用,用于演示及介绍Flowable项目提供的功能:
-
Flowable IDM: 身份管理应用。为所有Flowable UI应用提供单点登录认证功能,并且为拥有IDM管理员权限的用户提供了管理用户、组与权限的功能。
-
Flowable Modeler: 让具有建模权限的用户可以创建流程模型、表单、选择表与应用定义。
-
Flowable Task: 运行时任务应用。提供了启动流程实例、编辑任务表单、完成任务,以及查询流程实例与任务的功能。
-
Flowable Admin: 管理应用。让具有管理员权限的用户可以查询BPMN、DMN、Form及Content引擎,并提供了许多选项用于修改流程实例、任务、作业等。管理应用通过REST API连接至引擎,并与Flowable Task应用及Flowable REST应用一同部署。
所有其他的应用都需要Flowable IDM提供认证。每个应用的WAR文件可以部署在相同的servlet容器(如Apache Tomcat)中,也可以部署在不同的容器中。由于每个应用使用相同的cookie进行认证,因此应用需要运行在相同的域名下。
应用基于Spring Boot 2.0。也就是说WAR文件实际上可以作为独立应用直接运行。参见Spring Boot文档中的可执行的Jar章节。
14.1. 安装
如前所述,全部四个UI应用可以部署在同一个Tomcat服务器里,并且作为入门,这大概也是最简单的方式。也可以选择只安装Modeler应用,但是必须也要部署、运行Flowable IDM应用。在这个安装指导中,我们会介绍如何将所有的四个应用安装至Tomcat服务。
-
下载最新稳定版本的Apache Tomcat。
-
下载最新稳定版本的Flowable 6。
-
将Flowable发行包中,wars文件夹下的flowable-admin.war、flowable-idm.war、flowable-modeler.war与flowable-task.war文件,复制到Tomcat的webapps文件夹下。
-
运行bin/startup.sh(在Mac OS或Linux下),或bin/startup.bat(在Windows下)脚本,启动Tomcat服务器。
-
打开web浏览器,访问http://localhost:8080/flowable-modeler。
这样所有的Flowable UI应用都将运行在H2内存数据库下,并且可以在浏览器中看到如下登录界面:

默认情况下,Flowable IDM应用将创建一个具有访问所有Flowable UI应用所需的权限的admin用户。使用admin/test登录,浏览器会跳转至Flowable Modeler应用:
作为可执行的Spring Boot应用,可以直接以独立应用模式运行UI,而不需要应用服务器。 可以像这样启动一个应用:
java -jar flowable-idm.war通常会需要将默认的H2内存数据库配置,修改为MySQL或Postgres(或其他持久化数据库)。 可以修改每个应用WEB-INF/classes/文件夹下的application.properties。 也可以使用Spring Boot的显式配置。 Github上也提供了配置示例。 要将默认配置修改为MySQL,需要如下修改配置文件:
spring.datasource.driver-class-name=com.mysql.jdbc.Driver
spring.datasource.url=jdbc:mysql://127.0.0.1:3306/flowable?characterEncoding=UTF-8
spring.datasource.username=flowable
spring.datasource.password=flowable这个配置需要MySQL服务器中有一个flowable数据库,UI应用会自动生成必要的数据库表。对于Postgres,需要做如下修改:
spring.datasource.driver-class-name=org.postgresql.Driver
spring.datasource.url=jdbc:postgresql://localhost:5432/flowable
spring.datasource.username=flowable
spring.datasource.password=flowable除了修改配置,还需要确保在classpath中有对应的数据库驱动。类似的,可以对每个web应用分别操作,将驱动JAR文件添加到WEB-INF/lib目录下;也可以直接将JAR文件添加到Tomcat的lib目录下。MySQL与Postgres的数据库驱动可以从这里下载:
-
Postgres: https://jdbc.postgresql.org/
以独立应用方式运行应用时,可以使用 loader.path 参数添加数据库驱动。
java -Dloader.path=/location/to/your/driverfolder -jar flowable-idm.war参阅Spring Boot文档PropertiesLauncher 功能介绍了解更多信息。
14.2. 配置Flowable UI应用
作为Spring Boot应用,Flowable UI应用可以使用Spring Boot提供的全部参数。 参阅Spring Boot文档的显式配置章节,了解如何进行自定义配置。
提示:也可以使用YAML格式的配置文件。
| 参数名 | 原参数 | 默认值 | 描述 |
|---|---|---|---|
flowable.common.app.idm-url |
idm.app.url |
- |
IDM应用的URL,用于获取用户信息与令牌信息的REST GET调用。也用做UI应用重定向的登录页。 |
flowable.common.app.idm-redirect-url |
idm.app.redirect.url |
- |
IDM应用的重定向URL,在未设置cookie或cookie失效时,重定向至该页面进行登录。 |
flowable.common.app.redirect-on-auth-success |
app.redirect.url.on.authsuccess |
- |
登录成功后需要重定向的页面URL。 |
flowable.common.app.role-prefix |
- |
ROLE_ |
Spring Security需要的默认角色前缀。 |
flowable.common.app.tenant-id |
- |
- |
DefaultTenantProvider所用的静态租户id。modeler用来判断需要将模型存储及发布在哪个租户id下。 当未设置该值、值为空,或只包含空白时:如果能够获取用户的租户id,则会使用该租户id;否则不使用租户id。 |
flowable.common.app.cache-login-tokens.max-age |
cache.login-tokens.max.age |
30 |
login token的缓存时间,以秒记。 |
flowable.common.app.cache-login-tokens.max-size |
cache.login-tokens.max.size |
2048 |
login token缓存的最大尺寸。 |
flowable.common.app.cache-login-users.max-age |
cache.login-users.max.age |
30 |
login user的缓存时间,以秒记。 |
flowable.common.app.cache-login-users.max-size |
cache.login-users.max.size |
2048 |
login user缓存的最大尺寸。 |
flowable.common.app.cache-users.max-age |
cache.users.max.age |
30 |
user的缓存时间,以秒记。 |
flowable.common.app.cache-users.max-size |
cache.users.max.size |
2048 |
user缓存的最大尺寸。 |
flowable.common.app.idm-admin.password |
idm.admin.password |
test |
对IDM REST服务进行REST调用(使用基础认证)的密码。 |
flowable.common.app.idm-admin.user |
idm.admin.user |
admin |
对IDM REST服务进行REST调用(使用基础认证)的用户名。 |
flowable.rest.app.authentication-mode |
rest.authentication.mode |
verify-privilege |
配置REST API验证用户身份的方式: any-user :用户存在且密码匹配。任何用户都可以进行调用(6.3.0之前的方式) verify-privilege :用户存在且密码匹配,并且用户拥有rest-api权限 |
一些旧参数改由Flowable Spring Boot starter(或Spring Boot)进行管理
| 参数名 | 原参数 | 默认值 | 描述 |
|---|---|---|---|
flowable.async-executor-activate |
engine.process.asyncexecutor.activate |
true |
是否启用异步执行器。 |
flowable.database-schema-update |
engine.process.schema.update |
true |
是否执行数据库表结构升级。 |
flowable.history-level |
engine.process.history.level |
- |
历史级别。 |
flowable.process.servlet.name |
flowable.rest-api-servlet-name |
Flowable BPMN Rest API |
流程servlet的名字。 |
flowable.process.servlet.path |
flowable.rest-api-mapping |
/process-api |
流程REST servlet的上下文路径。 |
flowable.content.storage.create-root |
contentstorage.fs.create-root |
true |
如果root目录不存在,是否需要创建它? |
flowable.content.storage.root-folder |
contentstorage.fs.root-folder |
- |
存储内容文件(任务附件、表单上传文件等)的root目录。 |
flowable.idm.enabled |
flowable.db-identity-used |
true |
是否启动IDM引擎。 |
flowable.idm.password-encoder |
security.passwordencoder |
- |
密码加密方式。 |
flowable.idm.ldap.base-dn |
ldap.basedn |
- |
查询用户及组的基础DN(标识名 distinguished name)。如果用户及组使用不同的基础DN,请改用user-base-dn及group-base-dn。 |
flowable.idm.ldap.enabled |
ldap.enabled |
false |
是否启用LDAP IDM服务。 |
flowable.idm.ldap.password |
ldap.password |
- |
连接LDAP系统所用的密码。 |
flowable.idm.ldap.port |
ldap.port |
-1 |
LDAP系统的端口号。 |
flowable.idm.ldap.server |
ldap.server |
- |
LDAP系统所在的服务器地址。例如ldap://localhost。 |
flowable.idm.ldap.user |
ldap.user |
- |
连接LDAP系统所用的用户ID。 |
flowable.idm.ldap.attribute.email |
ldap.attribute.email |
- |
代表用户邮件地址的LDAP属性名。用于查询并将LDAP对象映射至Flowable org.flowable.idm.api.User对象。 |
flowable.idm.ldap.attribute.first-name |
ldap.attribute.firstname |
- |
代表用户名字的LDAP属性名。用于查询并将LDAP对象映射至Flowable org.flowable.idm.api.User对象。 |
flowable.idm.ldap.attribute.group-id |
ldap.attribute.groupid |
- |
代表用户组ID的LDAP属性名。用于查询并将LDAP对象映射至Flowable org.flowable.idm.api.Group对象。 |
flowable.idm.ldap.attribute.group-name |
ldap.attribute.groupname |
- |
代表用户组名称的LDAP属性名。用于查询并将LDAP对象映射至Flowable org.flowable.idm.api.Group对象。 |
flowable.idm.ldap.attribute.last-name |
ldap.attribute.lastname |
- |
代表用户姓的LDAP属性名。用于查询并将LDAP对象映射至Flowable org.flowable.idm.api.User对象。 |
flowable.idm.ldap.attribute.user-id |
ldap.attribute.userid |
- |
代表用户ID的LDAP属性名。用于查询并将LDAP对象映射至Flowable org.flowable.idm.api.User对象。仅在使用Flowable API查询org.flowable.idm.api.User对象时需要设置。 |
flowable.idm.ldap.cache.group-size |
ldap.cache.groupsize |
-1 |
设置org.flowable.ldap.LDAPGroupCache缓存的尺寸。 这是用户所在组的LRU缓存。避免每次需要查询用户所在组时都访问LDAP系统。 若值小于0,则不会启用缓存。默认值为-1,所以不会进行缓存。 请注意组缓存在org.flowable.ldap.LDAPIdentityServiceImpl中初始化。 因此,自行实现org.flowable.ldap.LDAPIdentityServiceImpl时,请不要忘记添加组缓存功能。 |
flowable.idm.ldap.query.all-groups |
ldap.query.groupall |
- |
查询所有组所用的语句。 |
flowable.idm.ldap.query.all-users |
ldap.query.userall |
- |
查询所有用户所用的语句。 |
flowable.idm.ldap.query.groups-for-user |
ldap.query.groupsforuser |
- |
查询给定用户所在组所用的语句。
比如: |
flowable.idm.ldap.query.user-by-full-name-like |
ldap.query.userbyname |
- |
通过全名查询用户所用的语句。
比如: |
flowable.idm.ldap.query.user-by-id |
ldap.query.userbyid |
- |
通过ID查询用户所用的语句。
比如: |
flowable.mail.server.host |
email.host |
localhost |
邮件服务器地址。 |
flowable.mail.server.password |
email.password |
- |
邮件服务器的密码。 |
flowable.mail.server.port |
email.port |
1025 |
邮件服务器的端口号。 |
flowable.mail.server.ssl-port |
email.ssl-port |
1465 |
SSL邮件服务器的端口号。 |
flowable.mail.server.use-ssl |
email.use-ssl |
false |
是否需要为SMTP协议启用SSL/TLS加密(即SMTPS/POPS)。 |
flowable.mail.server.use-tls |
email.use-tls |
false |
是否启用STARTTLS加密。 |
flowable.mail.server.username |
email.username |
- |
邮件服务器的用户名。 为空则不进行认证。 |
flowable.process.definition-cache-limit |
flowable.process-definitions.cache.max |
-1 |
流程定义缓存的最大数量。 默认值为-1,即缓存所有流程定义。 |
| 参数名 | 原参数 | 默认值 | 描述 |
|---|---|---|---|
spring.datasource.driver-class-name |
datasource.driver |
- |
JDBC驱动的全限定名。默认通过URL自动检测。 |
spring.datasource.jndi-name |
datasource.jndi.name |
- |
数据源的JNDI。若设置JNDI,则忽略Class、url、username及password设置。 |
spring.datasource.password |
datasource.password |
- |
数据库的登录密码。 |
spring.datasource.url |
datasource.url |
- |
数据库的JDBC URL。 |
spring.datasource.username |
datasource.username |
- |
数据库的登录用户名 |
spring.datasource.hikari.connection-test-query |
datasource.preferred-test-query |
- |
用于验证连接的SQL语句。 |
spring.datasource.hikari.connection-timeout |
datasource.connection.timeout |
- |
客户端等待获取连接的最大时间,以毫秒计。如果获取连接超时,会抛出SQLException。 |
spring.datasource.hikari.idle-timeout |
datasource.connection.idletimeout |
- |
连接池中连接的最大空闲时间,以毫秒计。 实际销毁连接前,会多等平均+15秒,最大+30秒的额外时间。 不会在空闲超时前销毁连接。 值为0代表连接池不会销毁空闲连接。 |
spring.datasource.hikari.max-lifetime |
datasource.connection.maxlifetime |
- |
连接池中连接的最大存活时间。如果连接超过存活时间,即使该连接刚被使用过,也会被连接池销毁。不会销毁正在使用的连接,只会销毁空闲的连接。 |
spring.datasource.hikari.maximum-pool-size |
datasource.connection.maxpoolsize |
- |
连接池的最大容量,包括空闲及使用中的连接。这个配置决定了到数据库的实际连接数。如果连接池尺寸到达上限,且没有可用的空闲连接,则getConnection()会等待connectionTimeout设置的时间,然后超时。 |
spring.datasource.hikari.minimum-idle |
datasource.connection.minidle |
- |
HikariCP连接池保留的最小空闲连接数量。如果空闲连接数量少于设置,HikariCP会尽最大努力尽快有效地恢复。 |
spring.servlet.multipart.max-file-size |
file.upload.max.size |
10MB |
文件的最大尺寸,可以使用“MB”或“KB”后缀。 |
| 旧参数 | 描述 |
|---|---|
datasource.jndi.resource-ref |
Spring Boot不支持配置JNDI resourceRef,而是按名称直接引用。 |
email.use-credentials |
如果邮件服务器不使用认证,直接将用户名及密码置空即可。 |
14.3. Flowable IDM应用
Flowable IDM应用,用于其他三个Flowable web应用的认证与授权。因此如果你想要运行Modeler,Task或者Admin应用,就需要运行IDM应用。Flowable IDM应用是一个简单的身份管理应用,目标是为Flowable web应用提供单点登录能力,并提供定义用户、组与权限的能力。
IDM应用在启动时启动IDM引擎,并按照配置参数中定义的数据源创建IDM引擎所需的身份表。
当Flowable IDM应用部署及启动时,将检查是否在ACT_ID_USER表中有用户。如果没有,将在表中使用 flowable.common.app.idm-admin.user 参数创建默认管理员用户。
同时也会为新创建的管理员用户添加Flowable项目中的所有权限:
-
access-idm: 提供管理用户、组与权限的权限
-
access-admin: 使用户可以登录Flowable Admin应用,管理Flowable引擎,以及访问所有应用的Actuator Endpoint。
-
access-modeler: 提供访问Flowable Modeler应用的权限
-
access-task: 提供访问Flowable Task应用的权限
-
access-rest-api: 提供调用REST API的权限。否则调用会返回403(无权限)HTTP状态码。请注意需要将flowable.rest.app.authentication-mode设置为verify-privilege,即默认设置。
第一次使用admin/test登录http://localhost:8080/flowable-idm时,会显示如下用户总览界面:
在这个界面中,可以添加、删除与更新用户。组页签用于创建、删除与更新组。在组详情界面中,可以向组添加与删除用户。权限界面为用户与组添加及删除权限:
暂时还不能定义新的权限。但是可以为用户与组添加及删除已有的四个权限。
下表是IDM UI应用的专用参数。
| 参数名 | 原参数 | 默认值 | 描述 |
|---|---|---|---|
flowable.idm.app.bootstrap |
idm.bootstrap.enabled |
true |
是否为IDM应用启用bootstrap。 |
flowable.idm.app.rest-enabled |
rest.idm-app.enabled |
true |
启用REST API(指的是使用基础身份认证的API,而不是UI使用的REST API)。 |
flowable.idm.app.admin.email |
admin.email |
- |
admin用户的邮箱。 |
flowable.idm.app.admin.first-name |
admin.firstname |
- |
admin用户的名字。 |
flowable.idm.app.admin.last-name |
admin.lastname |
- |
admin用户的姓。 |
flowable.idm.app.admin.password |
admin.password |
- |
admin用户的密码。 |
flowable.idm.app.admin.user-id |
admin.userid |
- |
admin用户的ID。 |
flowable.idm.app.security.remember-me-key |
security.rememberme.key |
testKey |
Spring Security对密码加密时所用的哈希值。请一定要修改这个参数。 |
flowable.idm.app.security.user-validity-period |
cache.users.recheck.period |
30000 |
对于可缓存的CustomUserDetailsService服务,缓存用户的时间。 |
flowable.idm.app.security.cookie.domain |
security.cookie.domain |
- |
cookie的域。 |
flowable.idm.app.security.cookie.max-age |
security.cookie.max-age |
2678400 |
cookie的存活时间,以秒记。默认为31天。 |
flowable.idm.app.security.cookie.refresh-age |
security.cookie.refresh-age |
86400 |
cookie的刷新周期,以秒记。默认为1天。 |
除了使用默认的身份表之外,IDM应用也可以使用LDAP服务。 在application.properties文件中(或使用其他配置方式)加入下列配置:
#
# LDAP
#
flowable.idm.ldap.enabled=true
flowable.idm.ldap.server=ldap://localhost
flowable.idm.ldap.port=10389
flowable.idm.ldap.user=uid=admin, ou=system
flowable.idm.ldap.password=secret
flowable.idm.ldap.base-dn=o=flowable
flowable.idm.ldap.query.user-by-id=(&(objectClass=inetOrgPerson)(uid={0}))
flowable.idm.ldap.query.user-by-full-name-like=(&(objectClass=inetOrgPerson)(|({0}=*{1}*)({2}=*{3}*)))
flowable.idm.ldap.query.all-users=(objectClass=inetOrgPerson)
flowable.idm.ldap.query.groups-for-user=(&(objectClass=groupOfUniqueNames)(uniqueMember={0}))
flowable.idm.ldap.query.all-groups=(objectClass=groupOfUniqueNames)
flowable.idm.ldap.attribute.user-id=uid
flowable.idm.ldap.attribute.first-name=cn
flowable.idm.ldap.attribute.last-name=sn
flowable.idm.ldap.attribute.group-id=cn
flowable.idm.ldap.attribute.group-name=cn
flowable.idm.ldap.cache.group-size=10000
flowable.idm.ldap.cache.group-expiration=180000flowable.idm.ldap.enabled 参数设置为true时,需要同时填入其他的LDAP参数。
在这个示例配置中使用Apache Directory的服务器配置 + LDAP查询。
其他LDAP服务器如Active Directory使用不同的配置值。
配置LDAP后将通过LDAP服务器进行认证及从组中获取用户,但仍然从Flowable身份表中获取权限。因此需要确保每一个LDAP用户都在IDM应用中定义了正确的权限。
如果IDM应用配置为使用LDAP,则启动时将检查Flowable身份表中是否存在权限。
(第一次启动时)如果没有权限,则会创建4个默认权限,并为ID为(application.properties或其他配置环境中的) flowable.common.app.idm-admin.user 参数的用户赋予这4个权限。
因此请确保 flowable.common.app.idm-admin.user 参数设置为有效的LDAP用户,否则将没有人能够登录任何Flowable UI应用。
14.4. Flowable Modeler应用
Flowable Modeler用于建模BPMN流程、DMN选择表、表单定义,以及创建应用定义。BPMN Modeler使用与Flowable 5相同的Oryx与Angular架构,只是迁移为独立的Modeler应用中。在使用Flowable Modeler应用时,请确保Flowable IDM应用已经部署并正常运行(用于认证与授权)。
使用自己的账户(或者默认的admin/test用户)登录Modeler应用后(http://localhost:8080/flowable-modeler),可以看到流程总览页面。可以点击Create Process(创建流程)按钮或Import Process(导入流程)按钮,创建新的BPMN流程模型。
在创建流程模型(以及其他模型)时,需要谨慎选择模型key。模型key是模型仓库中该模型的唯一标识。如果使用了已经存在的模型key,则会显示错误,模型也不会保存。
在弹出窗口中创建模型后,会显示BPMN模型画布。这个BPMN编辑器与Flowable 5中(作为Explorer的组件)的BPMN编辑器十分相像。在设计流程模型时,可以使用Flowable引擎支持的所有BPMN元素。
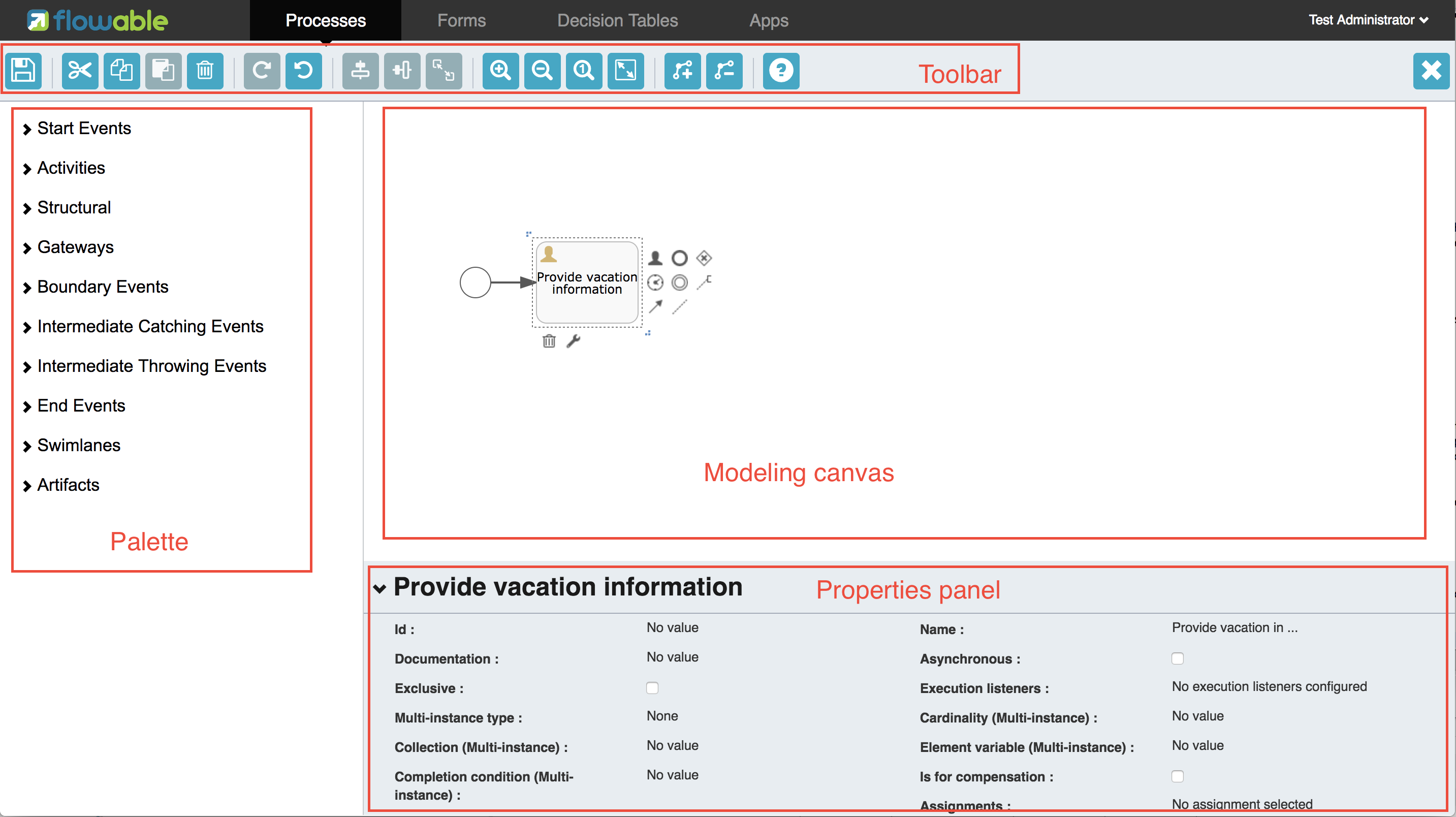
BPMN编辑器分为4个部分:
-
画板(Palette): 用于设计流程模型的所有BPMN元素
-
工具条(Toolbar): 修改模型画布的操作。如缩放、布局、保存等
-
模型画布(Model canvas): 在模型画布上拖放BPMN元素,设计流程模型
-
参数面板(Properties panel): 如果没有选择元素,则显示主流程模型的参数;否则显示所选中BPMN元素的参数
用户任务元素的参数面板中有一个Referenced form(引用表单)参数。选择这个参数会弹出窗口,使你可以在仓库中选择一个表单定义,或者创建一个新的表单。如果选择创建一个新的表单,会显示一个类似于流程模型创建对话框的弹窗。填入表单名及表单模型key之后,就会打开表单编辑器。
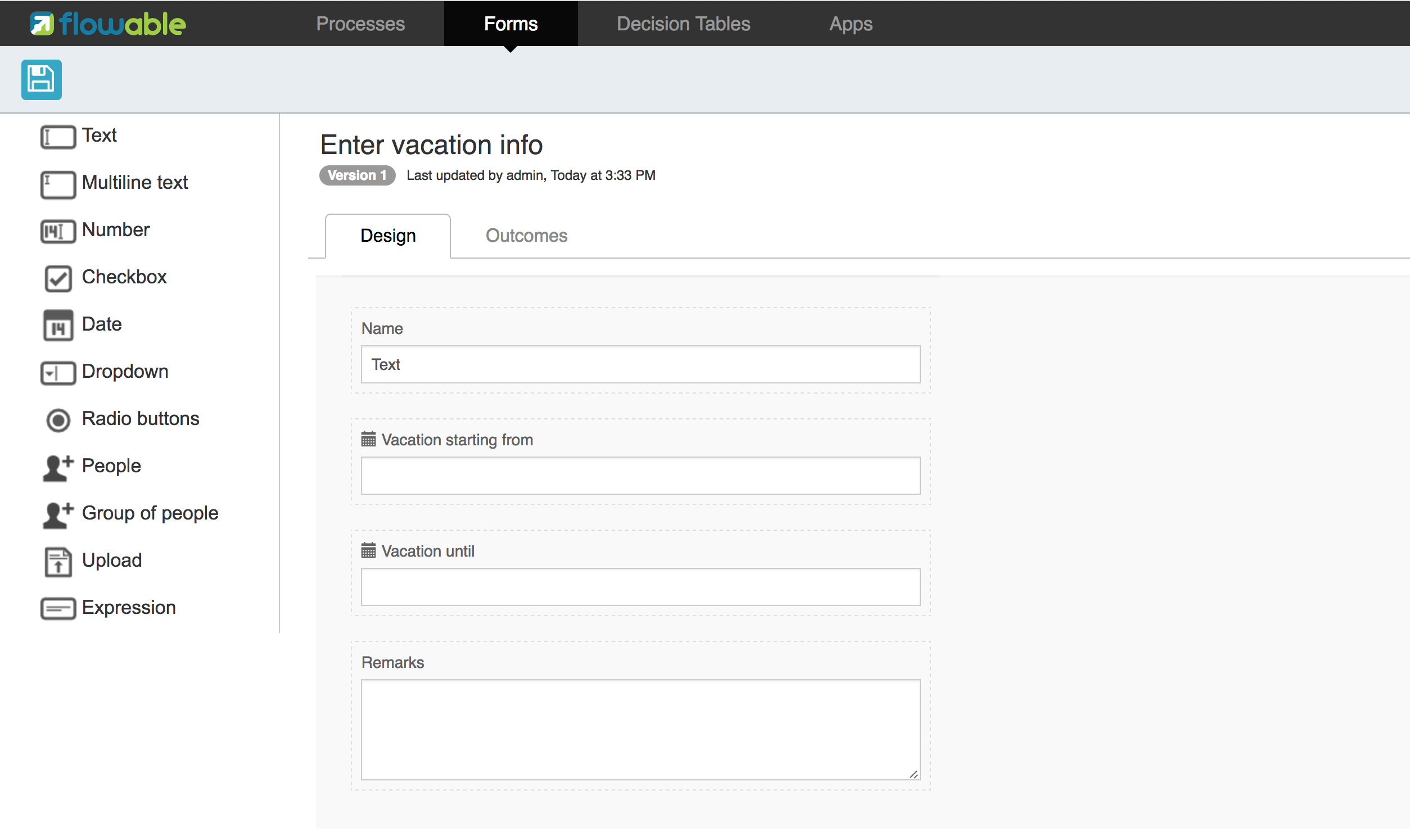
可以从表单画板中将表单字段拖入表单画布。在这个例子中,在表单画布上添加了一个Name(姓名)文本框,两个日期框,以及一个Remarks(说明)多行文本框。在编辑表单字段时,可以配置Label(标签)、Id、Required(是否必填),以及Placeholder(占位符)。

id是一个重要的参数。流程使用这个id为表单字段创建流程变量。填写label参数时,会自动为id参数赋值。如果需要的话,也可以选中Override Id?(覆盖Id)复选框,并填入所需的id。
保存表单模型并关闭表单编辑器之后,(如果表单编辑器是从BPMN编辑器打开的话)会自动跳转回流程模型。再次选择用户任务元素,并点击Referenced form参数,就可以看到已经将新创建的表单定义附加至用户任务。点击Modeler应用头部的Form(表单)页签,也可以看到模型仓库中保存的所有表单定义。
可以打开表单定义的详情界面,查看各表单定义。在详情页面中,可以修改表单名、key及描述,也可以查阅表单模型的修改历史。也可以复制表单定义,创建一个具有相同表单字段的新的表单定义。
接下来,再次打开BPMN编辑器中的vacation request(请假)流程模型,向流程模型中添加一个脚本任务,用于计算假期开始到结束之间的日数。点击Script form(脚本表单)参数,填入groovy,这样Flowable引擎就会使用Groovy脚本引擎。然后点击Script(脚本)参数,并填入用于计算日数的脚本。
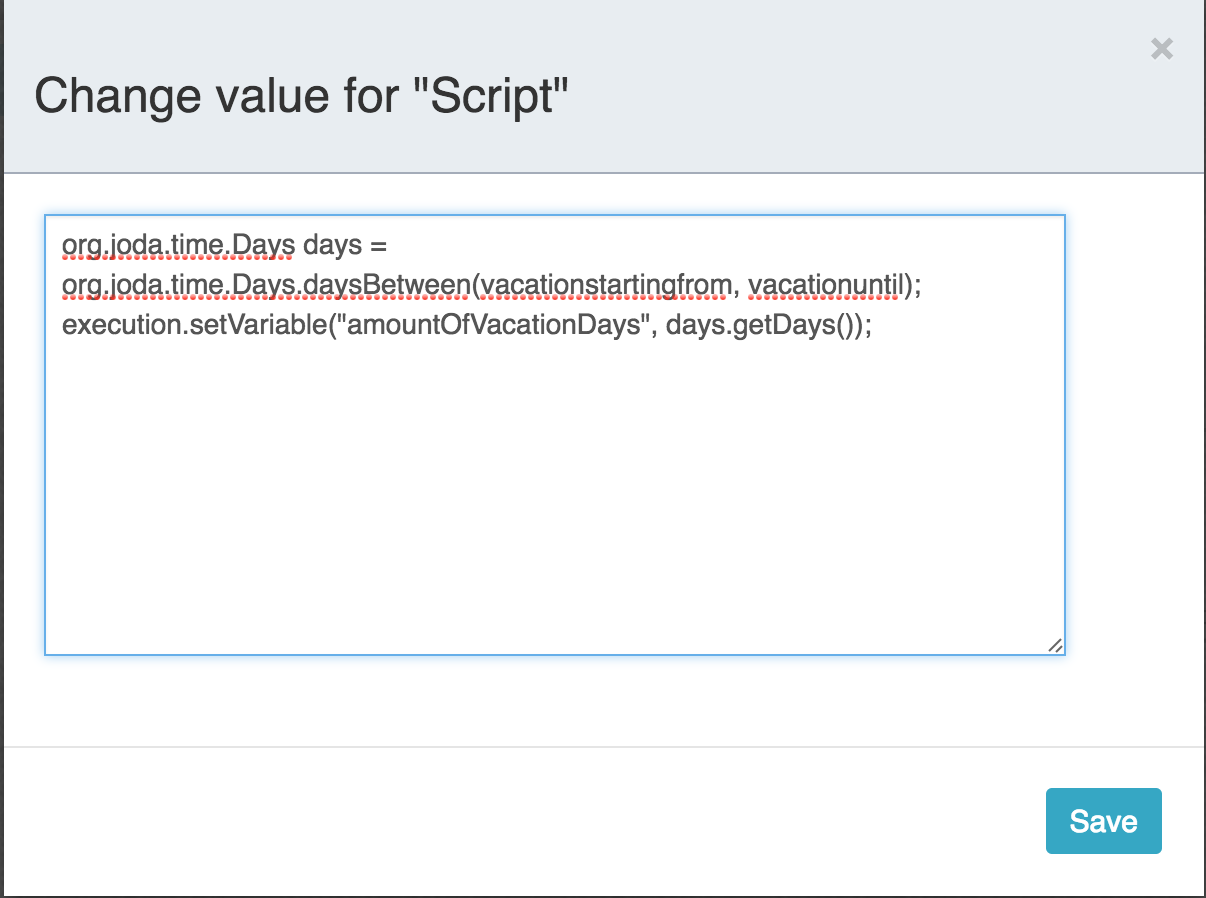
这样就定义了amountOfVacationDays流程变量,接下来可以在流程模型中添加一个选择任务(Decision task)。选择任务用于在Flowable DMN引擎中执行DMN选择表。使用Decision table reference(引用选择表)参数,创建一个新的选择表模型,并打开DMN编辑器。
DMN编辑器提供了一个列表式的编辑器。包括输入列——使用流程中的流程变量定义输入条件;以及输出列——定义输出变量。在这个简单的例子里,只使用一个输入列,并使用amountOfVacationDays变量。如果天数少于10,managerApprovalNeeded变量返回值false。否则返回true。可以定义多个输入列,每条规则也可以有多个输入条件。也可以将一个输入列置空,代表其永远为true。也可以定义一个或多个输出变量。
DMN选择表定义的另一个重要部分是命中策略(Hit Policy)。目前,Flowable支持第一(First)与任意(Any)命中策略。对于第一命中策略,DMN会返回第一条计算为true的规则定义的输出变量,并停止计算。对于任意命中策略,会计算所有的规则,并输出计算为true的最后一条规则定义的输出变量。
保存并关闭DMN编辑器后,Modeler应用跳转回BPMN编辑器,并将新创建的DMN选择表附加至选择任务。在BPMN XML中生成如下的选择任务:
<serviceTask id="decisionTask" name="Is manager approval needed?" flowable:type="dmn">
<extensionElements>
<flowable:field name="decisionTableReferenceKey">
<flowable:string><![CDATA[managerApprovalNeeded]]></flowable:string>
</flowable:field>
</extensionElements>
</serviceTask>这样就可以创建带有一个条件顺序流的排他网关,以使用DMN引擎的计算结果,即managerApprovalNeeded变量。
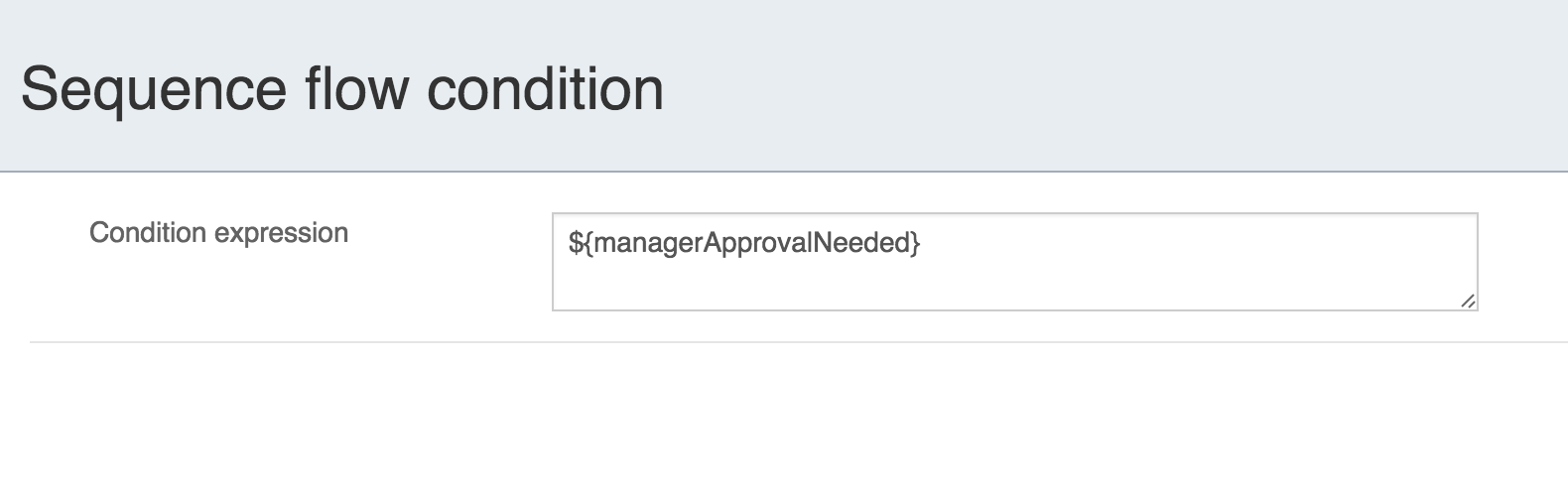
完整的BPMN流程模型为:
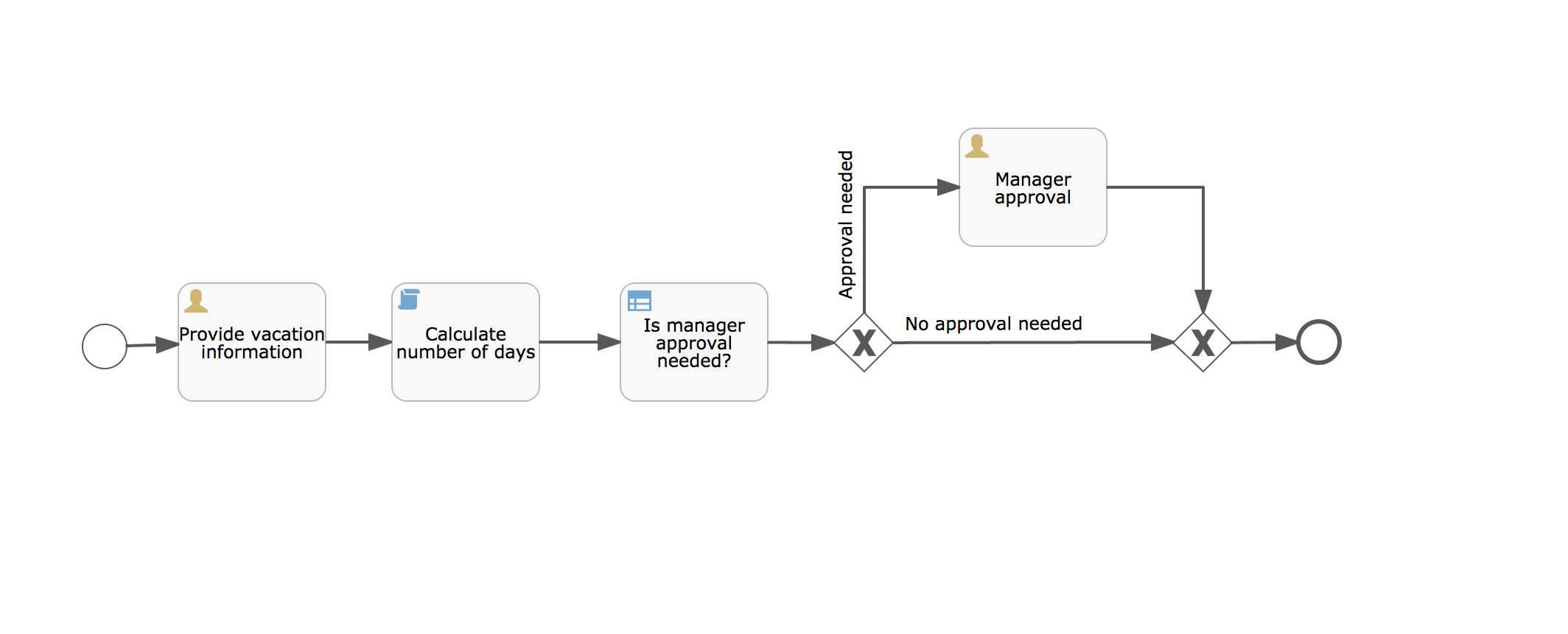
完成流程模型之后,就可以创建应用定义(app definition),将一个或多个流程模型及关联的模型(如选择表和表单定义)打包为一个整体。应用定义可以导出为BAR文件(zip格式),并可以在Flowable引擎中部署。创建完成请假应用定义后,应用编辑器将如下显示。

还可以在应用编辑器中选择图标和主题色,调整Flowable Task应用在看板(dashboard)中的显示效果。重点步骤是添加请假流程模型,并通过选择流程模型,自动引入对应的表单定义和DMN选择表。
点击预览图选中流程模型。选择一个或多个模型之后,就可以关闭弹窗,保存并关闭应用定义。在详情页面查看新创建的请假应用定义,如下所示:
在这个页面中,可以通过两种不同格式下载应用定义。第一个下载按钮(带有下箭头)下载每个模型的JSON格式模型文件,用于在不同的Flowable Modeler应用之间共享应用定义。第二个下载按钮(带有指向右上的箭头)下载应用定义模型的BAR文件,用于在Flowable引擎中部署。在BAR文件中,只包含了可以部署的工件,如BPMN 2.0 XML文件和DMN XML文件,而不会包含JSON模型文件。这是因为在Flowable引擎部署时,BAR文件中的所有文件都会保存在数据库中。因此需要避免将不需要部署的文件放在BAR中。
在应用定义详情页面,也可以直接向Flowable引擎发布(Publish)应用定义。Flowable Modeler使用application.properties文件中,flowable.modeler.app.deployment-api-url参数设置的URL部署应用定义。默认部署URL配置为Flowable Task应用。但也可以修改,比如改为使用Flowable REST应用。确保Flowable Task应用正在运行,点击Publish按钮。这样应用定义就会做为一个BAR文件部署到Flowable Task应用。
下表是Modeler UI应用的专用参数。
| 参数名 | 原参数 | 默认值 | 描述 |
|---|---|---|---|
flowable.modeler.app.data-source-prefix |
datasource.prefix |
- |
数据库表名的前缀。 |
flowable.modeler.app.deployment-api-url |
deployment.api.url |
Flowable引擎REST服务的根URL,Flowable Modeler用来向引擎部署应用定义BAR文件。 Flowable Task应用的默认URL为 http://localhost:8080/flowable-task/process-api |
|
flowable.modeler.app.rest-enabled |
rest.modeler-app.enabled |
true |
启用REST API(指的是使用基础身份认证的API,而不是UI使用的REST API)。 |
14.5. Flowable Task应用
Flowable Task应用是Flowable项目的运行时应用,默认包括Flowable BPMN、DMN、Form以及Content引擎。可以使用Flowable Task应用,启动新流程实例、完成任务、渲染任务表单等。在之前的章节中,已经通过Flowable Task应用REST API在Flowable引擎中部署了请假应用定义。在Flowable数据库中可以看到BPMN引擎的ACT_RE_DEPLOYMENT表中已经创建了新的部署实体。DMN引擎的ACT_DMN_DEPLOYMENT,和Form引擎的ACT_FO_FORM_DEPLOYMENT表中也创建了新的实体。
在http://localhost:8080/flowable-task的看板中,可以看到请假应用及默认的Task应用,和其他已经在Flowable引擎中部署的应用。
点击请假应用,会显示当前登录用户的任务列表(现在很可能是空的)。
点击打开Processes(流程)页签后,可以点击Start a process(启动流程)按钮,启动一个新的流程实例。会列表显示当前应用定义上下文中所有可用的流程定义。选择请假流程定义后,可以点击Start process按钮,启动一个新的请假流程实例。
Flowable Task应用将自动跳转至流程实例详情页面。可以看到已经激活了Provide vacation information(提供请假信息)任务。可以添加备注,或者使用Show diagram(显示流程图)按钮,图形化显示流程实例状态。
转至任务列表,也可以看到这里也列出了Provide vacation information任务。这个界面会显示任务详情及渲染的请假信息表单。也可以点击Show details(显示详情)按钮,转至详情页面。在详情页面中,可以添加备注,引入用户,为任务添加附件,或者修改任务的到期时间和办理人。
开始填写表单并完成任务。首先,选择间隔超过10天的开始日期和结束日期。这样就可以生成Manager approval(经理审批)任务。请假信息表单填写完毕后,点击Complete(完成)按钮,Flowable Task应用就会跳转至Manager approval任务界面。直接完成这个任务(不需要填写任务表单),流程实例就结束了。
返回Processes页签,点击Showing running processes(显示运行中的流程)选项,可以选择show completed process instances(显示已完成的流程实例)。这样就会显示已完成的流程实例列表。点击刚才完成的请假流程,可以看到两个完成的任务。
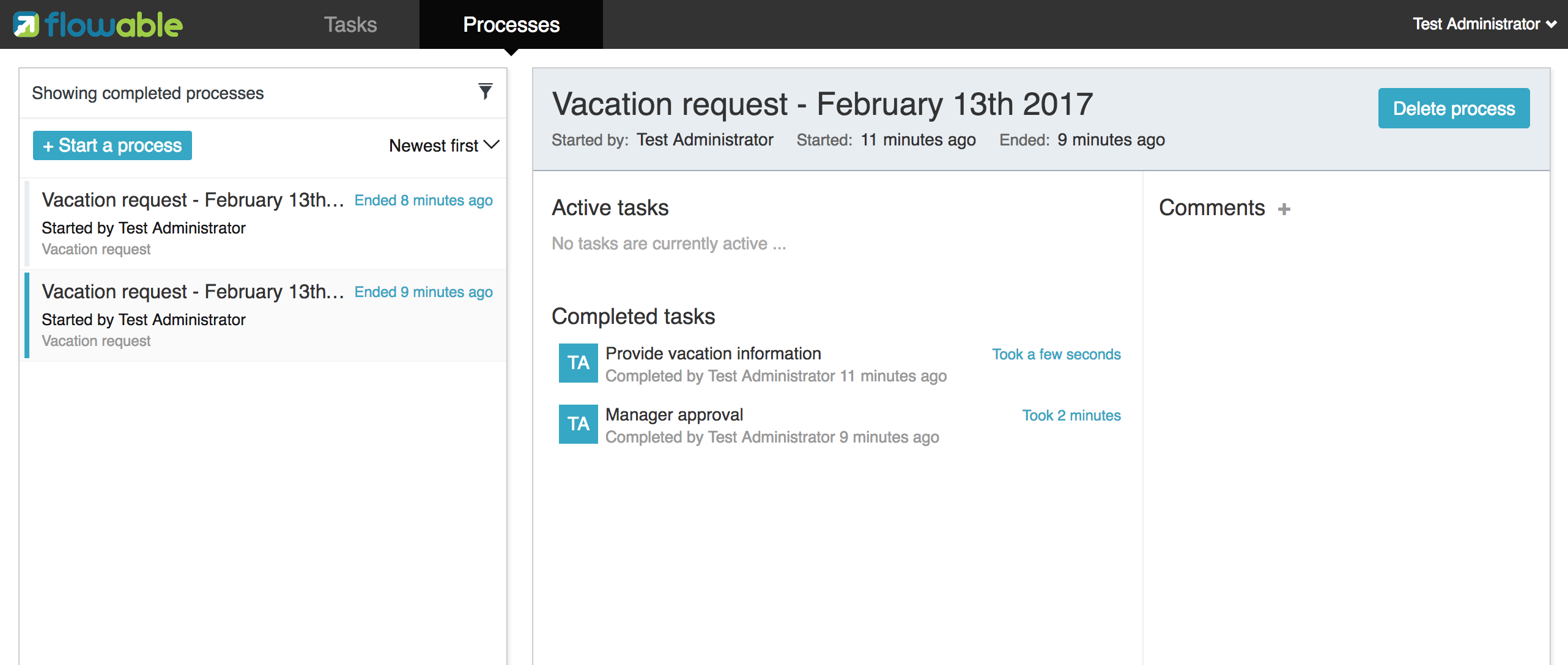
每个任务的完成表单(complete form)都存储在Flowable Form引擎的ACT_FO_FORM_INSTANCE表中。因此,在查看完成的任务时,就可以看到每一个完成表单的数据。
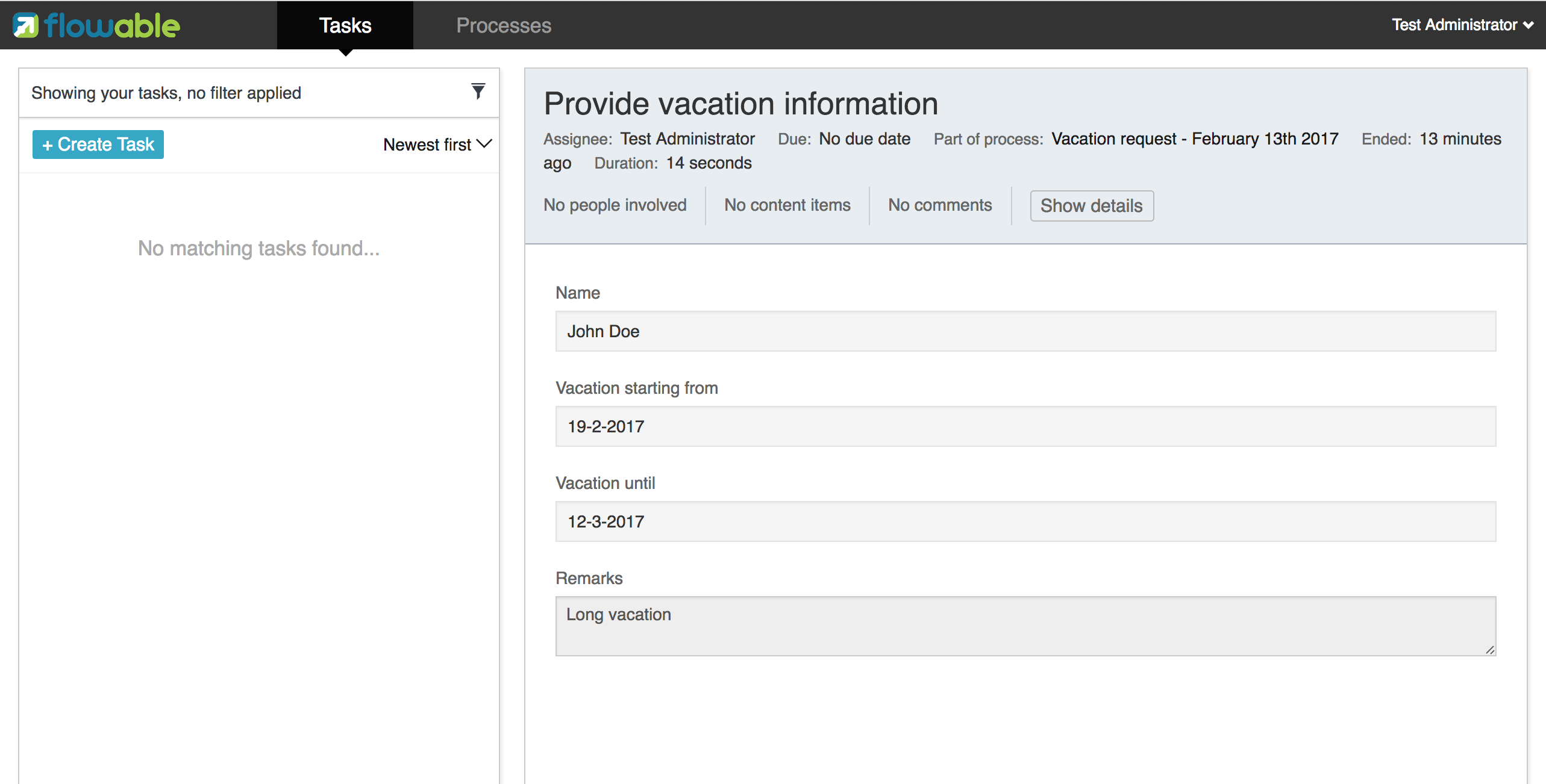
请确保选择回showing running processes,否则就不能看到新启动的流程实例。也可以在任务列表界面进行过滤,选择查找任务名、任务状态,特定流程定义的任务,以及指定的办理人。
默认情况下,办理人过滤设置为Tasks where I am involved(我参与的任务)。这样不会显示用户作为候选人而没有指定为办理人的任务。要显示候选任务,可以选择Tasks where I am one of the candidates(我参与候选的任务)。
下表是Task UI应用的专用参数。
| 参数名 | 原参数 | 默认值 | 描述 |
|---|---|---|---|
flowable.experimental.debugger.enabled |
debugger.enabled |
false |
是否启用流程调试器。 |
flowable.task.app.rest-enabled |
rest.task-app.enabled |
true |
启用REST API(指的是使用基础身份认证的API,而不是UI使用的REST API)。 |
14.6. Flowable Admin应用
Flowable Admin应用是Flowable项目提供的第四个UI应用。用于查询BPMN、DMN及Form引擎中的部署,也可以显示流程实例的当前状态,包括当前的任务和流程变量。也提供了将任务指派给不同的办理人,以及完成任务的操作。Flowable Admin应用使用REST API与Flowable引擎通信。默认情况下,配置为连接至Flowable Task REST API,但是也可以很容易的修改为连接至Flowable REST应用的REST API。访问http://localhost:8080/flowable-admin时会显示配置界面(也可以直接点击Flowable logo右上方的箭头)。
每一个引擎都可以配置REST端点的基本认证。每个引擎需要单独配置,因为有可能会分开部署引擎,比如将DMN引擎与BPMN引擎部署在不同的服务器上。
如果配置正确,就可以选择Process Engine(流程引擎)来管理Flowable BPMN引擎。默认情况下,会显示Flowable BPMN引擎的部署情况。
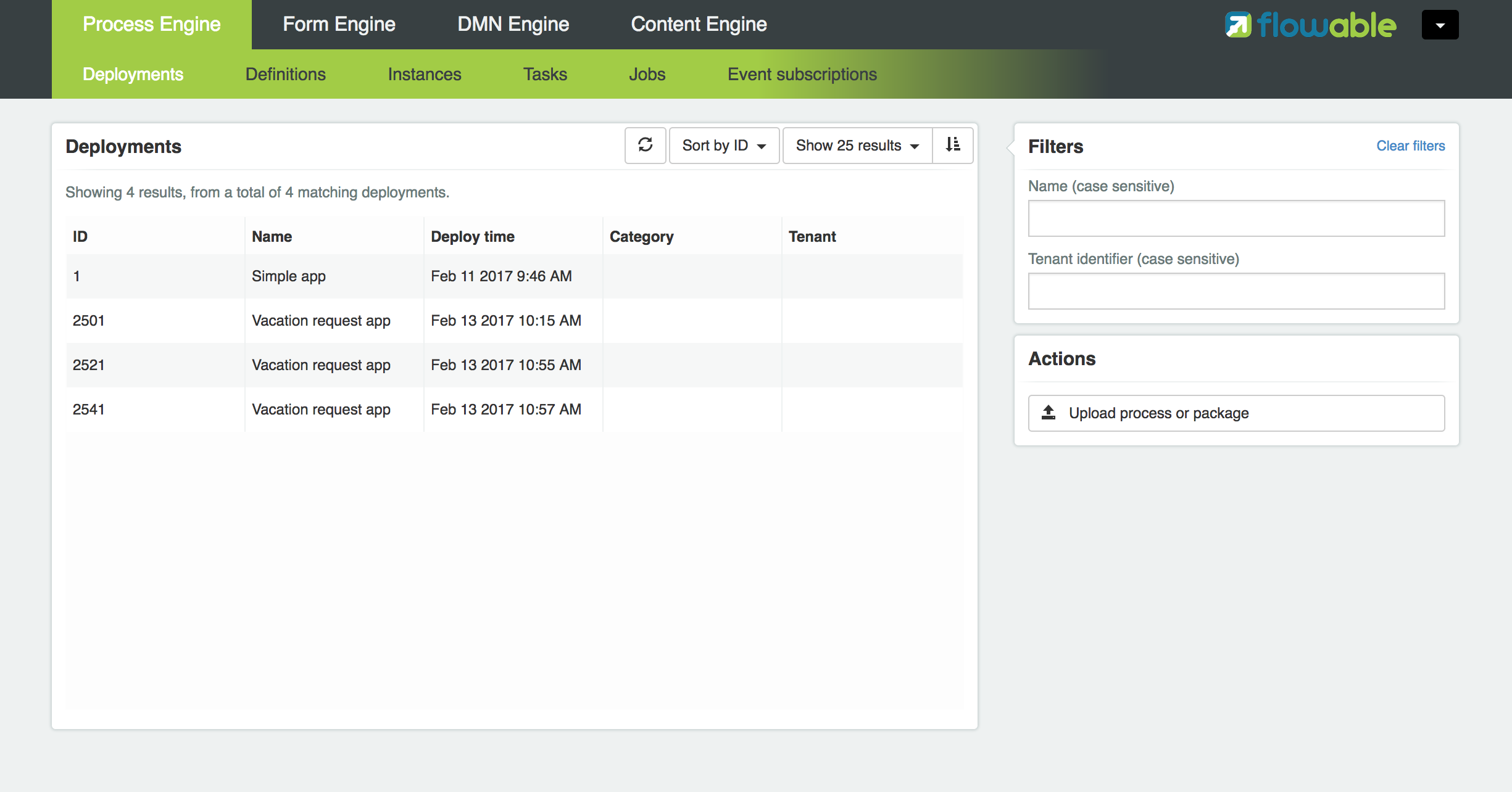
可以使用名字及租户id过滤查找部署。也可以为Flowable引擎部署新的BPMN XML或BAR文件。点击其中一个部署,会显示部署详情界面。
这里会显示部署的详细信息,以及部署中包含的流程定义。也可以删除部署。如果希望删除已部署的应用定义,也可以在Flowable Task应用看板中删除应用定义。点击其中一个流程定义,会显示流程定义详情页面。
在流程定义详情页面中,首先显示的是流程实例,以及流程定义中使用的选择表定义和表单定义。请假流程定义有一个关联的选择表,以及一个关联的表单定义。点击选择表定义,就会从Flowable Admin应用跳转至DMN引擎。可以点击Parent Deployment ID(父部署ID)链接,返回流程引擎。
除了部署与定义之外,还可以查询流程引擎中的流程实例、任务、作业,以及事件订阅情况。界面与前面介绍的类似。
下表是Admin UI应用的专用参数。
| 参数名 | 原参数 | 默认值 | 描述 |
|---|---|---|---|
flowable.admin.app.data-source-prefix |
datasource.prefix |
数据库表名的前缀。 |
|
flowable.admin.app.security.encryption.credentials-i-v-spec |
security.encryption.credentials-i-v-spec |
- |
创建IvParameterSpec对象所用的bytes。 |
flowable.admin.app.security.encryption.credentials-secret-spec |
security.encryption.credentials-secret-spec |
- |
创建SecretKeySpec对象所用的bytes。 |
除了这些参数之外,Flowable Admin应用还有一些其他参数。可以在Github查看配置文件的完整内容。这些参数主要用于为不同的引擎定义REST端点的初始值。 Admin应用使用这些配置连接Flowable引擎。可以使用Admin应用的配置界面修改这些值。这些值保存在ACT_ADM_SERVER_CONFIG表中。 下面是一个BPMN引擎REST的配置示例:
flowable.admin.app.server-config.process.app.name=Flowable Process app
flowable.admin.app.server-config.process.description=Flowable Process REST config
flowable.admin.app.server-config.process.server-address=http://localhost
flowable.admin.app.server-config.process.app.port=8080
flowable.admin.app.server-config.process.context-root=flowable-task
flowable.admin.app.server-config.process.rest-root=process-api
flowable.admin.app.server-config.process.app.user=admin
flowable.admin.app.server-config.process.app.password=test在Flowable Task应用(及全部Flowable引擎)由Flowable Admin应用管理时,可以使用这些参数。
| 原参数 | 描述 |
|---|---|
message.reloading.enabled |
改为使用Spring Boot MessageSourceAutoConfiguration的 |
14.7. 国际化
Flowable UI应用支持国际化(internationalization, i18n)。项目组维护英语版本。但也可以使用自己的翻译文件支持其他语言。
Angular Translate库会试着基于浏览器的语言代码,从(每一个UI应用的)i18n目录下载入对应的语言文件。如果无法加载匹配的语言文件,框架会退回使用英语版本。
也可以(在Angular应用配置中),将多个浏览器语言代码关联至某个翻译文件:
// 初始化angular-translate
$translateProvider.useStaticFilesLoader({
prefix: './i18n/',
suffix: '.json'
})
/*
将多个浏览器语言代码映射至同一个翻译。
*/
// .registerAvailableLanguageKeys(['en'], {
// 'en-*': 'en'
// })
.useCookieStorage()
.useSanitizeValueStrategy('sanitizeParameters')
.uniformLanguageTag('bcp47')
.determinePreferredLanguage();例如,如果浏览器配置为使用英语(美国)——English (United States),即语言代码为en-US。如果不做映射配置,Angular Translate会尝试获取对应的语言文件en-US.json。(如果无法加载,会退回为en,并加载en.json语言文件)
取消注释.registerAvailableLanguageKeys块,就可以将en-US(以及所有其他的en语言代码)映射至en.json语言文件。
14.8. 生产可用的端点
所有应用都可以使用Spring Boot提供的生产可用的端点。参阅Actuator Web API Documentation了解所有可用的端点。
默认使用下列配置:
# 暴露所有Actuator Endpoint
# 尽管会暴露所有的端点,但非认证用户无法访问,认证用户可以访问/info及/health,只有具有access-admin权限的用户可以访问其他端点
management.endpoints.web.exposure.include=*
# 只有认证用户可以访问完整的健康度信息
management.endpoint.health.show-details=when_authorized
# 只有access-admin角色可以访问完整的健康度信息
management.endpoint.health.roles=access-admin安全策略配置为:只有认证用户可以访问 info 及 health 端点。
只有 access-admin 角色可以查看 health 端点的完整信息。
只有 access-admin 角色可以查看其他的任何端点。
15. REST API
15.1. Flowable REST一般原则
15.1.1. 安装与认证
Flowable为Flowable引擎提供了REST API,可以通过在servlet容器(如Apache Tomcat)中部署flowable-rest.war文件来安装。另外,也可以通过在应用中引入servlet(包括对应的映射),并将所有flowable-rest的依赖加入classpath的方式使用。
默认情况下Flowable引擎会连接至一个H2内存数据库。可以通过WEB-INF/META-INF/flowable-app文件夹下的flowable-app.properties文件修改数据库设置。REST API使用JSON格式( http://www.json.org ),并基于Spring MVC( http://docs.spring.io/spring/docs/current/spring-framework-reference/html/mvc.html )构建。
默认情况下访问任何REST资源都需要具有rest-access-api权限的合法用户。如果需要任何合法用户都可以访问REST API,可以将flowable.rest.app.authentication-mode设置为any-user(这也是之前版本Flowable的默认设置)。
通过如下参数设置可以访问REST API的默认用户:
flowable.rest.app.admin.user-id=rest-admin flowable.rest.app.admin.password=test flowable.rest.app.admin.first-name=Rest flowable.rest.app.admin.last-name=Admin
当REST应用启动时,如果用户不存在或无法找到,则会创建该用户。这个用户会被赋予访问REST API所需的access-rest-api权限。请不要忘记修改这个用户的密码。如果未设置flowable.rest.app.admin.user-id,则不会创建用户或权限。也因为此,在初始化完成后删除这些参数,并不会删除之前已经配置的用户或权限。
使用基础HTTP访问认证,因此在请求时,需要在HTTP-header中添加 Authorization: Basic …== 。也可以在请求url中包含用户名与密码(如 http://username:password@localhost:8080/xyz)。
建议使用基础认证时,同时使用HTTPS。
15.1.2. 配置
Flowable REST web应用使用Spring Java Configuration来启动Flowable引擎,使用Spring security定义基础认证安全,并为为特定的变量处理定义了变量转换。 有少量参数可以通过修改WEB-INF/classes文件夹下的engine.properties文件定义。 如果需要高级配置选项,可以在flowable-custom-context.xml文件中覆盖默认的Spring bean,这个文件也在WEB-INF/classes文件夹下。 该文件中已经以注释形式提供了示例配置。也可以在该文件中定义一个新的命名为restResponsefactory的Spring bean,覆盖默认的RestResponseFactory,并使用自定义实现类。
15.1.3. 在Tomcat中使用
由于Tomcat中的默认安全参数,默认不能使用转义斜线符(%2F与%5C)(将返回400)。这可能会影响部署资源与其数据URL,因为URL可能包含转义斜线符。
当发现400异常结果时,可以设置下列系统参数:
-Dorg.apache.tomcat.util.buf.UDecoder.ALLOW_ENCODED_SLASH=true
最佳实践是(在post/put JSON时),在下面介绍的HTTP请求中,永远将Accept与Content-TypeHTTP头设置为application/json。
15.1.4. 方法与返回码
| 方法 | 操作 |
|---|---|
|
获取单个资源,或获取一组资源。 |
|
创建一个新资源。在查询结构太复杂,不能放入GET请求的查询URL中时,也用于执行资源查询。 |
|
更新一个已有资源的参数。也用于调用已有资源提供的操作。 |
|
删除一个已有资源。 |
| 响应 | 描述 |
|---|---|
|
操作成功,返回响应( |
|
操作成功,已经创建了实体,并在响应体中返回( |
|
操作成功,已经删除了实体,因此没有返回的响应体( |
|
操作失败。操作要求设置认证头。如果请求中有认证头,则提供的鉴证并不合法,或者用户未被授权进行该操作。 |
|
操作被禁止,且不应重试。这不是鉴证或授权的问题,而是说明不允许该操作。例如:无论任何用户或流程/任务的状态,删除一个运行中流程的任务是且永远是不允许的。 |
|
操作失败。请求的资源未找到。 |
|
操作失败。使用的方法不能用于该资源。例如,更新(PUT)部署资源将返回 |
|
操作失败。该操作导致更新一个已被其他操作更新的资源,因此本更新不再有效。也可以表示正在为一个集合创建一个资源,但该标识符已存在。 |
|
操作失败。请求提包含了不支持的媒体类型。也会发生在请求体JSON中包含了未知的属性或值,但没有可用的格式/类型来处理的情况。 |
|
操作失败。执行操作时发生了未知异常。响应体中包含了错误的细节。 |
HTTP响应的media-type总是application/json,除非请求的是二进制内容(例如部署资源数据)。这时将使用内容的media-type。
15.1.5. 错误响应体
当发生错误时(可能是客户端或服务器端的错误,4XX及5XX状态码),响应体会包含一个描述了发生的错误的对象。任务未找到时的404状态的例子:
{
"statusCode" : 404,
"errorMessage" : "Could not find a task with id '444'."
}15.1.6. 请求参数
URL片段
作为url的一部分的参数(例如,http://host/flowable-rest/service/repository/deployments/{deploymentId}中的deploymentId参数),如果包含特殊字符,则需要进行合适的转义(参见URL编码或百分号编码)。大多数框架都内建了这个功能,但要记得考虑它。特别是对可能包含斜线符的段落(例如部署资源),就必须要做转义。
Rest URL查询参数
作为查询字符串添加在URL中的参数(例如http://host/flowable-rest/service/deployments?name=Deployment中的name参数)可以使用下列类型。在相应的REST-API文档中也会提到:
| 类型 | 格式 |
|---|---|
String |
纯文本参数。可以包含任何URL允许的合法字符。对于 |
Integer |
整形参数。只能包含数字型非小数值,在-2.147.483.648至2.147.483.647之间。 |
Long |
长整形参数。只能包含数字型非小数值,在-9.223.372.036.854.775.808至9.223.372.036.854.775.807之间。 |
Boolean |
boolean型参数。可以为 |
Date |
日期型参数。使用ISO-8601日期格式(参考wikipedia中的ISO-8601),使用时间与日期部分(例如 |
JSON body 参数
| 类型 | 格式 |
|---|---|
String |
纯文本参数。对于 |
Integer |
整形参数,使用JSON数字。只能包含数字型非小数值,在-2.147.483.648至2.147.483.647之间。 |
Long |
长整形参数,使用JSON数字。只能包含数字型非小数值,在-9.223.372.036.854.775.808至9.223.372.036.854.775.807之间。 |
Date |
日期型参数,使用JSON文本。使用ISO-8601日期格式(参考wikipedia中的ISO-8601),使用时间与日期组分(例如 |
分页与排序
分页与排序参数可以作为查询字符串加入URL中(例如http://host/flowable-rest/service/deployments?sort=name中的name参数)。
| 参数 | 默认值 | 描述 |
|---|---|---|
sort |
各查询实现不同 |
排序键的名字,在各查询实现中默认值与可用值都不同。 |
order |
asc |
排序顺序,可以是’asc'(顺序)或’desc'(逆序)。 |
start |
0 |
对结果分页的参数。默认结果从0开始。 |
size |
10 |
对结果分页的参数。默认大小为10. |
JSON查询变量格式
{
"name" : "variableName",
"value" : "variableValue",
"operation" : "equals",
"type" : "string"
}| 参数 | 必填 | 描述 |
|---|---|---|
name |
否 |
包含在查询中的变量名。在有些使用' |
value |
是 |
包含在查询中的变量值,需要使用给定类型的正确格式。 |
operator |
是 |
查询使用的操作,可以为下列值: |
type |
否 |
所用变量的类型。当省略时,会从 |
| 类型名 | 描述 |
|---|---|
string |
值处理转换为 |
short |
值处理转换为 |
integer |
值处理转换为 |
long |
值处理转换为 |
double |
值处理转换为 |
boolean |
值处理转换为 |
date |
值处理转换为 |
变量表示
读取与写入变量(执行选择)时,REST API都使用通用原则与JSON格式。变量的JSON表示为:
{
"name" : "variableName",
"value" : "variableValue",
"valueUrl" : "http://...",
"type" : "string"
}| 参数 | 必填 | 描述 |
|---|---|---|
name |
是 |
变量名。 |
value |
否 |
变量的值。当写入变量且省略了 |
valueUrl |
否 |
当读取 |
type |
否 |
变量的类型。查看下面的表格了解类型的更多信息。当写入变量且省略了这个值时,将使用请求的原始JSON属性类型推断,限制在 |
| 类型名 | 描述 |
|---|---|
string |
值按照 |
integer |
值按照 |
short |
值按照 |
long |
值按照 |
double |
值按照 |
boolean |
值按照 |
date |
值按照 |
可以使用自定义JSON表示,以支持额外的变量类型(既可以是简单值,也可以是复杂/嵌套的JSON对象)。通过扩展org.flowable.rest.service.api.RestResponseFactory的initializeVariableConverters()方法,可以添加额外的org.flowable.rest.service.api.engine.variable.RestVariableConverter类,用于将POJO转换为适合通过REST传输的格式,以及将REST值转换为POJO。实际转换JSON使用Jackson。
15.2. Deployment
When using tomcat, please read Usage in Tomcat.
15.2.1. List of Deployments
GET repository/deployments
| Parameter | Required | Value | Description |
|---|---|---|---|
name |
No |
String |
Only return deployments with the given name. |
nameLike |
No |
String |
Only return deployments with a name like the given name. |
category |
No |
String |
Only return deployments with the given category. |
categoryNotEquals |
No |
String |
Only return deployments which don’t have the given category. |
tenantId |
No |
String |
Only return deployments with the given tenantId. |
tenantIdLike |
No |
String |
Only return deployments with a tenantId like the given value. |
withoutTenantId |
No |
Boolean |
If |
sort |
No |
id (default), name, deployTime or tenantId |
Property to sort on, to be used together with the order. |
| Response code | Description |
|---|---|
200 |
Indicates the request was successful. |
Success response body:
{
"data": [
{
"id": "10",
"name": "flowable-examples.bar",
"deploymentTime": "2010-10-13T14:54:26.750+02:00",
"category": "examples",
"url": "http://localhost:8081/flowable-rest/service/repository/deployments/10",
"tenantId": null
}
],
"total": 1,
"start": 0,
"sort": "id",
"order": "asc",
"size": 1
}15.2.2. Get a deployment
GET repository/deployments/{deploymentId}
| Parameter | Required | Value | Description |
|---|---|---|---|
deploymentId |
Yes |
String |
The id of the deployment to get. |
| Response code | Description |
|---|---|
200 |
Indicates the deployment was found and returned. |
404 |
Indicates the requested deployment was not found. |
Success response body:
{
"id": "10",
"name": "flowable-examples.bar",
"deploymentTime": "2010-10-13T14:54:26.750+02:00",
"category": "examples",
"url": "http://localhost:8081/flowable-rest/service/repository/deployments/10",
"tenantId" : null
}15.2.3. Create a new deployment
POST repository/deployments
Request body:
The request body should contain data of type multipart/form-data. There should be exactly one file in the request, any additional files will be ignored. The deployment name is the name of the file-field passed in. If multiple resources need to be deployed in a single deployment, compress the resources in a zip and make sure the file-name ends with .bar or .zip.
An additional parameter (form-field) can be passed in the request body with name tenantId. The value of this field will be used as the id of the tenant this deployment is done in.
| Response code | Description |
|---|---|
201 |
Indicates the deployment was created. |
400 |
Indicates there was no content present in the request body or the content mime-type is not supported for deployment. The status-description contains additional information. |
Success response body:
{
"id": "10",
"name": "flowable-examples.bar",
"deploymentTime": "2010-10-13T14:54:26.750+02:00",
"category": null,
"url": "http://localhost:8081/flowable-rest/service/repository/deployments/10",
"tenantId" : "myTenant"
}15.2.4. Delete a deployment
DELETE repository/deployments/{deploymentId}
| Parameter | Required | Value | Description |
|---|---|---|---|
deploymentId |
Yes |
String |
The id of the deployment to delete. |
| Response code | Description |
|---|---|
204 |
Indicates the deployment was found and has been deleted. Response-body is intentionally empty. |
404 |
Indicates the requested deployment was not found. |
15.2.5. List resources in a deployment
GET repository/deployments/{deploymentId}/resources
| Parameter | Required | Value | Description |
|---|---|---|---|
deploymentId |
Yes |
String |
The id of the deployment to get the resources for. |
| Response code | Description |
|---|---|
200 |
Indicates the deployment was found and the resource list has been returned. |
404 |
Indicates the requested deployment was not found. |
Success response body:
[
{
"id": "diagrams/my-process.bpmn20.xml",
"url": "http://localhost:8081/flowable-rest/service/repository/deployments/10/resources/diagrams%2Fmy-process.bpmn20.xml",
"dataUrl": "http://localhost:8081/flowable-rest/service/repository/deployments/10/resourcedata/diagrams%2Fmy-process.bpmn20.xml",
"mediaType": "text/xml",
"type": "processDefinition"
},
{
"id": "image.png",
"url": "http://localhost:8081/flowable-rest/service/repository/deployments/10/resources/image.png",
"dataUrl": "http://localhost:8081/flowable-rest/service/repository/deployments/10/resourcedata/image.png",
"mediaType": "image/png",
"type": "resource"
}
]-
mediaType: Contains the media-type the resource has. This is resolved using a (pluggable)MediaTypeResolverand contains, by default, a limited number of mime-type mappings. -
type: Type of resource, possible values: -
resource: Plain old resource. -
processDefinition: Resource that contains one or more process-definitions. This resource is picked up by the deployer. -
processImage: Resource that represents a deployed process definition’s graphical layout.
The dataUrl property in the resulting JSON for a single resource contains the actual URL to use for retrieving the binary resource.
15.2.6. Get a deployment resource
GET repository/deployments/{deploymentId}/resources/{resourceId}
| Parameter | Required | Value | Description |
|---|---|---|---|
deploymentId |
Yes |
String |
The id of the deployment the requested resource is part of. |
resourceId |
Yes |
String |
The id of the resource to get. Make sure you URL-encode the resourceId in case it contains forward slashes. Eg: use diagrams%2Fmy-process.bpmn20.xml instead of diagrams/Fmy-process.bpmn20.xml. |
| Response code | Description |
|---|---|
200 |
Indicates both deployment and resource have been found and the resource has been returned. |
404 |
Indicates the requested deployment was not found or there is no resource with the given id present in the deployment. The status-description contains additional information. |
Success response body:
{
"id": "diagrams/my-process.bpmn20.xml",
"url": "http://localhost:8081/flowable-rest/service/repository/deployments/10/resources/diagrams%2Fmy-process.bpmn20.xml",
"dataUrl": "http://localhost:8081/flowable-rest/service/repository/deployments/10/resourcedata/diagrams%2Fmy-process.bpmn20.xml",
"mediaType": "text/xml",
"type": "processDefinition"
}-
mediaType: Contains the media-type the resource has. This is resolved using a (pluggable)MediaTypeResolverand contains, by default, a limited number of mime-type mappings. -
type: Type of resource, possible values: -
resource: Plain old resource. -
processDefinition: Resource that contains one or more process-definitions. This resource is picked up by the deployer. -
processImage: Resource that represents a deployed process definition’s graphical layout.
15.2.7. Get a deployment resource content
GET repository/deployments/{deploymentId}/resourcedata/{resourceId}
| Parameter | Required | Value | Description |
|---|---|---|---|
deploymentId |
Yes |
String |
The id of the deployment the requested resource is part of. |
resourceId |
Yes |
String |
The id of the resource to get the data for. Make sure you URL-encode the resourceId in case it contains forward slashes. Eg: use diagrams%2Fmy-process.bpmn20.xml instead of diagrams/Fmy-process.bpmn20.xml. |
.Get a deployment resource content - Response codes
| Response code | Description |
|---|---|
200 |
Indicates both deployment and resource have been found and the resource data has been returned. |
404 |
Indicates the requested deployment was not found or there is no resource with the given id present in the deployment. The status-description contains additional information. |
Success response body:
The response body will contain the binary resource-content for the requested resource. The response content-type will be the same as the type returned in the resources mimeType property. Also, a content-disposition header is set, allowing browsers to download the file instead of displaying it.
15.3. Process Definitions
15.3.1. List of process definitions
GET repository/process-definitions
| Parameter | Required | Value | Description |
|---|---|---|---|
version |
No |
integer |
Only return process definitions with the given version. |
name |
No |
String |
Only return process definitions with the given name. |
nameLike |
No |
String |
Only return process definitions with a name like the given name. |
key |
No |
String |
Only return process definitions with the given key. |
keyLike |
No |
String |
Only return process definitions with a name like the given key. |
resourceName |
No |
String |
Only return process definitions with the given resource name. |
resourceNameLike |
No |
String |
Only return process definitions with a name like the given resource name. |
category |
No |
String |
Only return process definitions with the given category. |
categoryLike |
No |
String |
Only return process definitions with a category like the given name. |
categoryNotEquals |
No |
String |
Only return process definitions which don’t have the given category. |
deploymentId |
No |
String |
Only return process definitions which are part of a deployment with the given id. |
startableByUser |
No |
String |
Only return process definitions which can be started by the given user. |
latest |
No |
Boolean |
Only return the latest process definition versions. Can only be used together with key and keyLike parameters, using any other parameter will result in a 400-response. |
suspended |
No |
Boolean |
If |
sort |
No |
name (default), id, key, category, deploymentId and version |
Property to sort on, to be used together with the order. |
| Response code | Description |
|---|---|
200 |
Indicates request was successful and the process-definitions are returned |
400 |
Indicates a parameter was passed in the wrong format or that latest is used with other parameters other than key and keyLike. The status-message contains additional information. |
Success response body:
{
"data": [
{
"id" : "oneTaskProcess:1:4",
"url" : "http://localhost:8182/repository/process-definitions/oneTaskProcess%3A1%3A4",
"version" : 1,
"key" : "oneTaskProcess",
"category" : "Examples",
"suspended" : false,
"name" : "The One Task Process",
"description" : "This is a process for testing purposes",
"deploymentId" : "2",
"deploymentUrl" : "http://localhost:8081/repository/deployments/2",
"graphicalNotationDefined" : true,
"resource" : "http://localhost:8182/repository/deployments/2/resources/testProcess.xml",
"diagramResource" : "http://localhost:8182/repository/deployments/2/resources/testProcess.png",
"startFormDefined" : false
}
],
"total": 1,
"start": 0,
"sort": "name",
"order": "asc",
"size": 1
}-
graphicalNotationDefined: Indicates the process definition contains graphical information (BPMN DI). -
resource: Contains the actual deployed BPMN 2.0 xml. -
diagramResource: Contains a graphical representation of the process, null when no diagram is available.
15.3.2. Get a process definition
GET repository/process-definitions/{processDefinitionId}
| Parameter | Required | Value | Description |
|---|---|---|---|
processDefinitionId |
Yes |
String |
The id of the process definition to get. |
| Response code | Description |
|---|---|
200 |
Indicates the process definition was found and returned. |
404 |
Indicates the requested process definition was not found. |
Success response body:
{
"id" : "oneTaskProcess:1:4",
"url" : "http://localhost:8182/repository/process-definitions/oneTaskProcess%3A1%3A4",
"version" : 1,
"key" : "oneTaskProcess",
"category" : "Examples",
"suspended" : false,
"name" : "The One Task Process",
"description" : "This is a process for testing purposes",
"deploymentId" : "2",
"deploymentUrl" : "http://localhost:8081/repository/deployments/2",
"graphicalNotationDefined" : true,
"resource" : "http://localhost:8182/repository/deployments/2/resources/testProcess.xml",
"diagramResource" : "http://localhost:8182/repository/deployments/2/resources/testProcess.png",
"startFormDefined" : false
}-
graphicalNotationDefined: Indicates the process definition contains graphical information (BPMN DI). -
resource: Contains the actual deployed BPMN 2.0 xml. -
diagramResource: Contains a graphical representation of the process, null when no diagram is available.
15.3.3. Update category for a process definition
PUT repository/process-definitions/{processDefinitionId}
Body JSON:
{
"category" : "updatedcategory"
}| Response code | Description |
|---|---|
200 |
Indicates the process was category was altered. |
400 |
Indicates no category was defined in the request body. |
404 |
Indicates the requested process definition was not found. |
Success response body: see response for repository/process-definitions/{processDefinitionId}.
15.3.4. Get a process definition resource content
GET repository/process-definitions/{processDefinitionId}/resourcedata
| Parameter | Required | Value | Description |
|---|---|---|---|
processDefinitionId |
Yes |
String |
The id of the process definition to get the resource data for. |
Response:
Exactly the same response codes/boy as GET repository/deployment/{deploymentId}/resourcedata/{resourceId}.
15.3.5. Get a process definition BPMN model
GET repository/process-definitions/{processDefinitionId}/model
| Parameter | Required | Value | Description |
|---|---|---|---|
processDefinitionId |
Yes |
String |
The id of the process definition to get the model for. |
| Response code | Description |
|---|---|
200 |
Indicates the process definition was found and the model is returned. |
404 |
Indicates the requested process definition was not found. |
Response body:
The response body is a JSON representation of the org.flowable.bpmn.model.BpmnModel and contains the full process definition model.
{
"processes":[
{
"id":"oneTaskProcess",
"xmlRowNumber":7,
"xmlColumnNumber":60,
"extensionElements":{
},
"name":"The One Task Process",
"executable":true,
"documentation":"One task process description",
]
}15.3.6. Suspend a process definition
PUT repository/process-definitions/{processDefinitionId}
Body JSON:
{
"action" : "suspend",
"includeProcessInstances" : "false",
"date" : "2013-04-15T00:42:12Z"
}| Parameter | Description | Required |
|---|---|---|
action |
Action to perform. Either |
Yes |
includeProcessInstances |
Whether or not to suspend/activate running process-instances for this process-definition. If omitted, the process-instances are left in the state they are. |
No |
date |
Date (ISO-8601) when the suspension/activation should be executed. If omitted, the suspend/activation is effective immediately. |
No |
| Response code | Description |
|---|---|
200 |
Indicates the process was suspended. |
404 |
Indicates the requested process definition was not found. |
409 |
Indicates the requested process definition is already suspended. |
Success response body: see response for repository/process-definitions/{processDefinitionId}.
15.3.7. Activate a process definition
PUT repository/process-definitions/{processDefinitionId}
Body JSON:
{
"action" : "activate",
"includeProcessInstances" : "true",
"date" : "2013-04-15T00:42:12Z"
}See suspend process definition JSON Body parameters.
| Response code | Description |
|---|---|
200 |
Indicates the process was activated. |
404 |
Indicates the requested process definition was not found. |
409 |
Indicates the requested process definition is already active. |
Success response body: see response for repository/process-definitions/{processDefinitionId}.
15.3.8. Get all candidate starters for a process-definition
GET repository/process-definitions/{processDefinitionId}/identitylinks
| Parameter | Required | Value | Description |
|---|---|---|---|
processDefinitionId |
Yes |
String |
The id of the process definition to get the identity links for. |
| Response code | Description |
|---|---|
200 |
Indicates the process definition was found and the requested identity links are returned. |
404 |
Indicates the requested process definition was not found. |
Success response body:
[
{
"url":"http://localhost:8182/repository/process-definitions/oneTaskProcess%3A1%3A4/identitylinks/groups/admin",
"user":null,
"group":"admin",
"type":"candidate"
},
{
"url":"http://localhost:8182/repository/process-definitions/oneTaskProcess%3A1%3A4/identitylinks/users/kermit",
"user":"kermit",
"group":null,
"type":"candidate"
}
]15.3.9. Add a candidate starter to a process definition
POST repository/process-definitions/{processDefinitionId}/identitylinks
| Parameter | Required | Value | Description |
|---|---|---|---|
processDefinitionId |
Yes |
String |
The id of the process definition. |
Request body (user):
{
"user" : "kermit"
}Request body (group):
{
"groupId" : "sales"
}| Response code | Description |
|---|---|
201 |
Indicates the process definition was found and the identity link was created. |
404 |
Indicates the requested process definition was not found. |
Success response body:
{
"url":"http://localhost:8182/repository/process-definitions/oneTaskProcess%3A1%3A4/identitylinks/users/kermit",
"user":"kermit",
"group":null,
"type":"candidate"
}15.3.10. Delete a candidate starter from a process definition
DELETE repository/process-definitions/{processDefinitionId}/identitylinks/{family}/{identityId}
| Parameter | Required | Value | Description |
|---|---|---|---|
processDefinitionId |
Yes |
String |
The id of the process definition. |
family |
Yes |
String |
Either |
identityId |
Yes |
String |
Either the userId or groupId of the identity to remove as candidate starter. |
| Response code | Description |
|---|---|
204 |
Indicates the process definition was found and the identity link was removed. The response body is intentionally empty. |
404 |
Indicates the requested process definition was not found or the process definition doesn’t have an identity-link that matches the url. |
Success response body:
{
"url":"http://localhost:8182/repository/process-definitions/oneTaskProcess%3A1%3A4/identitylinks/users/kermit",
"user":"kermit",
"group":null,
"type":"candidate"
}15.3.11. Get a candidate starter from a process definition
GET repository/process-definitions/{processDefinitionId}/identitylinks/{family}/{identityId}
| Parameter | Required | Value | Description |
|---|---|---|---|
processDefinitionId |
Yes |
String |
The id of the process definition. |
family |
Yes |
String |
Either |
identityId |
Yes |
String |
Either the userId or groupId of the identity to get as candidate starter. |
| Response code | Description |
|---|---|
200 |
Indicates the process definition was found and the identity link was returned. |
404 |
Indicates the requested process definition was not found or the process definition doesn’t have an identity-link that matches the url. |
Success response body:
{
"url":"http://localhost:8182/repository/process-definitions/oneTaskProcess%3A1%3A4/identitylinks/users/kermit",
"user":"kermit",
"group":null,
"type":"candidate"
}15.4. Models
15.4.1. Get a list of models
GET repository/models
| Parameter | Required | Value | Description |
|---|---|---|---|
id |
No |
String |
Only return models with the given id. |
category |
No |
String |
Only return models with the given category. |
categoryLike |
No |
String |
Only return models with a category like the given value. Use the |
categoryNotEquals |
No |
String |
Only return models without the given category. |
name |
No |
String |
Only return models with the given name. |
nameLike |
No |
String |
Only return models with a name like the given value. Use the |
key |
No |
String |
Only return models with the given key. |
deploymentId |
No |
String |
Only return models which are deployed in the given deployment. |
version |
No |
Integer |
Only return models with the given version. |
latestVersion |
No |
Boolean |
If |
deployed |
No |
Boolean |
If |
tenantId |
No |
String |
Only return models with the given tenantId. |
tenantIdLike |
No |
String |
Only return models with a tenantId like the given value. |
withoutTenantId |
No |
Boolean |
If |
sort |
No |
id (default), category, createTime, key, lastUpdateTime, name, version or tenantId |
Property to sort on, to be used together with the order. |
| Response code | Description |
|---|---|
200 |
Indicates request was successful and the models are returned |
400 |
Indicates a parameter was passed in the wrong format. The status-message contains additional information. |
Success response body:
{
"data":[
{
"name":"Model name",
"key":"Model key",
"category":"Model category",
"version":2,
"metaInfo":"Model metainfo",
"deploymentId":"7",
"id":"10",
"url":"http://localhost:8182/repository/models/10",
"createTime":"2013-06-12T14:31:08.612+0000",
"lastUpdateTime":"2013-06-12T14:31:08.612+0000",
"deploymentUrl":"http://localhost:8182/repository/deployments/7",
"tenantId":null
},
...
],
"total":2,
"start":0,
"sort":"id",
"order":"asc",
"size":2
}15.4.2. Get a model
GET repository/models/{modelId}
| Parameter | Required | Value | Description |
|---|---|---|---|
modelId |
Yes |
String |
The id of the model to get. |
| Response code | Description |
|---|---|
200 |
Indicates the model was found and returned. |
404 |
Indicates the requested model was not found. |
Success response body:
{
"id":"5",
"url":"http://localhost:8182/repository/models/5",
"name":"Model name",
"key":"Model key",
"category":"Model category",
"version":2,
"metaInfo":"Model metainfo",
"deploymentId":"2",
"deploymentUrl":"http://localhost:8182/repository/deployments/2",
"createTime":"2013-06-12T12:31:19.861+0000",
"lastUpdateTime":"2013-06-12T12:31:19.861+0000",
"tenantId":null
}15.4.3. Update a model
PUT repository/models/{modelId}
Request body:
{
"name":"Model name",
"key":"Model key",
"category":"Model category",
"version":2,
"metaInfo":"Model metainfo",
"deploymentId":"2",
"tenantId":"updatedTenant"
}All request values are optional. For example, you can only include the name attribute in the request body JSON-object, only updating the name of the model, leaving all other fields unaffected. When an attribute is explicitly included and is set to null, the model-value will be updated to null. Example: {"metaInfo" : null} will clear the metaInfo of the model).
| Response code | Description |
|---|---|
200 |
Indicates the model was found and updated. |
404 |
Indicates the requested model was not found. |
Success response body:
{
"id":"5",
"url":"http://localhost:8182/repository/models/5",
"name":"Model name",
"key":"Model key",
"category":"Model category",
"version":2,
"metaInfo":"Model metainfo",
"deploymentId":"2",
"deploymentUrl":"http://localhost:8182/repository/deployments/2",
"createTime":"2013-06-12T12:31:19.861+0000",
"lastUpdateTime":"2013-06-12T12:31:19.861+0000",
"tenantId":""updatedTenant"
}15.4.4. Create a model
POST repository/models
Request body:
{
"name":"Model name",
"key":"Model key",
"category":"Model category",
"version":1,
"metaInfo":"Model metainfo",
"deploymentId":"2",
"tenantId":"tenant"
}All request values are optional. For example, you can only include the name attribute in the request body JSON-object, only setting the name of the model, leaving all other fields null.
| Response code | Description |
|---|---|
201 |
Indicates the model was created. |
Success response body:
{
"id":"5",
"url":"http://localhost:8182/repository/models/5",
"name":"Model name",
"key":"Model key",
"category":"Model category",
"version":1,
"metaInfo":"Model metainfo",
"deploymentId":"2",
"deploymentUrl":"http://localhost:8182/repository/deployments/2",
"createTime":"2013-06-12T12:31:19.861+0000",
"lastUpdateTime":"2013-06-12T12:31:19.861+0000",
"tenantId":"tenant"
}15.4.5. Delete a model
DELETE repository/models/{modelId}
| Parameter | Required | Value | Description |
|---|---|---|---|
modelId |
Yes |
String |
The id of the model to delete. |
| Response code | Description |
|---|---|
204 |
Indicates the model was found and has been deleted. Response-body is intentionally empty. |
404 |
Indicates the requested model was not found. |
15.4.6. Get the editor source for a model
GET repository/models/{modelId}/source
| Parameter | Required | Value | Description |
|---|---|---|---|
modelId |
Yes |
String |
The id of the model. |
| Response code | Description |
|---|---|
200 |
Indicates the model was found and source is returned. |
404 |
Indicates the requested model was not found. |
Success response body:
Response body contains the model’s raw editor source. The response’s content-type is set to application/octet-stream, regardless of the content of the source.
15.4.7. Set the editor source for a model
PUT repository/models/{modelId}/source
| Parameter | Required | Value | Description |
|---|---|---|---|
modelId |
Yes |
String |
The id of the model. |
Request body:
The request should be of type multipart/form-data. There should be a single file-part included with the binary value of the source.
| Response code | Description |
|---|---|
200 |
Indicates the model was found and the source has been updated. |
404 |
Indicates the requested model was not found. |
Success response body:
Response body contains the model’s raw editor source. The response’s content-type is set to application/octet-stream, regardless of the content of the source.
15.4.8. Get the extra editor source for a model
GET repository/models/{modelId}/source-extra
| Parameter | Required | Value | Description |
|---|---|---|---|
modelId |
Yes |
String |
The id of the model. |
| Response code | Description |
|---|---|
200 |
Indicates the model was found and source is returned. |
404 |
Indicates the requested model was not found. |
Success response body:
Response body contains the model’s raw extra editor source. The response’s content-type is set to application/octet-stream, regardless of the content of the extra source.
15.4.9. Set the extra editor source for a model
PUT repository/models/{modelId}/source-extra
| Parameter | Required | Value | Description |
|---|---|---|---|
modelId |
Yes |
String |
The id of the model. |
Request body:
The request should be of type multipart/form-data. There should be a single file-part included with the binary value of the extra source.
| Response code | Description |
|---|---|
200 |
Indicates the model was found and the extra source has been updated. |
404 |
Indicates the requested model was not found. |
Success response body:
Response body contains the model’s raw editor source. The response’s content-type is set to application/octet-stream, regardless of the content of the source.
15.5. Process Instances
15.5.1. Get a process instance
GET runtime/process-instances/{processInstanceId}
| Parameter | Required | Value | Description |
|---|---|---|---|
processInstanceId |
Yes |
String |
The id of the process instance to get. |
| Response code | Description |
|---|---|
200 |
Indicates the process instance was found and returned. |
404 |
Indicates the requested process instance was not found. |
Success response body:
{
"id":"7",
"url":"http://localhost:8182/runtime/process-instances/7",
"businessKey":"myBusinessKey",
"suspended":false,
"processDefinitionUrl":"http://localhost:8182/repository/process-definitions/processOne%3A1%3A4",
"activityId":"processTask",
"tenantId": null
}15.5.2. Delete a process instance
DELETE runtime/process-instances/{processInstanceId}
| Parameter | Required | Value | Description |
|---|---|---|---|
processInstanceId |
Yes |
String |
The id of the process instance to delete. |
| Response code | Description |
|---|---|
204 |
Indicates the process instance was found and deleted. Response body is left empty intentionally. |
404 |
Indicates the requested process instance was not found. |
15.5.3. Activate or suspend a process instance
PUT runtime/process-instances/{processInstanceId}
| Parameter | Required | Value | Description |
|---|---|---|---|
processInstanceId |
Yes |
String |
The id of the process instance to activate/suspend. |
Request response body (suspend):
{
"action":"suspend"
}Request response body (activate):
{
"action":"activate"
}| Response code | Description |
|---|---|
200 |
Indicates the process instance was found and action was executed. |
400 |
Indicates an invalid action was supplied. |
404 |
Indicates the requested process instance was not found. |
409 |
Indicates the requested process instance action cannot be executed since the process-instance is already activated/suspended. |
15.5.4. Start a process instance
POST runtime/process-instances
Request body (start by process definition id):
{
"processDefinitionId":"oneTaskProcess:1:158",
"businessKey":"myBusinessKey",
"returnVariables":true,
"variables": [
{
"name":"myVar",
"value":"This is a variable"
}
]
}Request body (start by process definition key):
{
"processDefinitionKey":"oneTaskProcess",
"businessKey":"myBusinessKey",
"returnVariables":false,
"tenantId": "tenant1",
"variables": [
{
"name":"myVar",
"value":"This is a variable"
}
]
}Request body (start by message):
{
"message":"newOrderMessage",
"businessKey":"myBusinessKey",
"tenantId": "tenant1",
"variables": [
{
"name":"myVar",
"value":"This is a variable"
}
]
}Note that also a transientVariables property is accepted as part of this json, that follows the same structure as the variables property.
The returnVariables property can be used to get the existing variables in the process instance context back in the response. By default the variables are not returned.
Only one of processDefinitionId, processDefinitionKey or message can be used in the request body. Parameters businessKey, variables and tenantId are optional. If tenantId is omitted, the default tenant will be used. More information about the variable format can be found in the REST variables section. Note that the variable-scope that is supplied is ignored, process-variables are always local.
| Response code | Description |
|---|---|
201 |
Indicates the process instance was created. |
400 |
Indicates either the process-definition was not found (based on id or key), no process is started by sending the given message or an invalid variable has been passed. Status description contains additional information about the error. |
Success response body:
{
"id":"7",
"url":"http://localhost:8182/runtime/process-instances/7",
"businessKey":"myBusinessKey",
"suspended":false,
"processDefinitionUrl":"http://localhost:8182/repository/process-definitions/processOne%3A1%3A4",
"activityId":"processTask",
"tenantId" : null
}15.5.5. List of process instances
GET runtime/process-instances
| Parameter | Required | Value | Description |
|---|---|---|---|
id |
No |
String |
Only return process instance with the given id. |
processDefinitionKey |
No |
String |
Only return process instances with the given process definition key. |
processDefinitionId |
No |
String |
Only return process instances with the given process definition id. |
businessKey |
No |
String |
Only return process instances with the given businessKey. |
involvedUser |
No |
String |
Only return process instances in which the given user is involved. |
suspended |
No |
Boolean |
If |
superProcessInstanceId |
No |
String |
Only return process instances which have the given super process-instance id (for processes that have a call-activities). |
subProcessInstanceId |
No |
String |
Only return process instances which have the given sub process-instance id (for processes started as a call-activity). |
excludeSubprocesses |
No |
Boolean |
Return only process instances which aren’t sub processes. |
includeProcessVariables |
No |
Boolean |
Indication to include process variables in the result. |
tenantId |
No |
String |
Only return process instances with the given tenantId. |
tenantIdLike |
No |
String |
Only return process instances with a tenantId like the given value. |
withoutTenantId |
No |
Boolean |
If |
sort |
No |
String |
Sort field, should be either one of |
| Response code | Description |
|---|---|
200 |
Indicates request was successful and the process-instances are returned |
400 |
Indicates a parameter was passed in the wrong format . The status-message contains additional information. |
Success response body:
{
"data":[
{
"id":"7",
"url":"http://localhost:8182/runtime/process-instances/7",
"businessKey":"myBusinessKey",
"suspended":false,
"processDefinitionUrl":"http://localhost:8182/repository/process-definitions/processOne%3A1%3A4",
"activityId":"processTask",
"tenantId" : null
}
],
"total":2,
"start":0,
"sort":"id",
"order":"asc",
"size":2
}15.5.6. Query process instances
POST query/process-instances
Request body:
{
"processDefinitionKey":"oneTaskProcess",
"variables":
[
{
"name" : "myVariable",
"value" : 1234,
"operation" : "equals",
"type" : "long"
}
]
}The request body can contain all possible filters that can be used in the List process instances URL query. On top of these, it’s possible to provide an array of variables to include in the query, with their format described here.
The general paging and sorting query-parameters can be used for this URL.
| Response code | Description |
|---|---|
200 |
Indicates request was successful and the process-instances are returned |
400 |
Indicates a parameter was passed in the wrong format . The status-message contains additional information. |
Success response body:
{
"data":[
{
"id":"7",
"url":"http://localhost:8182/runtime/process-instances/7",
"businessKey":"myBusinessKey",
"suspended":false,
"processDefinitionUrl":"http://localhost:8182/repository/process-definitions/processOne%3A1%3A4",
"activityId":"processTask",
"tenantId" : null
}
],
"total":2,
"start":0,
"sort":"id",
"order":"asc",
"size":2
}15.5.7. Get diagram for a process instance
GET runtime/process-instances/{processInstanceId}/diagram
| Parameter | Required | Value | Description |
|---|---|---|---|
processInstanceId |
Yes |
String |
The id of the process instance to get the diagram for. |
| Response code | Description |
|---|---|
200 |
Indicates the process instance was found and the diagram was returned. |
400 |
Indicates the requested process instance was not found but the process doesn’t contain any graphical information (BPMN:DI) and no diagram can be created. |
404 |
Indicates the requested process instance was not found. |
Success response body:
{
"id":"7",
"url":"http://localhost:8182/runtime/process-instances/7",
"businessKey":"myBusinessKey",
"suspended":false,
"processDefinitionUrl":"http://localhost:8182/repository/process-definitions/processOne%3A1%3A4",
"activityId":"processTask"
}15.5.8. Get involved people for process instance
GET runtime/process-instances/{processInstanceId}/identitylinks
| Parameter | Required | Value | Description |
|---|---|---|---|
processInstanceId |
Yes |
String |
The id of the process instance to the links for. |
| Response code | Description |
|---|---|
200 |
Indicates the process instance was found and links are returned. |
404 |
Indicates the requested process instance was not found. |
Success response body:
[
{
"url":"http://localhost:8182/runtime/process-instances/5/identitylinks/users/john/customType",
"user":"john",
"group":null,
"type":"customType"
},
{
"url":"http://localhost:8182/runtime/process-instances/5/identitylinks/users/paul/candidate",
"user":"paul",
"group":null,
"type":"candidate"
}
]Note that the groupId will always be null, as it’s only possible to involve users with a process-instance.
15.5.9. Add an involved user to a process instance
POST runtime/process-instances/{processInstanceId}/identitylinks
| Parameter | Required | Value | Description |
|---|---|---|---|
processInstanceId |
Yes |
String |
The id of the process instance to the links for. |
Request body:
{
"userId":"kermit",
"type":"participant"
}Both userId and type are required.
| Response code | Description |
|---|---|
201 |
Indicates the process instance was found and the link is created. |
400 |
Indicates the requested body did not contain a userId or a type. |
404 |
Indicates the requested process instance was not found. |
Success response body:
{
"url":"http://localhost:8182/runtime/process-instances/5/identitylinks/users/john/customType",
"user":"john",
"group":null,
"type":"customType"
}Note that the groupId will always be null, as it’s only possible to involve users with a process-instance.
15.5.10. Remove an involved user to from process instance
DELETE runtime/process-instances/{processInstanceId}/identitylinks/users/{userId}/{type}
| Parameter | Required | Value | Description |
|---|---|---|---|
processInstanceId |
Yes |
String |
The id of the process instance. |
userId |
Yes |
String |
The id of the user to delete link for. |
type |
Yes |
String |
Type of link to delete. |
| Response code | Description |
|---|---|
204 |
Indicates the process instance was found and the link has been deleted. Response body is left empty intentionally. |
404 |
Indicates the requested process instance was not found or the link to delete doesn’t exist. The response status contains additional information about the error. |
Success response body:
{
"url":"http://localhost:8182/runtime/process-instances/5/identitylinks/users/john/customType",
"user":"john",
"group":null,
"type":"customType"
}Note that the groupId will always be null, as it’s only possible to involve users with a process-instance.
15.5.11. List of variables for a process instance
GET runtime/process-instances/{processInstanceId}/variables
| Parameter | Required | Value | Description |
|---|---|---|---|
processInstanceId |
Yes |
String |
The id of the process instance to the variables for. |
| Response code | Description |
|---|---|
200 |
Indicates the process instance was found and variables are returned. |
404 |
Indicates the requested process instance was not found. |
Success response body:
[
{
"name":"intProcVar",
"type":"integer",
"value":123,
"scope":"local"
},
{
"name":"byteArrayProcVar",
"type":"binary",
"value":null,
"valueUrl":"http://localhost:8182/runtime/process-instances/5/variables/byteArrayProcVar/data",
"scope":"local"
}
]In case the variable is a binary variable or serializable, the valueUrl points to an URL to fetch the raw value. If it’s a plain variable, the value is present in the response.
Note that only local scoped variables are returned, as there is no global scope for process-instance variables.
15.5.12. Get a variable for a process instance
GET runtime/process-instances/{processInstanceId}/variables/{variableName}
| Parameter | Required | Value | Description |
|---|---|---|---|
processInstanceId |
Yes |
String |
The id of the process instance to the variables for. |
variableName |
Yes |
String |
Name of the variable to get. |
| Response code | Description |
|---|---|
200 |
Indicates both the process instance and variable were found and variable is returned. |
400 |
Indicates the request body is incomplete or contains illegal values. The status description contains additional information about the error. |
404 |
Indicates the requested process instance was not found or the process instance does not have a variable with the given name. Status description contains additional information about the error. |
Success response body:
{
"name":"intProcVar",
"type":"integer",
"value":123,
"scope":"local"
}In case the variable is a binary variable or serializable, the valueUrl points to an URL to fetch the raw value. If it’s a plain variable, the value is present in the response. Note that only local scoped variables are returned, as there is no global scope for process-instance variables.
15.5.13. Create (or update) variables on a process instance
POST runtime/process-instances/{processInstanceId}/variables
PUT runtime/process-instances/{processInstanceId}/variables
When using POST, all variables that are passed are created. In case one of the variables already exists on the process instance, the request results in an error (409 - CONFLICT). When PUT is used, nonexistent variables are created on the process-instance and existing ones are overridden without any error.
| Parameter | Required | Value | Description |
|---|---|---|---|
processInstanceId |
Yes |
String |
The id of the process instance to the variables for. |
Request body:
[
{
"name":"intProcVar",
"type":"integer",
"value":123
},
...
]
Any number of variables can be passed into the request body array. More information about the variable format can be found in the REST variables section. Note that scope is ignored, only local variables can be set in a process instance.
| Response code | Description |
|---|---|
201 |
Indicates the process instance was found and variable is created. |
400 |
Indicates the request body is incomplete or contains illegal values. The status description contains additional information about the error. |
404 |
Indicates the requested process instance was not found. |
409 |
Indicates the process instance was found but already contains a variable with the given name (only thrown when POST method is used). Use the update-method instead. |
Success response body:
[
{
"name":"intProcVar",
"type":"integer",
"value":123,
"scope":"local"
},
...
]
15.5.14. Update a single variable on a process instance
PUT runtime/process-instances/{processInstanceId}/variables/{variableName}
| Parameter | Required | Value | Description |
|---|---|---|---|
processInstanceId |
Yes |
String |
The id of the process instance to the variables for. |
variableName |
Yes |
String |
Name of the variable to get. |
Request body:
{
"name":"intProcVar"
"type":"integer"
"value":123
}More information about the variable format can be found in the REST variables section. Note that scope is ignored, only local variables can be set in a process instance.
| Response code | Description |
|---|---|
200 |
Indicates both the process instance and variable were found and variable is updated. |
404 |
Indicates the requested process instance was not found or the process instance does not have a variable with the given name. Status description contains additional information about the error. |
Success response body:
{
"name":"intProcVar",
"type":"integer",
"value":123,
"scope":"local"
}In case the variable is a binary variable or serializable, the valueUrl points to an URL to fetch the raw value. If it’s a plain variable, the value is present in the response. Note that only local scoped variables are returned, as there is no global scope for process-instance variables.
15.5.15. Create a new binary variable on a process-instance
POST runtime/process-instances/{processInstanceId}/variables
| Parameter | Required | Value | Description |
|---|---|---|---|
processInstanceId |
Yes |
String |
The id of the process instance to create the new variable for. |
Request body:
The request should be of type multipart/form-data. There should be a single file-part included with the binary value of the variable. On top of that, the following additional form-fields can be present:
-
name: Required name of the variable. -
type: Type of variable that is created. If omitted,binaryis assumed and the binary data in the request will be stored as an array of bytes.
Success response body:
{
"name" : "binaryVariable",
"scope" : "local",
"type" : "binary",
"value" : null,
"valueUrl" : "http://.../runtime/process-instances/123/variables/binaryVariable/data"
}| Response code | Description |
|---|---|
201 |
Indicates the variable was created and the result is returned. |
400 |
Indicates the name of the variable to create was missing. Status message provides additional information. |
404 |
Indicates the requested process instance was not found. |
409 |
Indicates the process instance already has a variable with the given name. Use the PUT method to update the task variable instead. |
415 |
Indicates the serializable data contains an object for which no class is present in the JVM running the Flowable engine and therefore cannot be deserialized. |
15.5.16. Update an existing binary variable on a process-instance
PUT runtime/process-instances/{processInstanceId}/variables
| Parameter | Required | Value | Description |
|---|---|---|---|
processInstanceId |
Yes |
String |
The id of the process instance to create the new variable for. |
Request body:
The request should be of type multipart/form-data. There should be a single file-part included with the binary value of the variable. On top of that, the following additional form-fields can be present:
-
name: Required name of the variable. -
type: Type of variable that is created. If omitted,binaryis assumed and the binary data in the request will be stored as an array of bytes.
Success response body:
{
"name" : "binaryVariable",
"scope" : "local",
"type" : "binary",
"value" : null,
"valueUrl" : "http://.../runtime/process-instances/123/variables/binaryVariable/data"
}| Response code | Description |
|---|---|
200 |
Indicates the variable was updated and the result is returned. |
400 |
Indicates the name of the variable to update was missing. Status message provides additional information. |
404 |
Indicates the requested process instance was not found or the process instance does not have a variable with the given name. |
415 |
Indicates the serializable data contains an object for which no class is present in the JVM running the Flowable engine and therefore cannot be deserialized. |
15.6. Executions
15.6.1. Get an execution
GET runtime/executions/{executionId}
| Parameter | Required | Value | Description |
|---|---|---|---|
executionId |
Yes |
String |
The id of the execution to get. |
| Response code | Description |
|---|---|
200 |
Indicates the execution was found and returned. |
404 |
Indicates the execution was not found. |
Success response body:
{
"id":"5",
"url":"http://localhost:8182/runtime/executions/5",
"parentId":null,
"parentUrl":null,
"processInstanceId":"5",
"processInstanceUrl":"http://localhost:8182/runtime/process-instances/5",
"suspended":false,
"activityId":null,
"tenantId": null
}15.6.2. Execute an action on an execution
PUT runtime/executions/{executionId}
| Parameter | Required | Value | Description |
|---|---|---|---|
executionId |
Yes |
String |
The id of the execution to execute action on. |
Request body (signal an execution):
{
"action":"signal"
}Both a variables and transientVariables property is accepted with following structure:
{
"action":"signal",
"variables" : [
{
"name": "myVar",
"value": "someValue"
}
]
}Request body (signal event received for execution):
{
"action":"signalEventReceived",
"signalName":"mySignal"
"variables": [ ]
}Notifies the execution that a signal event has been received, requires a signalName parameter. Optional variables can be passed that are set on the execution before the action is executed.
Request body (signal event received for execution):
{
"action":"messageEventReceived",
"messageName":"myMessage"
"variables": [ ]
}Notifies the execution that a message event has been received, requires a messageName parameter. Optional variables can be passed that are set on the execution before the action is executed.
| Response code | Description |
|---|---|
200 |
Indicates the execution was found and the action is performed. |
204 |
Indicates the execution was found, the action was performed and the action caused the execution to end. |
400 |
Indicates an illegal action was requested, required parameters are missing in the request body or illegal variables are passed in. Status description contains additional information about the error. |
404 |
Indicates the execution was not found. |
Success response body (in case execution is not ended due to action):
{
"id":"5",
"url":"http://localhost:8182/runtime/executions/5",
"parentId":null,
"parentUrl":null,
"processInstanceId":"5",
"processInstanceUrl":"http://localhost:8182/runtime/process-instances/5",
"suspended":false,
"activityId":null,
"tenantId" : null
}15.6.3. Get active activities in an execution
GET runtime/executions/{executionId}/activities
Returns all activities which are active in the execution and in all child-executions (and their children, recursively), if any.
| Parameter | Required | Value | Description |
|---|---|---|---|
executionId |
Yes |
String |
The id of the execution to get activities for. |
| Response code | Description |
|---|---|
200 |
Indicates the execution was found and activities are returned. |
404 |
Indicates the execution was not found. |
Success response body:
[
"userTaskForManager",
"receiveTask"
]15.6.4. List of executions
GET runtime/executions
| Parameter | Required | Value | Description |
|---|---|---|---|
id |
No |
String |
Only return executions with the given id. |
activityId |
No |
String |
Only return executions with the given activity id. |
processDefinitionKey |
No |
String |
Only return executions with the given process definition key. |
processDefinitionId |
No |
String |
Only return executions with the given process definition id. |
processInstanceId |
No |
String |
Only return executions which are part of the process instance with the given id. |
messageEventSubscriptionName |
No |
String |
Only return executions which are subscribed to a message with the given name. |
signalEventSubscriptionName |
No |
String |
Only return executions which are subscribed to a signal with the given name. |
parentId |
No |
String |
Only return executions which are a direct child of the given execution. |
tenantId |
No |
String |
Only return executions with the given tenantId. |
tenantIdLike |
No |
String |
Only return executions with a tenantId like the given value. |
withoutTenantId |
No |
Boolean |
If |
sort |
No |
String |
Sort field, should be either one of |
| Response code | Description |
|---|---|
200 |
Indicates request was successful and the executions are returned |
400 |
Indicates a parameter was passed in the wrong format . The status-message contains additional information. |
Success response body:
{
"data":[
{
"id":"5",
"url":"http://localhost:8182/runtime/executions/5",
"parentId":null,
"parentUrl":null,
"processInstanceId":"5",
"processInstanceUrl":"http://localhost:8182/runtime/process-instances/5",
"suspended":false,
"activityId":null,
"tenantId":null
},
{
"id":"7",
"url":"http://localhost:8182/runtime/executions/7",
"parentId":"5",
"parentUrl":"http://localhost:8182/runtime/executions/5",
"processInstanceId":"5",
"processInstanceUrl":"http://localhost:8182/runtime/process-instances/5",
"suspended":false,
"activityId":"processTask",
"tenantId":null
}
],
"total":2,
"start":0,
"sort":"processInstanceId",
"order":"asc",
"size":2
}15.6.5. Query executions
POST query/executions
Request body:
{
"processDefinitionKey":"oneTaskProcess",
"variables":
[
{
"name" : "myVariable",
"value" : 1234,
"operation" : "equals",
"type" : "long"
}
],
"processInstanceVariables":
[
{
"name" : "processVariable",
"value" : "some string",
"operation" : "equals",
"type" : "string"
}
]
}The request body can contain all possible filters that can be used in the List executions URL query. On top of these, it’s possible to provide an array of variables and processInstanceVariables
to include in the query, with their format described here.
The general paging and sorting query-parameters can be used for this URL.
| Response code | Description |
|---|---|
200 |
Indicates request was successful and the executions are returned |
400 |
Indicates a parameter was passed in the wrong format . The status-message contains additional information. |
Success response body:
{
"data":[
{
"id":"5",
"url":"http://localhost:8182/runtime/executions/5",
"parentId":null,
"parentUrl":null,
"processInstanceId":"5",
"processInstanceUrl":"http://localhost:8182/runtime/process-instances/5",
"suspended":false,
"activityId":null,
"tenantId":null
},
{
"id":"7",
"url":"http://localhost:8182/runtime/executions/7",
"parentId":"5",
"parentUrl":"http://localhost:8182/runtime/executions/5",
"processInstanceId":"5",
"processInstanceUrl":"http://localhost:8182/runtime/process-instances/5",
"suspended":false,
"activityId":"processTask",
"tenantId":null
}
],
"total":2,
"start":0,
"sort":"processInstanceId",
"order":"asc",
"size":2
}15.6.6. List of variables for an execution
GET runtime/executions/{executionId}/variables?scope={scope}
| Parameter | Required | Value | Description |
|---|---|---|---|
executionId |
Yes |
String |
The id of the execution to the variables for. |
scope |
No |
String |
Either |
| Response code | Description |
|---|---|
200 |
Indicates the execution was found and variables are returned. |
404 |
Indicates the requested execution was not found. |
Success response body:
[
{
"name":"intProcVar",
"type":"integer",
"value":123,
"scope":"global"
},
{
"name":"byteArrayProcVar",
"type":"binary",
"value":null,
"valueUrl":"http://localhost:8182/runtime/process-instances/5/variables/byteArrayProcVar/data",
"scope":"local"
}
]In case the variable is a binary variable or serializable, the valueUrl points to an URL to fetch the raw value. If it’s a plain variable, the value is present in the response.
15.6.7. Get a variable for an execution
GET runtime/executions/{executionId}/variables/{variableName}?scope={scope}
| Parameter | Required | Value | Description |
|---|---|---|---|
executionId |
Yes |
String |
The id of the execution to the variables for. |
variableName |
Yes |
String |
Name of the variable to get. |
scope |
No |
String |
Either |
| Response code | Description |
|---|---|
200 |
Indicates both the execution and variable were found and variable is returned. |
400 |
Indicates the request body is incomplete or contains illegal values. The status description contains additional information about the error. |
404 |
Indicates the requested execution was not found or the execution does not have a variable with the given name in the requested scope (in case scope-query parameter was omitted, variable doesn’t exist in local and global scope). Status description contains additional information about the error. |
Success response body:
{
"name":"intProcVar",
"type":"integer",
"value":123,
"scope":"local"
}In case the variable is a binary variable or serializable, the valueUrl points to an URL to fetch the raw value. If it’s a plain variable, the value is present in the response.
15.6.8. Create (or update) variables on an execution
POST runtime/executions/{executionId}/variables
PUT runtime/executions/{executionId}/variables
When using POST, all variables that are passed are created. In case one of the variables already exists on the execution in the requested scope, the request results in an error (409 - CONFLICT). When PUT is used, nonexistent variables are created on the execution and existing ones are overridden without any error.
| Parameter | Required | Value | Description |
|---|---|---|---|
executionId |
Yes |
String |
The id of the execution to the variables for. |
Request body:
[
{
"name":"intProcVar"
"type":"integer"
"value":123,
"scope":"local"
}
]*Note that you can only provide variables that have the same scope. If the request-body array contains variables from mixed scopes, the request results in an error (400 - BAD REQUEST).*Any number of variables can be passed into the request body array. More information about the variable format can be found in the REST variables section. Note that scope is ignored, only local variables can be set in a process instance.
| Response code | Description |
|---|---|
201 |
Indicates the execution was found and variable is created. |
400 |
Indicates the request body is incomplete or contains illegal values. The status description contains additional information about the error. |
404 |
Indicates the requested execution was not found. |
409 |
Indicates the execution was found but already contains a variable with the given name (only thrown when POST method is used). Use the update-method instead. |
Success response body:
[
{
"name":"intProcVar",
"type":"integer",
"value":123,
"scope":"local"
}
]15.6.9. Update a variable on an execution
PUT runtime/executions/{executionId}/variables/{variableName}
| Parameter | Required | Value | Description |
|---|---|---|---|
executionId |
Yes |
String |
The id of the execution to update the variables for. |
variableName |
Yes |
String |
Name of the variable to update. |
Request body:
{
"name":"intProcVar"
"type":"integer"
"value":123,
"scope":"global"
}More information about the variable format can be found in the REST variables section.
| Response code | Description |
|---|---|
200 |
Indicates both the process instance and variable were found and variable is updated. |
404 |
Indicates the requested process instance was not found or the process instance does not have a variable with the given name. Status description contains additional information about the error. |
Success response body:
{
"name":"intProcVar",
"type":"integer",
"value":123,
"scope":"global"
}In case the variable is a binary variable or serializable, the valueUrl points to an URL to fetch the raw value. If it’s a plain variable, the value is present in the response.
15.6.10. Create a new binary variable on an execution
POST runtime/executions/{executionId}/variables
| Parameter | Required | Value | Description |
|---|---|---|---|
executionId |
Yes |
String |
The id of the execution to create the new variable for. |
Request body:
The request should be of type multipart/form-data. There should be a single file-part included with the binary value of the variable. On top of that, the following additional form-fields can be present:
-
name: Required name of the variable. -
type: Type of variable that is created. If omitted,binaryis assumed and the binary data in the request will be stored as an array of bytes. -
scope: Scope of variable that is created. If omitted,localis assumed.
Success response body:
{
"name" : "binaryVariable",
"scope" : "local",
"type" : "binary",
"value" : null,
"valueUrl" : "http://.../runtime/executions/123/variables/binaryVariable/data"
}| Response code | Description |
|---|---|
201 |
Indicates the variable was created and the result is returned. |
400 |
Indicates the name of the variable to create was missing. Status message provides additional information. |
404 |
Indicates the requested execution was not found. |
409 |
Indicates the execution already has a variable with the given name. Use the PUT method to update the task variable instead. |
415 |
Indicates the serializable data contains an object for which no class is present in the JVM running the Flowable engine and therefore cannot be deserialized. |
15.6.11. Update an existing binary variable on a process-instance
PUT runtime/executions/{executionId}/variables/{variableName}
| Parameter | Required | Value | Description |
|---|---|---|---|
executionId |
Yes |
String |
The id of the execution to create the new variable for. |
variableName |
Yes |
String |
The name of the variable to update. |
Request body:
The request should be of type multipart/form-data. There should be a single file-part included with the binary value of the variable. On top of that, the following additional form-fields can be present:
-
name: Required name of the variable. -
type: Type of variable that is created. If omitted,binaryis assumed and the binary data in the request will be stored as an array of bytes. -
scope: Scope of variable that is created. If omitted,localis assumed.
Success response body:
{
"name" : "binaryVariable",
"scope" : "local",
"type" : "binary",
"value" : null,
"valueUrl" : "http://.../runtime/executions/123/variables/binaryVariable/data"
}| Response code | Description |
|---|---|
200 |
Indicates the variable was updated and the result is returned. |
400 |
Indicates the name of the variable to update was missing. Status message provides additional information. |
404 |
Indicates the requested execution was not found or the execution does not have a variable with the given name. |
415 |
Indicates the serializable data contains an object for which no class is present in the JVM running the Flowable engine and therefore cannot be deserialized. |
15.7. Tasks
15.7.1. Get a task
GET runtime/tasks/{taskId}
| Parameter | Required | Value | Description |
|---|---|---|---|
taskId |
Yes |
String |
The id of the task to get. |
| Response code | Description |
|---|---|
200 |
Indicates the task was found and returned. |
404 |
Indicates the requested task was not found. |
Success response body:
{
"assignee" : "kermit",
"createTime" : "2013-04-17T10:17:43.902+0000",
"delegationState" : "pending",
"description" : "Task description",
"dueDate" : "2013-04-17T10:17:43.902+0000",
"execution" : "http://localhost:8182/runtime/executions/5",
"id" : "8",
"name" : "My task",
"owner" : "owner",
"parentTask" : "http://localhost:8182/runtime/tasks/9",
"priority" : 50,
"processDefinition" : "http://localhost:8182/repository/process-definitions/oneTaskProcess%3A1%3A4",
"processInstance" : "http://localhost:8182/runtime/process-instances/5",
"suspended" : false,
"taskDefinitionKey" : "theTask",
"url" : "http://localhost:8182/runtime/tasks/8",
"tenantId" : null
}-
delegationState: Delegation-state of the task, can benull,"pending"or"resolved".
15.7.2. List of tasks
GET runtime/tasks
| Parameter | Required | Value | Description |
|---|---|---|---|
name |
No |
String |
Only return tasks with the given name. |
nameLike |
No |
String |
Only return tasks with a name like the given name. |
description |
No |
String |
Only return tasks with the given description. |
priority |
No |
Integer |
Only return tasks with the given priority. |
minimumPriority |
No |
Integer |
Only return tasks with a priority greater than the given value. |
maximumPriority |
No |
Integer |
Only return tasks with a priority lower than the given value. |
assignee |
No |
String |
Only return tasks assigned to the given user. |
assigneeLike |
No |
String |
Only return tasks assigned with an assignee like the given value. |
owner |
No |
String |
Only return tasks owned by the given user. |
ownerLike |
No |
String |
Only return tasks assigned with an owner like the given value. |
unassigned |
No |
Boolean |
Only return tasks that are not assigned to anyone. If |
delegationState |
No |
String |
Only return tasks that have the given delegation state. Possible values are |
candidateUser |
No |
String |
Only return tasks that can be claimed by the given user. This includes both tasks where the user is an explicit candidate for and task that are claimable by a group that the user is a member of. |
candidateGroup |
No |
String |
Only return tasks that can be claimed by a user in the given group. |
candidateGroups |
No |
String |
Only return tasks that can be claimed by a user in the given groups. Values split by comma. |
involvedUser |
No |
String |
Only return tasks in which the given user is involved. |
taskDefinitionKey |
No |
String |
Only return tasks with the given task definition id. |
taskDefinitionKeyLike |
No |
String |
Only return tasks with a given task definition id like the given value. |
processInstanceId |
No |
String |
Only return tasks which are part of the process instance with the given id. |
processInstanceBusinessKey |
No |
String |
Only return tasks which are part of the process instance with the given business key. |
processInstanceBusinessKeyLike |
No |
String |
Only return tasks which are part of the process instance which has a business key like the given value. |
processDefinitionId |
No |
String |
Only return tasks which are part of a process instance which has a process definition with the given id. |
processDefinitionKey |
No |
String |
Only return tasks which are part of a process instance which has a process definition with the given key. |
processDefinitionKeyLike |
No |
String |
Only return tasks which are part of a process instance which has a process definition with a key like the given value. |
processDefinitionName |
No |
String |
Only return tasks which are part of a process instance which has a process definition with the given name. |
processDefinitionNameLike |
No |
String |
Only return tasks which are part of a process instance which has a process definition with a name like the given value. |
executionId |
No |
String |
Only return tasks which are part of the execution with the given id. |
createdOn |
No |
ISO Date |
Only return tasks which are created on the given date. |
createdBefore |
No |
ISO Date |
Only return tasks which are created before the given date. |
createdAfter |
No |
ISO Date |
Only return tasks which are created after the given date. |
dueOn |
No |
ISO Date |
Only return tasks which are due on the given date. |
dueBefore |
No |
ISO Date |
Only return tasks which are due before the given date. |
dueAfter |
No |
ISO Date |
Only return tasks which are due after the given date. |
withoutDueDate |
No |
boolean |
Only return tasks which don’t have a due date. The property is ignored if the value is |
excludeSubTasks |
No |
Boolean |
Only return tasks that are not a subtask of another task. |
active |
No |
Boolean |
If |
includeTaskLocalVariables |
No |
Boolean |
Indication to include task local variables in the result. |
includeProcessVariables |
No |
Boolean |
Indication to include process variables in the result. |
tenantId |
No |
String |
Only return tasks with the given tenantId. |
tenantIdLike |
No |
String |
Only return tasks with a tenantId like the given value. |
withoutTenantId |
No |
Boolean |
If |
candidateOrAssigned |
No |
String |
Select tasks that has been claimed or assigned to user or waiting to claim by user (candidate user or groups). |
category |
No |
string |
Select tasks with the given category. Note that this is the task category, not the category of the process definition (namespace within the BPMN Xml). |
| Response code | Description |
|---|---|
200 |
Indicates request was successful and the tasks are returned |
400 |
Indicates a parameter was passed in the wrong format or that delegationState has an invalid value (other than pending and resolved). The status-message contains additional information. |
Success response body:
{
"data": [
{
"assignee" : "kermit",
"createTime" : "2013-04-17T10:17:43.902+0000",
"delegationState" : "pending",
"description" : "Task description",
"dueDate" : "2013-04-17T10:17:43.902+0000",
"execution" : "http://localhost:8182/runtime/executions/5",
"id" : "8",
"name" : "My task",
"owner" : "owner",
"parentTask" : "http://localhost:8182/runtime/tasks/9",
"priority" : 50,
"processDefinition" : "http://localhost:8182/repository/process-definitions/oneTaskProcess%3A1%3A4",
"processInstance" : "http://localhost:8182/runtime/process-instances/5",
"suspended" : false,
"taskDefinitionKey" : "theTask",
"url" : "http://localhost:8182/runtime/tasks/8",
"tenantId" : null
}
],
"total": 1,
"start": 0,
"sort": "name",
"order": "asc",
"size": 1
}15.7.3. Query for tasks
POST query/tasks
Request body:
{
"name" : "My task",
"description" : "The task description",
...
"taskVariables" : [
{
"name" : "myVariable",
"value" : 1234,
"operation" : "equals",
"type" : "long"
}
],
"processInstanceVariables" : [
{
...
}
]
]
}All supported JSON parameter fields allowed are exactly the same as the parameters found for getting a collection of tasks (except for candidateGroupIn which is only available in this POST task query REST service), but passed in as JSON-body arguments rather than URL-parameters to allow for more advanced querying and preventing errors with request-uri’s that are too long. On top of that, the query allows for filtering based on task and process variables. The taskVariables and processInstanceVariables are both JSON-arrays containing objects with the format as described here.
| Response code | Description |
|---|---|
200 |
Indicates request was successful and the tasks are returned |
400 |
Indicates a parameter was passed in the wrong format or that delegationState has an invalid value (other than pending and resolved). The status-message contains additional information. |
Success response body:
{
"data": [
{
"assignee" : "kermit",
"createTime" : "2013-04-17T10:17:43.902+0000",
"delegationState" : "pending",
"description" : "Task description",
"dueDate" : "2013-04-17T10:17:43.902+0000",
"execution" : "http://localhost:8182/runtime/executions/5",
"id" : "8",
"name" : "My task",
"owner" : "owner",
"parentTask" : "http://localhost:8182/runtime/tasks/9",
"priority" : 50,
"processDefinition" : "http://localhost:8182/repository/process-definitions/oneTaskProcess%3A1%3A4",
"processInstance" : "http://localhost:8182/runtime/process-instances/5",
"suspended" : false,
"taskDefinitionKey" : "theTask",
"url" : "http://localhost:8182/runtime/tasks/8",
"tenantId" : null
}
],
"total": 1,
"start": 0,
"sort": "name",
"order": "asc",
"size": 1
}15.7.4. Update a task
PUT runtime/tasks/{taskId}
Body JSON:
{
"assignee" : "assignee",
"delegationState" : "resolved",
"description" : "New task description",
"dueDate" : "2013-04-17T13:06:02.438+02:00",
"name" : "New task name",
"owner" : "owner",
"parentTaskId" : "3",
"priority" : 20
}All request values are optional. For example, you can only include the assignee attribute in the request body JSON-object, only updating the assignee of the task, leaving all other fields unaffected. When an attribute is explicitly included and is set to null, the task-value will be updated to null. Example: {"dueDate" : null} will clear the duedate of the task).
| Response code | Description |
|---|---|
200 |
Indicates the task was updated. |
404 |
Indicates the requested task was not found. |
409 |
Indicates the requested task was updated simultaneously. |
Success response body: see response for runtime/tasks/{taskId}.
15.7.5. Task actions
POST runtime/tasks/{taskId}
Complete a task - Body JSON:
{
"action" : "complete",
"variables" : []
}Completes the task. Optional variable array can be passed in using the variables property. More information about the variable format can be found in the REST variables section. Note that the variable-scope is applied. If scope isn’t indicated, variables are set to the parent-scope and if indicated, variables are set to the scope that is provided.
Note that also a transientVariables property is accepted as part of this json, that follows the same structure as the variables property.
Claim a task - Body JSON:
{
"action" : "claim",
"assignee" : "userWhoClaims"
}Claims the task by the given assignee. If the assignee is null, the task is assigned to no-one, claimable again.
Delegate a task - Body JSON:
{
"action" : "delegate",
"assignee" : "userToDelegateTo"
}Delegates the task to the given assignee. The assignee is required.
Resolve a task - Body JSON:
{
"action" : "resolve"
}Resolves the task delegation. The task is assigned back to the task owner (if any).
| Response code | Description |
|---|---|
200 |
Indicates the action was executed. |
400 |
When the body contains an invalid value or when the assignee is missing when the action requires it. |
404 |
Indicates the requested task was not found. |
409 |
Indicates the action cannot be performed due to a conflict. Either the task was updates simultaneously or the task was claimed by another user, in case of the |
Success response body: see response for runtime/tasks/{taskId}.
15.7.6. Delete a task
DELETE runtime/tasks/{taskId}?cascadeHistory={cascadeHistory}&deleteReason={deleteReason}
| Parameter | Required | Value | Description |
|---|---|---|---|
taskId |
Yes |
String |
The id of the task to delete. |
cascadeHistory |
False |
Boolean |
Whether or not to delete the HistoricTask instance when deleting the task (if applicable). If not provided, this value defaults to false. |
deleteReason |
False |
String |
Reason why the task is deleted. This value is ignored when |
| Response code | Description |
|---|---|
204 |
Indicates the task was found and has been deleted. Response-body is intentionally empty. |
403 |
Indicates the requested task cannot be deleted because it’s part of a workflow. |
404 |
Indicates the requested task was not found. |
15.7.7. Get all variables for a task
GET runtime/tasks/{taskId}/variables?scope={scope}
| Parameter | Required | Value | Description |
|---|---|---|---|
taskId |
Yes |
String |
The id of the task to get variables for. |
scope |
False |
String |
Scope of variables to be returned. When |
| Response code | Description |
|---|---|
200 |
Indicates the task was found and the requested variables are returned. |
404 |
Indicates the requested task was not found. |
Success response body:
[
{
"name" : "doubleTaskVar",
"scope" : "local",
"type" : "double",
"value" : 99.99
},
{
"name" : "stringProcVar",
"scope" : "global",
"type" : "string",
"value" : "This is a ProcVariable"
}
]The variables are returned as a JSON array. Full response description can be found in the general REST-variables section.
15.7.8. Get a variable from a task
GET runtime/tasks/{taskId}/variables/{variableName}?scope={scope}
| Parameter | Required | Value | Description |
|---|---|---|---|
taskId |
Yes |
String |
The id of the task to get a variable for. |
variableName |
Yes |
String |
The name of the variable to get. |
scope |
False |
String |
Scope of variable to be returned. When |
| Response code | Description |
|---|---|
200 |
Indicates the task was found and the requested variables are returned. |
404 |
Indicates the requested task was not found or the task doesn’t have a variable with the given name (in the given scope). Status message provides additional information. |
Success response body:
{
"name" : "myTaskVariable",
"scope" : "local",
"type" : "string",
"value" : "Hello my friend"
}Full response body description can be found in the general REST-variables section.
15.7.9. Get the binary data for a variable
GET runtime/tasks/{taskId}/variables/{variableName}/data?scope={scope}
| Parameter | Required | Value | Description |
|---|---|---|---|
taskId |
Yes |
String |
The id of the task to get a variable data for. |
variableName |
Yes |
String |
The name of the variable to get data for. Only variables of type |
scope |
False |
String |
Scope of variable to be returned. When |
| Response code | Description |
|---|---|
200 |
Indicates the task was found and the requested variables are returned. |
404 |
Indicates the requested task was not found or the task doesn’t have a variable with the given name (in the given scope) or the variable doesn’t have a binary stream available. Status message provides additional information. |
Success response body:
The response body contains the binary value of the variable. When the variable is of type binary, the content-type of the response is set to application/octet-stream, regardless of the content of the variable or the request accept-type header. In case of serializable, application/x-java-serialized-object is used as content-type.
15.7.10. Create new variables on a task
POST runtime/tasks/{taskId}/variables
| Parameter | Required | Value | Description |
|---|---|---|---|
taskId |
Yes |
String |
The id of the task to create the new variable for. |
Request body for creating simple (non-binary) variables:
[
{
"name" : "myTaskVariable",
"scope" : "local",
"type" : "string",
"value" : "Hello my friend"
},
{
}
]The request body should be an array containing one or more JSON-objects representing the variables that should be created.
-
name: Required name of the variable -
scope: Scope of variable that is created. If omitted,localis assumed. -
type: Type of variable that is created. If omitted, reverts to raw JSON-value type (string, boolean, integer or double). -
value: Variable value.
More information about the variable format can be found in the REST variables section.
Success response body:
[
{
"name" : "myTaskVariable",
"scope" : "local",
"type" : "string",
"value" : "Hello my friend"
},
{
}
]| Response code | Description |
|---|---|
201 |
Indicates the variables were created and the result is returned. |
400 |
Indicates the name of a variable to create was missing or that an attempt is done to create a variable on a standalone task (without a process associated) with scope |
404 |
Indicates the requested task was not found. |
409 |
Indicates the task already has a variable with the given name. Use the PUT method to update the task variable instead. |
15.7.11. Create a new binary variable on a task
POST runtime/tasks/{taskId}/variables
| Parameter | Required | Value | Description |
|---|---|---|---|
taskId |
Yes |
String |
The id of the task to create the new variable for. |
Request body:
The request should be of type multipart/form-data. There should be a single file-part included with the binary value of the variable. On top of that, the following additional form-fields can be present:
-
name: Required name of the variable. -
scope: Scope of variable that is created. If omitted,localis assumed. -
type: Type of variable that is created. If omitted,binaryis assumed and the binary data in the request will be stored as an array of bytes.
Success response body:
{
"name" : "binaryVariable",
"scope" : "local",
"type" : "binary",
"value" : null,
"valueUrl" : "http://.../runtime/tasks/123/variables/binaryVariable/data"
}| Response code | Description |
|---|---|
201 |
Indicates the variable was created and the result is returned. |
400 |
Indicates the name of the variable to create was missing or that an attempt is done to create a variable on a standalone task (without a process associated) with scope |
404 |
Indicates the requested task was not found. |
409 |
Indicates the task already has a variable with the given name. Use the PUT method to update the task variable instead. |
415 |
Indicates the serializable data contains an object for which no class is present in the JVM running the Flowable engine and therefore cannot be deserialized. |
15.7.12. Update an existing variable on a task
PUT runtime/tasks/{taskId}/variables/{variableName}
| Parameter | Required | Value | Description |
|---|---|---|---|
taskId |
Yes |
String |
The id of the task to update the variable for. |
variableName |
Yes |
String |
The name of the variable to update. |
Request body for updating simple (non-binary) variables:
{
"name" : "myTaskVariable",
"scope" : "local",
"type" : "string",
"value" : "Hello my friend"
}-
name: Required name of the variable -
scope: Scope of variable that is updated. If omitted,localis assumed. -
type: Type of variable that is updated. If omitted, reverts to raw JSON-value type (string, boolean, integer or double). -
value: Variable value.
More information about the variable format can be found in the REST variables section.
Success response body:
{
"name" : "myTaskVariable",
"scope" : "local",
"type" : "string",
"value" : "Hello my friend"
}| Response code | Description |
|---|---|
200 |
Indicates the variables was updated and the result is returned. |
400 |
Indicates the name of a variable to update was missing or that an attempt is done to update a variable on a standalone task (without a process associated) with scope |
404 |
Indicates the requested task was not found or the task doesn’t have a variable with the given name in the given scope. Status message contains additional information about the error. |
15.7.13. Updating a binary variable on a task
PUT runtime/tasks/{taskId}/variables/{variableName}
| Parameter | Required | Value | Description |
|---|---|---|---|
taskId |
Yes |
String |
The id of the task to update the variable for. |
variableName |
Yes |
String |
The name of the variable to update. |
Request body:
The request should be of type multipart/form-data. There should be a single file-part included with the binary value of the variable. On top of that, the following additional form-fields can be present:
-
name: Required name of the variable. -
scope: Scope of variable that is updated. If omitted,localis assumed. -
type: Type of variable that is updated. If omitted,binaryis assumed and the binary data in the request will be stored as an array of bytes.
Success response body:
{
"name" : "binaryVariable",
"scope" : "local",
"type" : "binary",
"value" : null,
"valueUrl" : "http://.../runtime/tasks/123/variables/binaryVariable/data"
}| Response code | Description |
|---|---|
200 |
Indicates the variable was updated and the result is returned. |
400 |
Indicates the name of the variable to update was missing or that an attempt is done to update a variable on a standalone task (without a process associated) with scope |
404 |
Indicates the requested task was not found or the variable to update doesn’t exist for the given task in the given scope. |
415 |
Indicates the serializable data contains an object for which no class is present in the JVM running the Flowable engine and therefore cannot be deserialized. |
15.7.14. Delete a variable on a task
DELETE runtime/tasks/{taskId}/variables/{variableName}?scope={scope}
| Parameter | Required | Value | Description |
|---|---|---|---|
taskId |
Yes |
String |
The id of the task the variable to delete belongs to. |
variableName |
Yes |
String |
The name of the variable to delete. |
scope |
No |
String |
Scope of variable to delete in. Can be either |
| Response code | Description |
|---|---|
204 |
Indicates the task variable was found and has been deleted. Response-body is intentionally empty. |
404 |
Indicates the requested task was not found or the task doesn’t have a variable with the given name. Status message contains additional information about the error. |
15.7.15. Delete all local variables on a task
DELETE runtime/tasks/{taskId}/variables
| Parameter | Required | Value | Description |
|---|---|---|---|
taskId |
Yes |
String |
The id of the task the variable to delete belongs to. |
| Response code | Description |
|---|---|
204 |
Indicates all local task variables have been deleted. Response-body is intentionally empty. |
404 |
Indicates the requested task was not found. |
15.7.16. Get all identity links for a task
GET runtime/tasks/{taskId}/identitylinks
| Parameter | Required | Value | Description |
|---|---|---|---|
taskId |
Yes |
String |
The id of the task to get the identity links for. |
| Response code | Description |
|---|---|
200 |
Indicates the task was found and the requested identity links are returned. |
404 |
Indicates the requested task was not found. |
Success response body:
[
{
"userId" : "kermit",
"groupId" : null,
"type" : "candidate",
"url" : "http://localhost:8081/flowable-rest/service/runtime/tasks/100/identitylinks/users/kermit/candidate"
},
{
"userId" : null,
"groupId" : "sales",
"type" : "candidate",
"url" : "http://localhost:8081/flowable-rest/service/runtime/tasks/100/identitylinks/groups/sales/candidate"
},
...
]15.7.17. Get all identitylinks for a task for either groups or users
GET runtime/tasks/{taskId}/identitylinks/users
GET runtime/tasks/{taskId}/identitylinks/groups
Returns only identity links targeting either users or groups. Response body and status-codes are exactly the same as when getting the full list of identity links for a task.
15.7.18. Get a single identity link on a task
GET runtime/tasks/{taskId}/identitylinks/{family}/{identityId}/{type}
| Parameter | Required | Value | Description |
|---|---|---|---|
taskId |
Yes |
String |
The id of the task . |
family |
Yes |
String |
Either |
identityId |
Yes |
String |
The id of the identity. |
type |
Yes |
String |
The type of identity link. |
| Response code | Description |
|---|---|
200 |
Indicates the task and identity link was found and returned. |
404 |
Indicates the requested task was not found or the task doesn’t have the requested identityLink. The status contains additional information about this error. |
Success response body:
{
"userId" : null,
"groupId" : "sales",
"type" : "candidate",
"url" : "http://localhost:8081/flowable-rest/service/runtime/tasks/100/identitylinks/groups/sales/candidate"
}15.7.19. Create an identity link on a task
POST runtime/tasks/{taskId}/identitylinks
| Parameter | Required | Value | Description |
|---|---|---|---|
taskId |
Yes |
String |
The id of the task . |
Request body (user):
{
"userId" : "kermit",
"type" : "candidate",
}Request body (group):
{
"groupId" : "sales",
"type" : "candidate",
}| Response code | Description |
|---|---|
201 |
Indicates the task was found and the identity link was created. |
404 |
Indicates the requested task was not found or the task doesn’t have the requested identityLink. The status contains additional information about this error. |
Success response body:
{
"userId" : null,
"groupId" : "sales",
"type" : "candidate",
"url" : "http://localhost:8081/flowable-rest/service/runtime/tasks/100/identitylinks/groups/sales/candidate"
}15.7.20. Delete an identity link on a task
DELETE runtime/tasks/{taskId}/identitylinks/{family}/{identityId}/{type}
| Parameter | Required | Value | Description |
|---|---|---|---|
taskId |
Yes |
String |
The id of the task. |
family |
Yes |
String |
Either |
identityId |
Yes |
String |
The id of the identity. |
type |
Yes |
String |
The type of identity link. |
| Response code | Description |
|---|---|
204 |
Indicates the task and identity link were found and the link has been deleted. Response-body is intentionally empty. |
404 |
Indicates the requested task was not found or the task doesn’t have the requested identityLink. The status contains additional information about this error. |
15.7.21. Create a new comment on a task
POST runtime/tasks/{taskId}/comments
| Parameter | Required | Value | Description |
|---|---|---|---|
taskId |
Yes |
String |
The id of the task to create the comment for. |
Request body:
{
"message" : "This is a comment on the task.",
"saveProcessInstanceId" : true
}Parameter saveProcessInstanceId is optional, if true save process instance id of task with comment.
Success response body:
{
"id" : "123",
"taskUrl" : "http://localhost:8081/flowable-rest/service/runtime/tasks/101/comments/123",
"processInstanceUrl" : "http://localhost:8081/flowable-rest/service/history/historic-process-instances/100/comments/123",
"message" : "This is a comment on the task.",
"author" : "kermit",
"time" : "2014-07-13T13:13:52.232+08:00"
"taskId" : "101",
"processInstanceId" : "100"
}| Response code | Description |
|---|---|
201 |
Indicates the comment was created and the result is returned. |
400 |
Indicates the comment is missing from the request. |
404 |
Indicates the requested task was not found. |
15.7.22. Get all comments on a task
GET runtime/tasks/{taskId}/comments
| Parameter | Required | Value | Description |
|---|---|---|---|
taskId |
Yes |
String |
The id of the task to get the comments for. |
Success response body:
[
{
"id" : "123",
"taskUrl" : "http://localhost:8081/flowable-rest/service/runtime/tasks/101/comments/123",
"processInstanceUrl" : "http://localhost:8081/flowable-rest/service/history/historic-process-instances/100/comments/123",
"message" : "This is a comment on the task.",
"author" : "kermit"
"time" : "2014-07-13T13:13:52.232+08:00"
"taskId" : "101",
"processInstanceId" : "100"
},
{
"id" : "456",
"taskUrl" : "http://localhost:8081/flowable-rest/service/runtime/tasks/101/comments/456",
"processInstanceUrl" : "http://localhost:8081/flowable-rest/service/history/historic-process-instances/100/comments/456",
"message" : "This is another comment on the task.",
"author" : "gonzo",
"time" : "2014-07-13T13:13:52.232+08:00"
"taskId" : "101",
"processInstanceId" : "100"
}
]| Response code | Description |
|---|---|
200 |
Indicates the task was found and the comments are returned. |
404 |
Indicates the requested task was not found. |
15.7.23. Get a comment on a task
GET runtime/tasks/{taskId}/comments/{commentId}
| Parameter | Required | Value | Description |
|---|---|---|---|
taskId |
Yes |
String |
The id of the task to get the comment for. |
commentId |
Yes |
String |
The id of the comment. |
Success response body:
{
"id" : "123",
"taskUrl" : "http://localhost:8081/flowable-rest/service/runtime/tasks/101/comments/123",
"processInstanceUrl" : "http://localhost:8081/flowable-rest/service/history/historic-process-instances/100/comments/123",
"message" : "This is a comment on the task.",
"author" : "kermit",
"time" : "2014-07-13T13:13:52.232+08:00"
"taskId" : "101",
"processInstanceId" : "100"
}| Response code | Description |
|---|---|
200 |
Indicates the task and comment were found and the comment is returned. |
404 |
Indicates the requested task was not found or the tasks doesn’t have a comment with the given ID. |
15.7.24. Delete a comment on a task
DELETE runtime/tasks/{taskId}/comments/{commentId}
| Parameter | Required | Value | Description |
|---|---|---|---|
taskId |
Yes |
String |
The id of the task to delete the comment for. |
commentId |
Yes |
String |
The id of the comment. |
| Response code | Description |
|---|---|
204 |
Indicates the task and comment were found and the comment is deleted. Response body is left empty intentionally. |
404 |
Indicates the requested task was not found or the tasks doesn’t have a comment with the given ID. |
15.7.25. Get all events for a task
GET runtime/tasks/{taskId}/events
| Parameter | Required | Value | Description |
|---|---|---|---|
taskId |
Yes |
String |
The id of the task to get the events for. |
Success response body:
[
{
"action" : "AddUserLink",
"id" : "4",
"message" : [ "gonzo", "contributor" ],
"taskUrl" : "http://localhost:8182/runtime/tasks/2",
"time" : "2013-05-17T11:50:50.000+0000",
"url" : "http://localhost:8182/runtime/tasks/2/events/4",
"userId" : null
}
]| Response code | Description |
|---|---|
200 |
Indicates the task was found and the events are returned. |
404 |
Indicates the requested task was not found. |
15.7.26. Get an event on a task
GET runtime/tasks/{taskId}/events/{eventId}
| Parameter | Required | Value | Description |
|---|---|---|---|
taskId |
Yes |
String |
The id of the task to get the event for. |
eventId |
Yes |
String |
The id of the event. |
Success response body:
{
"action" : "AddUserLink",
"id" : "4",
"message" : [ "gonzo", "contributor" ],
"taskUrl" : "http://localhost:8182/runtime/tasks/2",
"time" : "2013-05-17T11:50:50.000+0000",
"url" : "http://localhost:8182/runtime/tasks/2/events/4",
"userId" : null
}| Response code | Description |
|---|---|
200 |
Indicates the task and event were found and the event is returned. |
404 |
Indicates the requested task was not found or the tasks doesn’t have an event with the given ID. |
15.7.27. Create a new attachment on a task, containing a link to an external resource
POST runtime/tasks/{taskId}/attachments
| Parameter | Required | Value | Description |
|---|---|---|---|
taskId |
Yes |
String |
The id of the task to create the attachment for. |
Request body:
{
"name":"Simple attachment",
"description":"Simple attachment description",
"type":"simpleType",
"externalUrl":"http://flowable.org"
}Only the attachment name is required to create a new attachment.
Success response body:
{
"id":"3",
"url":"http://localhost:8182/runtime/tasks/2/attachments/3",
"name":"Simple attachment",
"description":"Simple attachment description",
"type":"simpleType",
"taskUrl":"http://localhost:8182/runtime/tasks/2",
"processInstanceUrl":null,
"externalUrl":"http://flowable.org",
"contentUrl":null
}| Response code | Description |
|---|---|
201 |
Indicates the attachment was created and the result is returned. |
400 |
Indicates the attachment name is missing from the request. |
404 |
Indicates the requested task was not found. |
15.7.28. Create a new attachment on a task, with an attached file
POST runtime/tasks/{taskId}/attachments
| Parameter | Required | Value | Description |
|---|---|---|---|
taskId |
Yes |
String |
The id of the task to create the attachment for. |
Request body:
The request should be of type multipart/form-data. There should be a single file-part included with the binary value of the variable. On top of that, the following additional form-fields can be present:
-
name: Required name of the variable. -
description: Description of the attachment, optional. -
type: Type of attachment, optional. Supports any arbitrary string or a valid HTTP content-type.
Success response body:
{
"id":"5",
"url":"http://localhost:8182/runtime/tasks/2/attachments/5",
"name":"Binary attachment",
"description":"Binary attachment description",
"type":"binaryType",
"taskUrl":"http://localhost:8182/runtime/tasks/2",
"processInstanceUrl":null,
"externalUrl":null,
"contentUrl":"http://localhost:8182/runtime/tasks/2/attachments/5/content"
}| Response code | Description |
|---|---|
201 |
Indicates the attachment was created and the result is returned. |
400 |
Indicates the attachment name is missing from the request or no file was present in the request. The error-message contains additional information. |
404 |
Indicates the requested task was not found. |
15.7.29. Get all attachments on a task
GET runtime/tasks/{taskId}/attachments
| Parameter | Required | Value | Description |
|---|---|---|---|
taskId |
Yes |
String |
The id of the task to get the attachments for. |
Success response body:
[
{
"id":"3",
"url":"http://localhost:8182/runtime/tasks/2/attachments/3",
"name":"Simple attachment",
"description":"Simple attachment description",
"type":"simpleType",
"taskUrl":"http://localhost:8182/runtime/tasks/2",
"processInstanceUrl":null,
"externalUrl":"http://flowable.org",
"contentUrl":null
},
{
"id":"5",
"url":"http://localhost:8182/runtime/tasks/2/attachments/5",
"name":"Binary attachment",
"description":"Binary attachment description",
"type":"binaryType",
"taskUrl":"http://localhost:8182/runtime/tasks/2",
"processInstanceUrl":null,
"externalUrl":null,
"contentUrl":"http://localhost:8182/runtime/tasks/2/attachments/5/content"
}
]| Response code | Description |
|---|---|
200 |
Indicates the task was found and the attachments are returned. |
404 |
Indicates the requested task was not found. |
15.7.30. Get an attachment on a task
GET runtime/tasks/{taskId}/attachments/{attachmentId}
| Parameter | Required | Value | Description |
|---|---|---|---|
taskId |
Yes |
String |
The id of the task to get the attachment for. |
attachmentId |
Yes |
String |
The id of the attachment. |
Success response body:
{
"id":"5",
"url":"http://localhost:8182/runtime/tasks/2/attachments/5",
"name":"Binary attachment",
"description":"Binary attachment description",
"type":"binaryType",
"taskUrl":"http://localhost:8182/runtime/tasks/2",
"processInstanceUrl":null,
"externalUrl":null,
"contentUrl":"http://localhost:8182/runtime/tasks/2/attachments/5/content"
}-
externalUrl - contentUrl:In case the attachment is a link to an external resource, theexternalUrlcontains the URL to the external content. If the attachment content is present in the Flowable engine, thecontentUrlwill contain an URL where the binary content can be streamed from. -
type:Can be any arbitrary value. When a valid formatted media-type (e.g. application/xml, text/plain) is included, the binary content HTTP response content-type will be set the given value.
| Response code | Description |
|---|---|
200 |
Indicates the task and attachment were found and the attachment is returned. |
404 |
Indicates the requested task was not found or the tasks doesn’t have a attachment with the given ID. |
15.7.31. Get the content for an attachment
GET runtime/tasks/{taskId}/attachment/{attachmentId}/content
| Parameter | Required | Value | Description |
|---|---|---|---|
taskId |
Yes |
String |
The id of the task to get a variable data for. |
attachmentId |
Yes |
String |
The id of the attachment, a |
| Response code | Description |
|---|---|
200 |
Indicates the task and attachment was found and the requested content is returned. |
404 |
Indicates the requested task was not found or the task doesn’t have an attachment with the given id or the attachment doesn’t have a binary stream available. Status message provides additional information. |
Success response body:
The response body contains the binary content. By default, the content-type of the response is set to application/octet-stream unless the attachment type contains a valid Content-type.
15.7.32. Delete an attachment on a task
DELETE runtime/tasks/{taskId}/attachments/{attachmentId}
| Parameter | Required | Value | Description |
|---|---|---|---|
taskId |
Yes |
String |
The id of the task to delete the attachment for. |
attachmentId |
Yes |
String |
The id of the attachment. |
| Response code | Description |
|---|---|
204 |
Indicates the task and attachment were found and the attachment is deleted. Response body is left empty intentionally. |
404 |
Indicates the requested task was not found or the tasks doesn’t have a attachment with the given ID. |
15.8. History
15.8.1. Get a historic process instance
GET history/historic-process-instances/{processInstanceId}
| Response code | Description |
|---|---|
200 |
Indicates that the historic process instances could be found. |
404 |
Indicates that the historic process instances could not be found. |
Success response body:
{
"data": [
{
"id" : "5",
"businessKey" : "myKey",
"processDefinitionId" : "oneTaskProcess%3A1%3A4",
"processDefinitionUrl" : "http://localhost:8182/repository/process-definitions/oneTaskProcess%3A1%3A4",
"startTime" : "2013-04-17T10:17:43.902+0000",
"endTime" : "2013-04-18T14:06:32.715+0000",
"durationInMillis" : 86400056,
"startUserId" : "kermit",
"startActivityId" : "startEvent",
"endActivityId" : "endEvent",
"deleteReason" : null,
"superProcessInstanceId" : "3",
"url" : "http://localhost:8182/history/historic-process-instances/5",
"variables": null,
"tenantId":null
}
],
"total": 1,
"start": 0,
"sort": "name",
"order": "asc",
"size": 1
}15.8.2. List of historic process instances
GET history/historic-process-instances
| Parameter | Required | Value | Description |
|---|---|---|---|
processInstanceId |
No |
String |
An id of the historic process instance. |
processDefinitionKey |
No |
String |
The process definition key of the historic process instance. |
processDefinitionId |
No |
String |
The process definition id of the historic process instance. |
businessKey |
No |
String |
The business key of the historic process instance. |
involvedUser |
No |
String |
An involved user of the historic process instance. |
finished |
No |
Boolean |
Indication if the historic process instance is finished. |
superProcessInstanceId |
No |
String |
An optional parent process id of the historic process instance. |
excludeSubprocesses |
No |
Boolean |
Return only historic process instances which aren’t sub processes. |
finishedAfter |
No |
Date |
Return only historic process instances that were finished after this date. |
finishedBefore |
No |
Date |
Return only historic process instances that were finished before this date. |
startedAfter |
No |
Date |
Return only historic process instances that were started after this date. |
startedBefore |
No |
Date |
Return only historic process instances that were started before this date. |
startedBy |
No |
String |
Return only historic process instances that were started by this user. |
includeProcessVariables |
No |
Boolean |
An indication if the historic process instance variables should be returned as well. |
tenantId |
No |
String |
Only return instances with the given tenantId. |
tenantIdLike |
No |
String |
Only return instances with a tenantId like the given value. |
withoutTenantId |
No |
Boolean |
If |
| Response code | Description |
|---|---|
200 |
Indicates that historic process instances could be queried. |
400 |
Indicates an parameter was passed in the wrong format. The status-message contains additional information. |
Success response body:
{
"data": [
{
"id" : "5",
"businessKey" : "myKey",
"processDefinitionId" : "oneTaskProcess%3A1%3A4",
"processDefinitionUrl" : "http://localhost:8182/repository/process-definitions/oneTaskProcess%3A1%3A4",
"startTime" : "2013-04-17T10:17:43.902+0000",
"endTime" : "2013-04-18T14:06:32.715+0000",
"durationInMillis" : 86400056,
"startUserId" : "kermit",
"startActivityId" : "startEvent",
"endActivityId" : "endEvent",
"deleteReason" : null,
"superProcessInstanceId" : "3",
"url" : "http://localhost:8182/history/historic-process-instances/5",
"variables": [
{
"name": "test",
"variableScope": "local",
"value": "myTest"
}
],
"tenantId":null
}
],
"total": 1,
"start": 0,
"sort": "name",
"order": "asc",
"size": 1
}15.8.3. Query for historic process instances
POST query/historic-process-instances
Request body:
{
"processDefinitionId" : "oneTaskProcess%3A1%3A4",
"variables" : [
{
"name" : "myVariable",
"value" : 1234,
"operation" : "equals",
"type" : "long"
}
]
}All supported JSON parameter fields allowed are exactly the same as the parameters found for getting a collection of historic process instances, but passed in as JSON-body arguments rather than URL-parameters to allow for more advanced querying and preventing errors with request-uri’s that are too long. On top of that, the query allows for filtering based on process variables. The variables property is a JSON-array containing objects with the format as described here.
| Response code | Description |
|---|---|
200 |
Indicates request was successful and the tasks are returned |
400 |
Indicates an parameter was passed in the wrong format. The status-message contains additional information. |
Success response body:
{
"data": [
{
"id" : "5",
"businessKey" : "myKey",
"processDefinitionId" : "oneTaskProcess%3A1%3A4",
"processDefinitionUrl" : "http://localhost:8182/repository/process-definitions/oneTaskProcess%3A1%3A4",
"startTime" : "2013-04-17T10:17:43.902+0000",
"endTime" : "2013-04-18T14:06:32.715+0000",
"durationInMillis" : 86400056,
"startUserId" : "kermit",
"startActivityId" : "startEvent",
"endActivityId" : "endEvent",
"deleteReason" : null,
"superProcessInstanceId" : "3",
"url" : "http://localhost:8182/history/historic-process-instances/5",
"variables": [
{
"name": "test",
"variableScope": "local",
"value": "myTest"
}
],
"tenantId":null
}
],
"total": 1,
"start": 0,
"sort": "name",
"order": "asc",
"size": 1
}15.8.4. Delete a historic process instance
DELETE history/historic-process-instances/{processInstanceId}
| Response code | Description |
|---|---|
200 |
Indicates that the historic process instance was deleted. |
404 |
Indicates that the historic process instance could not be found. |
15.8.5. Get the identity links of a historic process instance
GET history/historic-process-instance/{processInstanceId}/identitylinks
| Response code | Description |
|---|---|
200 |
Indicates request was successful and the identity links are returned |
404 |
Indicates the process instance could not be found. |
Success response body:
[
{
"type" : "participant",
"userId" : "kermit",
"groupId" : null,
"taskId" : null,
"taskUrl" : null,
"processInstanceId" : "5",
"processInstanceUrl" : "http://localhost:8182/history/historic-process-instances/5"
}
]15.8.6. Get the binary data for a historic process instance variable
GET history/historic-process-instances/{processInstanceId}/variables/{variableName}/data
| Response code | Description |
|---|---|
200 |
Indicates the process instance was found and the requested variable data is returned. |
404 |
Indicates the requested process instance was not found or the process instance doesn’t have a variable with the given name or the variable doesn’t have a binary stream available. Status message provides additional information. |
Success response body:
The response body contains the binary value of the variable. When the variable is of type binary, the content-type of the response is set to application/octet-stream, regardless of the content of the variable or the request accept-type header. In case of serializable, application/x-java-serialized-object is used as content-type.
15.8.7. Create a new comment on a historic process instance
POST history/historic-process-instances/{processInstanceId}/comments
| Parameter | Required | Value | Description |
|---|---|---|---|
processInstanceId |
Yes |
String |
The id of the process instance to create the comment for. |
Request body:
{
"message" : "This is a comment.",
"saveProcessInstanceId" : true
}Parameter saveProcessInstanceId is optional, if true save process instance id of task with comment.
Success response body:
{
"id" : "123",
"taskUrl" : "http://localhost:8081/flowable-rest/service/runtime/tasks/101/comments/123",
"processInstanceUrl" : "http://localhost:8081/flowable-rest/service/history/historic-process-instances/100/comments/123",
"message" : "This is a comment on the task.",
"author" : "kermit",
"time" : "2014-07-13T13:13:52.232+08:00",
"taskId" : "101",
"processInstanceId" : "100"
}| Response code | Description |
|---|---|
201 |
Indicates the comment was created and the result is returned. |
400 |
Indicates the comment is missing from the request. |
404 |
Indicates the requested historic process instance was not found. |
15.8.8. Get all comments on a historic process instance
GET history/historic-process-instances/{processInstanceId}/comments
| Parameter | Required | Value | Description |
|---|---|---|---|
processInstanceId |
Yes |
String |
The id of the process instance to get the comments for. |
Success response body:
[
{
"id" : "123",
"processInstanceUrl" : "http://localhost:8081/flowable-rest/service/history/historic-process-instances/100/comments/123",
"message" : "This is a comment on the task.",
"author" : "kermit",
"time" : "2014-07-13T13:13:52.232+08:00",
"processInstanceId" : "100"
},
{
"id" : "456",
"processInstanceUrl" : "http://localhost:8081/flowable-rest/service/history/historic-process-instances/100/comments/456",
"message" : "This is another comment.",
"author" : "gonzo",
"time" : "2014-07-14T15:16:52.232+08:00",
"processInstanceId" : "100"
}
]| Response code | Description |
|---|---|
200 |
Indicates the process instance was found and the comments are returned. |
404 |
Indicates the requested task was not found. |
15.8.9. Get a comment on a historic process instance
GET history/historic-process-instances/{processInstanceId}/comments/{commentId}
| Parameter | Required | Value | Description |
|---|---|---|---|
processInstanceId |
Yes |
String |
The id of the historic process instance to get the comment for. |
commentId |
Yes |
String |
The id of the comment. |
Success response body:
{
"id" : "123",
"processInstanceUrl" : "http://localhost:8081/flowable-rest/service/history/historic-process-instances/100/comments/456",
"message" : "This is another comment.",
"author" : "gonzo",
"time" : "2014-07-14T15:16:52.232+08:00",
"processInstanceId" : "100"
}| Response code | Description |
|---|---|
200 |
Indicates the historic process instance and comment were found and the comment is returned. |
404 |
Indicates the requested historic process instance was not found or the historic process instance doesn’t have a comment with the given ID. |
15.8.10. Delete a comment on a historic process instance
DELETE history/historic-process-instances/{processInstanceId}/comments/{commentId}
| Parameter | Required | Value | Description |
|---|---|---|---|
processInstanceId |
Yes |
String |
The id of the historic process instance to delete the comment for. |
commentId |
Yes |
String |
The id of the comment. |
| Response code | Description |
|---|---|
204 |
Indicates the historic process instance and comment were found and the comment is deleted. Response body is left empty intentionally. |
404 |
Indicates the requested task was not found or the historic process instance doesn’t have a comment with the given ID. |
15.8.11. Get a single historic task instance
GET history/historic-task-instances/{taskId}
| Response code | Description |
|---|---|
200 |
Indicates that the historic task instances could be found. |
404 |
Indicates that the historic task instances could not be found. |
Success response body:
{
"id" : "5",
"processDefinitionId" : "oneTaskProcess%3A1%3A4",
"processDefinitionUrl" : "http://localhost:8182/repository/process-definitions/oneTaskProcess%3A1%3A4",
"processInstanceId" : "3",
"processInstanceUrl" : "http://localhost:8182/history/historic-process-instances/3",
"executionId" : "4",
"name" : "My task name",
"description" : "My task description",
"deleteReason" : null,
"owner" : "kermit",
"assignee" : "fozzie",
"startTime" : "2013-04-17T10:17:43.902+0000",
"endTime" : "2013-04-18T14:06:32.715+0000",
"durationInMillis" : 86400056,
"workTimeInMillis" : 234890,
"claimTime" : "2013-04-18T11:01:54.715+0000",
"taskDefinitionKey" : "taskKey",
"formKey" : null,
"priority" : 50,
"dueDate" : "2013-04-20T12:11:13.134+0000",
"parentTaskId" : null,
"url" : "http://localhost:8182/history/historic-task-instances/5",
"variables": null,
"tenantId":null
}15.8.12. Get historic task instances
GET history/historic-task-instances
| Parameter | Required | Value | Description |
|---|---|---|---|
taskId |
No |
String |
An id of the historic task instance. |
processInstanceId |
No |
String |
The process instance id of the historic task instance. |
processDefinitionKey |
No |
String |
The process definition key of the historic task instance. |
processDefinitionKeyLike |
No |
String |
The process definition key of the historic task instance, which matches the given value. |
processDefinitionId |
No |
String |
The process definition id of the historic task instance. |
processDefinitionName |
No |
String |
The process definition name of the historic task instance. |
processDefinitionNameLike |
No |
String |
The process definition name of the historic task instance, which matches the given value. |
processBusinessKey |
No |
String |
The process instance business key of the historic task instance. |
processBusinessKeyLike |
No |
String |
The process instance business key of the historic task instance that matches the given value. |
executionId |
No |
String |
The execution id of the historic task instance. |
taskDefinitionKey |
No |
String |
The task definition key for tasks part of a process |
taskName |
No |
String |
The task name of the historic task instance. |
taskNameLike |
No |
String |
The task name with like operator for the historic task instance. |
taskDescription |
No |
String |
The task description of the historic task instance. |
taskDescriptionLike |
No |
String |
The task description with like operator for the historic task instance. |
taskDefinitionKey |
No |
String |
The task identifier from the process definition for the historic task instance. |
taskCategory |
No |
String |
Select tasks with the given category. Note that this is the task category, not the category of the process definition (namespace within the BPMN Xml). |
taskDeleteReason |
No |
String |
The task delete reason of the historic task instance. |
taskDeleteReasonLike |
No |
String |
The task delete reason with like operator for the historic task instance. |
taskAssignee |
No |
String |
The assignee of the historic task instance. |
taskAssigneeLike |
No |
String |
The assignee with like operator for the historic task instance. |
taskOwner |
No |
String |
The owner of the historic task instance. |
taskOwnerLike |
No |
String |
The owner with like operator for the historic task instance. |
taskInvolvedUser |
No |
String |
An involved user of the historic task instance. |
taskPriority |
No |
String |
The priority of the historic task instance. |
finished |
No |
Boolean |
Indication if the historic task instance is finished. |
processFinished |
No |
Boolean |
Indication if the process instance of the historic task instance is finished. |
parentTaskId |
No |
String |
An optional parent task id of the historic task instance. |
dueDate |
No |
Date |
Return only historic task instances that have a due date equal this date. |
dueDateAfter |
No |
Date |
Return only historic task instances that have a due date after this date. |
dueDateBefore |
No |
Date |
Return only historic task instances that have a due date before this date. |
withoutDueDate |
No |
Boolean |
Return only historic task instances that have no due-date. When |
taskCompletedOn |
No |
Date |
Return only historic task instances that have been completed on this date. |
taskCompletedAfter |
No |
Date |
Return only historic task instances that have been completed after this date. |
taskCompletedBefore |
No |
Date |
Return only historic task instances that have been completed before this date. |
taskCreatedOn |
No |
Date |
Return only historic task instances that were created on this date. |
taskCreatedBefore |
No |
Date |
Return only historic task instances that were created before this date. |
taskCreatedAfter |
No |
Date |
Return only historic task instances that were created after this date. |
includeTaskLocalVariables |
No |
Boolean |
An indication if the historic task instance local variables should be returned as well. |
includeProcessVariables |
No |
Boolean |
An indication if the historic task instance global variables should be returned as well. |
tenantId |
No |
String |
Only return historic task instances with the given tenantId. |
tenantIdLike |
No |
String |
Only return historic task instances with a tenantId like the given value. |
withoutTenantId |
No |
Boolean |
If |
| Response code | Description |
|---|---|
200 |
Indicates that historic process instances could be queried. |
400 |
Indicates an parameter was passed in the wrong format. The status-message contains additional information. |
Success response body:
{
"data": [
{
"id" : "5",
"processDefinitionId" : "oneTaskProcess%3A1%3A4",
"processDefinitionUrl" : "http://localhost:8182/repository/process-definitions/oneTaskProcess%3A1%3A4",
"processInstanceId" : "3",
"processInstanceUrl" : "http://localhost:8182/history/historic-process-instances/3",
"executionId" : "4",
"name" : "My task name",
"description" : "My task description",
"deleteReason" : null,
"owner" : "kermit",
"assignee" : "fozzie",
"startTime" : "2013-04-17T10:17:43.902+0000",
"endTime" : "2013-04-18T14:06:32.715+0000",
"durationInMillis" : 86400056,
"workTimeInMillis" : 234890,
"claimTime" : "2013-04-18T11:01:54.715+0000",
"taskDefinitionKey" : "taskKey",
"formKey" : null,
"priority" : 50,
"dueDate" : "2013-04-20T12:11:13.134+0000",
"parentTaskId" : null,
"url" : "http://localhost:8182/history/historic-task-instances/5",
"taskVariables": [
{
"name": "test",
"variableScope": "local",
"value": "myTest"
}
],
"processVariables": [
{
"name": "processTest",
"variableScope": "global",
"value": "myProcessTest"
}
],
"tenantId":null
}
],
"total": 1,
"start": 0,
"sort": "name",
"order": "asc",
"size": 1
}15.8.13. Query for historic task instances
POST query/historic-task-instances
Query for historic task instances - Request body:
{
"processDefinitionId" : "oneTaskProcess%3A1%3A4",
...
"variables" : [
{
"name" : "myVariable",
"value" : 1234,
"operation" : "equals",
"type" : "long"
}
]
}All supported JSON parameter fields allowed are exactly the same as the parameters found for getting a collection of historic task instances, but passed in as JSON-body arguments rather than URL-parameters to allow for more advanced querying and preventing errors with request-uri’s that are too long. On top of that, the query allows for filtering based on process variables. The taskVariables and processVariables properties are JSON-arrays containing objects with the format as described here.
| Response code | Description |
|---|---|
200 |
Indicates request was successful and the tasks are returned |
400 |
Indicates an parameter was passed in the wrong format. The status-message contains additional information. |
Success response body:
{
"data": [
{
"id" : "5",
"processDefinitionId" : "oneTaskProcess%3A1%3A4",
"processDefinitionUrl" : "http://localhost:8182/repository/process-definitions/oneTaskProcess%3A1%3A4",
"processInstanceId" : "3",
"processInstanceUrl" : "http://localhost:8182/history/historic-process-instances/3",
"executionId" : "4",
"name" : "My task name",
"description" : "My task description",
"deleteReason" : null,
"owner" : "kermit",
"assignee" : "fozzie",
"startTime" : "2013-04-17T10:17:43.902+0000",
"endTime" : "2013-04-18T14:06:32.715+0000",
"durationInMillis" : 86400056,
"workTimeInMillis" : 234890,
"claimTime" : "2013-04-18T11:01:54.715+0000",
"taskDefinitionKey" : "taskKey",
"formKey" : null,
"priority" : 50,
"dueDate" : "2013-04-20T12:11:13.134+0000",
"parentTaskId" : null,
"url" : "http://localhost:8182/history/historic-task-instances/5",
"taskVariables": [
{
"name": "test",
"variableScope": "local",
"value": "myTest"
}
],
"processVariables": [
{
"name": "processTest",
"variableScope": "global",
"value": "myProcessTest"
}
],
"tenantId":null
}
],
"total": 1,
"start": 0,
"sort": "name",
"order": "asc",
"size": 1
}15.8.14. Delete a historic task instance
DELETE history/historic-task-instances/{taskId}
| Response code | Description |
|---|---|
200 |
Indicates that the historic task instance was deleted. |
404 |
Indicates that the historic task instance could not be found. |
15.8.15. Get the identity links of a historic task instance
GET history/historic-task-instance/{taskId}/identitylinks
| Response code | Description |
|---|---|
200 |
Indicates request was successful and the identity links are returned |
404 |
Indicates the task instance could not be found. |
Success response body:
[
{
"type" : "assignee",
"userId" : "kermit",
"groupId" : null,
"taskId" : "6",
"taskUrl" : "http://localhost:8182/history/historic-task-instances/5",
"processInstanceId" : null,
"processInstanceUrl" : null
}
]15.8.16. Get the binary data for a historic task instance variable
GET history/historic-task-instances/{taskId}/variables/{variableName}/data
| Response code | Description |
|---|---|
200 |
Indicates the task instance was found and the requested variable data is returned. |
404 |
Indicates the requested task instance was not found or the process instance doesn’t have a variable with the given name or the variable doesn’t have a binary stream available. Status message provides additional information. |
Success response body:
The response body contains the binary value of the variable. When the variable is of type binary, the content-type of the response is set to application/octet-stream, regardless of the content of the variable or the request accept-type header. In case of serializable, application/x-java-serialized-object is used as content-type.
15.8.17. Get historic activity instances
GET history/historic-activity-instances
| Parameter | Required | Value | Description |
|---|---|---|---|
activityId |
No |
String |
An id of the activity instance. |
activityInstanceId |
No |
String |
An id of the historic activity instance. |
activityName |
No |
String |
The name of the historic activity instance. |
activityType |
No |
String |
The element type of the historic activity instance. |
executionId |
No |
String |
The execution id of the historic activity instance. |
finished |
No |
Boolean |
Indication if the historic activity instance is finished. |
taskAssignee |
No |
String |
The assignee of the historic activity instance. |
processInstanceId |
No |
String |
The process instance id of the historic activity instance. |
processDefinitionId |
No |
String |
The process definition id of the historic activity instance. |
tenantId |
No |
String |
Only return instances with the given tenantId. |
tenantIdLike |
No |
String |
Only return instances with a tenantId like the given value. |
withoutTenantId |
No |
Boolean |
If |
| Response code | Description |
|---|---|
200 |
Indicates that historic activity instances could be queried. |
400 |
Indicates an parameter was passed in the wrong format. The status-message contains additional information. |
Success response body:
{
"data": [
{
"id" : "5",
"activityId" : "4",
"activityName" : "My user task",
"activityType" : "userTask",
"processDefinitionId" : "oneTaskProcess%3A1%3A4",
"processDefinitionUrl" : "http://localhost:8182/repository/process-definitions/oneTaskProcess%3A1%3A4",
"processInstanceId" : "3",
"processInstanceUrl" : "http://localhost:8182/history/historic-process-instances/3",
"executionId" : "4",
"taskId" : "4",
"calledProcessInstanceId" : null,
"assignee" : "fozzie",
"startTime" : "2013-04-17T10:17:43.902+0000",
"endTime" : "2013-04-18T14:06:32.715+0000",
"durationInMillis" : 86400056,
"tenantId":null
}
],
"total": 1,
"start": 0,
"sort": "name",
"order": "asc",
"size": 1
}15.8.18. Query for historic activity instances
POST query/historic-activity-instances
Request body:
{
"processDefinitionId" : "oneTaskProcess%3A1%3A4"
}All supported JSON parameter fields allowed are exactly the same as the parameters found for getting a collection of historic task instances, but passed in as JSON-body arguments rather than URL-parameters to allow for more advanced querying and preventing errors with request-uri’s that are too long.
| Response code | Description |
|---|---|
200 |
Indicates request was successful and the activities are returned |
400 |
Indicates an parameter was passed in the wrong format. The status-message contains additional information. |
Success response body:
{
"data": [
{
"id" : "5",
"activityId" : "4",
"activityName" : "My user task",
"activityType" : "userTask",
"processDefinitionId" : "oneTaskProcess%3A1%3A4",
"processDefinitionUrl" : "http://localhost:8182/repository/process-definitions/oneTaskProcess%3A1%3A4",
"processInstanceId" : "3",
"processInstanceUrl" : "http://localhost:8182/history/historic-process-instances/3",
"executionId" : "4",
"taskId" : "4",
"calledProcessInstanceId" : null,
"assignee" : "fozzie",
"startTime" : "2013-04-17T10:17:43.902+0000",
"endTime" : "2013-04-18T14:06:32.715+0000",
"durationInMillis" : 86400056,
"tenantId":null
}
],
"total": 1,
"start": 0,
"sort": "name",
"order": "asc",
"size": 1
}15.8.19. List of historic variable instances
GET history/historic-variable-instances
| Parameter | Required | Value | Description |
|---|---|---|---|
processInstanceId |
No |
String |
The process instance id of the historic variable instance. |
taskId |
No |
String |
The task id of the historic variable instance. |
excludeTaskVariables |
No |
Boolean |
Indication to exclude the task variables from the result. |
variableName |
No |
String |
The variable name of the historic variable instance. |
variableNameLike |
No |
String |
The variable name using the like operator for the historic variable instance. |
| Response code | Description |
|---|---|
200 |
Indicates that historic variable instances could be queried. |
400 |
Indicates an parameter was passed in the wrong format. The status-message contains additional information. |
Success response body:
{
"data": [
{
"id" : "14",
"processInstanceId" : "5",
"processInstanceUrl" : "http://localhost:8182/history/historic-process-instances/5",
"taskId" : "6",
"variable" : {
"name" : "myVariable",
"variableScope", "global",
"value" : "test"
}
}
],
"total": 1,
"start": 0,
"sort": "name",
"order": "asc",
"size": 1
}15.8.20. Query for historic variable instances
POST query/historic-variable-instances
Request body:
{
"processDefinitionId" : "oneTaskProcess%3A1%3A4",
...
"variables" : [
{
"name" : "myVariable",
"value" : 1234,
"operation" : "equals",
"type" : "long"
}
]
}All supported JSON parameter fields allowed are exactly the same as the parameters found for getting a collection of historic process instances, but passed in as JSON-body arguments rather than URL-parameters to allow for more advanced querying and preventing errors with request-uri’s that are too long. On top of that, the query allows for filtering based on process variables. The variables property is a JSON-array containing objects with the format as described here.
| Response code | Description |
|---|---|
200 |
Indicates request was successful and the tasks are returned |
400 |
Indicates an parameter was passed in the wrong format. The status-message contains additional information. |
Success response body:
{
"data": [
{
"id" : "14",
"processInstanceId" : "5",
"processInstanceUrl" : "http://localhost:8182/history/historic-process-instances/5",
"taskId" : "6",
"variable" : {
"name" : "myVariable",
"variableScope", "global",
"value" : "test"
}
}
],
"total": 1,
"start": 0,
"sort": "name",
"order": "asc",
"size": 1
}====Get the binary data for a historic task instance variable
GET history/historic-variable-instances/{varInstanceId}/data
| Response code | Description |
|---|---|
200 |
Indicates the variable instance was found and the requested variable data is returned. |
404 |
Indicates the requested variable instance was not found or the variable instance doesn’t have a variable with the given name or the variable doesn’t have a binary stream available. Status message provides additional information. |
Success response body:
The response body contains the binary value of the variable. When the variable is of type binary, the content-type of the response is set to application/octet-stream, regardless of the content of the variable or the request accept-type header. In case of serializable, application/x-java-serialized-object is used as content-type.
15.8.21. Get historic detail
GET history/historic-detail
| Parameter | Required | Value | Description |
|---|---|---|---|
id |
No |
String |
The id of the historic detail. |
processInstanceId |
No |
String |
The process instance id of the historic detail. |
executionId |
No |
String |
The execution id of the historic detail. |
activityInstanceId |
No |
String |
The activity instance id of the historic detail. |
taskId |
No |
String |
The task id of the historic detail. |
selectOnlyFormProperties |
No |
Boolean |
Indication to only return form properties in the result. |
selectOnlyVariableUpdates |
No |
Boolean |
Indication to only return variable updates in the result. |
| Response code | Description |
|---|---|
200 |
Indicates that historic detail could be queried. |
400 |
Indicates an parameter was passed in the wrong format. The status-message contains additional information. |
Success response body:
{
"data": [
{
"id" : "26",
"processInstanceId" : "5",
"processInstanceUrl" : "http://localhost:8182/history/historic-process-instances/5",
"executionId" : "6",
"activityInstanceId", "10",
"taskId" : "6",
"taskUrl" : "http://localhost:8182/history/historic-task-instances/6",
"time" : "2013-04-17T10:17:43.902+0000",
"detailType" : "variableUpdate",
"revision" : 2,
"variable" : {
"name" : "myVariable",
"variableScope", "global",
"value" : "test"
},
"propertyId": null,
"propertyValue": null
}
],
"total": 1,
"start": 0,
"sort": "name",
"order": "asc",
"size": 1
}15.8.22. Query for historic details
POST query/historic-detail
Request body:
{
"processInstanceId" : "5",
}
All supported JSON parameter fields allowed are exactly the same as the parameters found for getting a collection of historic process instances, but passed in as JSON-body arguments rather than URL-parameters to allow for more advanced querying and preventing errors with request-uri’s that are too long.
| Response code | Description |
|---|---|
200 |
Indicates request was successful and the historic details are returned |
400 |
Indicates an parameter was passed in the wrong format. The status-message contains additional information. |
Success response body:
{
"data": [
{
"id" : "26",
"processInstanceId" : "5",
"processInstanceUrl" : "http://localhost:8182/history/historic-process-instances/5",
"executionId" : "6",
"activityInstanceId", "10",
"taskId" : "6",
"taskUrl" : "http://localhost:8182/history/historic-task-instances/6",
"time" : "2013-04-17T10:17:43.902+0000",
"detailType" : "variableUpdate",
"revision" : 2,
"variable" : {
"name" : "myVariable",
"variableScope", "global",
"value" : "test"
},
"propertyId" : null,
"propertyValue" : null
}
],
"total": 1,
"start": 0,
"sort": "name",
"order": "asc",
"size": 1
}15.8.23. Get the binary data for a historic detail variable
GET history/historic-detail/{detailId}/data
| Response code | Description |
|---|---|
200 |
Indicates the historic detail instance was found and the requested variable data is returned. |
404 |
Indicates the requested historic detail instance was not found or the historic detail instance doesn’t have a variable with the given name or the variable doesn’t have a binary stream available. Status message provides additional information. |
Success response body:
The response body contains the binary value of the variable. When the variable is of type binary, the content-type of the response is set to application/octet-stream, regardless of the content of the variable or the request accept-type header. In case of serializable, application/x-java-serialized-object is used as content-type.
15.9. Forms
15.9.1. Get form data
GET form/form-data
| Parameter | Required | Value | Description |
|---|---|---|---|
taskId |
Yes (if no processDefinitionId) |
String |
The task id corresponding to the form data that needs to be retrieved. |
processDefinitionId |
Yes (if no taskId) |
String |
The process definition id corresponding to the start event form data that needs to be retrieved. |
| Response code | Description |
|---|---|
200 |
Indicates that form data could be queried. |
404 |
Indicates that form data could not be found. |
Success response body:
{
"data": [
{
"formKey" : null,
"deploymentId" : "2",
"processDefinitionId" : "3",
"processDefinitionUrl" : "http://localhost:8182/repository/process-definition/3",
"taskId" : "6",
"taskUrl" : "http://localhost:8182/runtime/task/6",
"formProperties" : [
{
"id" : "room",
"name" : "Room",
"type" : "string",
"value" : null,
"readable" : true,
"writable" : true,
"required" : true,
"datePattern" : null,
"enumValues" : [
{
"id" : "normal",
"name" : "Normal bed"
},
{
"id" : "kingsize",
"name" : "Kingsize bed"
},
]
}
]
}
],
"total": 1,
"start": 0,
"sort": "name",
"order": "asc",
"size": 1
}15.9.2. Submit task form data
POST form/form-data
Request body for task form:
{
"taskId" : "5",
"properties" : [
{
"id" : "room",
"value" : "normal"
}
]
}Request body for start event form:
{
"processDefinitionId" : "5",
"businessKey" : "myKey",
"properties" : [
{
"id" : "room",
"value" : "normal"
}
]
}| Response code | Description |
|---|---|
200 |
Indicates request was successful and the form data was submitted |
400 |
Indicates an parameter was passed in the wrong format. The status-message contains additional information. |
Success response body for start event form data (no response for task form data):
{
"id" : "5",
"url" : "http://localhost:8182/history/historic-process-instances/5",
"businessKey" : "myKey",
"suspended": false,
"processDefinitionId" : "3",
"processDefinitionUrl" : "http://localhost:8182/repository/process-definition/3",
"activityId" : "myTask"
}15.10. Database tables
15.10.1. List of tables
GET management/tables
| Response code | Description |
|---|---|
200 |
Indicates the request was successful. |
Success response body:
[
{
"name":"ACT_RU_VARIABLE",
"url":"http://localhost:8182/management/tables/ACT_RU_VARIABLE",
"count":4528
},
{
"name":"ACT_RU_EVENT_SUBSCR",
"url":"http://localhost:8182/management/tables/ACT_RU_EVENT_SUBSCR",
"count":3
}
]15.10.2. Get a single table
GET management/tables/{tableName}
| Parameter | Required | Value | Description |
|---|---|---|---|
tableName |
Yes |
String |
The name of the table to get. |
Success response body:
{
"name":"ACT_RE_PROCDEF",
"url":"http://localhost:8182/management/tables/ACT_RE_PROCDEF",
"count":60
}| Response code | Description |
|---|---|
200 |
Indicates the table exists and the table count is returned. |
404 |
Indicates the requested table does not exist. |
15.10.3. Get column info for a single table
GET management/tables/{tableName}/columns
| Parameter | Required | Value | Description |
|---|---|---|---|
tableName |
Yes |
String |
The name of the table to get. |
Success response body:
{
"tableName":"ACT_RU_VARIABLE",
"columnNames":[
"ID_",
"REV_",
"TYPE_",
"NAME_"
],
"columnTypes":[
"VARCHAR",
"INTEGER",
"VARCHAR",
"VARCHAR"
]
}| Response code | Description |
|---|---|
200 |
Indicates the table exists and the table column info is returned. |
404 |
Indicates the requested table does not exist. |
15.10.4. Get row data for a single table
GET management/tables/{tableName}/data
| Parameter | Required | Value | Description |
|---|---|---|---|
tableName |
Yes |
String |
The name of the table to get. |
| Parameter | Required | Value | Description |
|---|---|---|---|
start |
No |
Integer |
Index of the first row to fetch. Defaults to 0. |
size |
No |
Integer |
Number of rows to fetch, starting from |
orderAscendingColumn |
No |
String |
Name of the column to sort the resulting rows on, ascending. |
orderDescendingColumn |
No |
String |
Name of the column to sort the resulting rows on, descending. |
Success response body:
{
"total":3,
"start":0,
"sort":null,
"order":null,
"size":3,
"data":[
{
"TASK_ID_":"2",
"NAME_":"var1",
"REV_":1,
"TEXT_":"123",
"LONG_":123,
"ID_":"3",
"TYPE_":"integer"
}
]
}| Response code | Description |
|---|---|
200 |
Indicates the table exists and the table row data is returned. |
404 |
Indicates the requested table does not exist. |
15.11. Engine
15.11.1. Get engine properties
GET management/properties
Returns a read-only view of the properties used internally in the engine.
Success response body:
{
"next.dbid":"101",
"schema.history":"create(5.15)",
"schema.version":"5.15"
}| Response code | Description |
|---|---|
200 |
Indicates the properties are returned. |
15.11.2. Get engine info
GET management/engine
Returns a read-only view of the engine that is used in this REST-service.
Success response body:
{
"name":"default",
"version":"5.15",
"resourceUrl":"file://flowable/flowable.cfg.xml",
"exception":null
}| Response code | Description |
|---|---|
200 |
Indicates the engine info is returned. |
15.12. Runtime
15.12.1. Signal event received
POST runtime/signals
Notifies the engine that a signal event has been received, not explicitly related to a specific execution.
Body JSON:
{
"signalName": "My Signal",
"tenantId" : "execute",
"async": true,
"variables": [
{"name": "testVar", "value": "This is a string"}
]
}| Parameter | Description | Required |
|---|---|---|
signalName |
Name of the signal |
Yes |
tenantId |
ID of the tenant that the signal event should be processed in |
No |
async |
If |
No |
variables |
Array of variables (in the general variables format) to use as payload to pass along with the signal. Cannot be used in case |
No |
Success response body:
| Response code | Description |
|---|---|
200 |
Indicated signal has been processed and no errors occurred. |
202 |
Indicated signal processing is queued as a job, ready to be executed. |
400 |
Signal not processed. The signal name is missing or variables are used together with async, which is not allowed. Response body contains additional information about the error. |
15.13. Jobs
15.13.1. Get a single job
GET management/jobs/{jobId}
| Parameter | Required | Value | Description |
|---|---|---|---|
jobId |
Yes |
String |
The id of the job to get. |
Success response body:
{
"id":"8",
"url":"http://localhost:8182/management/jobs/8",
"processInstanceId":"5",
"processInstanceUrl":"http://localhost:8182/runtime/process-instances/5",
"processDefinitionId":"timerProcess:1:4",
"processDefinitionUrl":"http://localhost:8182/repository/process-definitions/timerProcess%3A1%3A4",
"executionId":"7",
"executionUrl":"http://localhost:8182/runtime/executions/7",
"retries":3,
"exceptionMessage":null,
"dueDate":"2013-06-04T22:05:05.474+0000",
"tenantId":null
}| Response code | Description |
|---|---|
200 |
Indicates the job exists and is returned. |
404 |
Indicates the requested job does not exist. |
15.13.2. Delete a job
DELETE management/jobs/{jobId}
| Parameter | Required | Value | Description |
|---|---|---|---|
jobId |
Yes |
String |
The id of the job to delete. |
| Response code | Description |
|---|---|
204 |
Indicates the job was found and has been deleted. Response-body is intentionally empty. |
404 |
Indicates the requested job was not found. |
15.13.3. Execute a single job
POST management/jobs/{jobId}
Body JSON:
{
"action" : "execute"
}| Parameter | Description | Required |
|---|---|---|
action |
Action to perform. Only |
Yes |
| Response code | Description |
|---|---|
204 |
Indicates the job was executed. Response-body is intentionally empty. |
404 |
Indicates the requested job was not found. |
500 |
Indicates the an exception occurred while executing the job. The status-description contains additional detail about the error. The full error-stacktrace can be fetched later on if needed. |
15.13.4. Get the exception stacktrace for a job
GET management/jobs/{jobId}/exception-stacktrace
| Parameter | Description | Required |
|---|---|---|
jobId |
Id of the job to get the stacktrace for. |
Yes |
| Response code | Description |
|---|---|
200 |
Indicates the requested job was not found and the stacktrace has been returned. The response contains the raw stacktrace and always has a Content-type of |
404 |
Indicates the requested job was not found or the job doesn’t have an exception stacktrace. Status-description contains additional information about the error. |
15.13.5. Get a list of jobs
GET management/jobs
| Parameter | Description | Type |
|---|---|---|
id |
Only return job with the given id |
String |
processInstanceId |
Only return jobs part of a process with the given id |
String |
executionId |
Only return jobs part of an execution with the given id |
String |
processDefinitionId |
Only return jobs with the given process definition id |
String |
withRetriesLeft |
If |
Boolean |
executable |
If |
Boolean |
timersOnly |
If |
Boolean |
messagesOnly |
If |
Boolean |
withException |
If |
Boolean |
dueBefore |
Only return jobs which are due to be executed before the given date. Jobs without duedate are never returned using this parameter. |
Date |
dueAfter |
Only return jobs which are due to be executed after the given date. Jobs without duedate are never returned using this parameter. |
Date |
exceptionMessage |
Only return jobs with the given exception message |
String |
tenantId |
No |
String |
Only return jobs with the given tenantId. |
tenantIdLike |
No |
String |
Only return jobs with a tenantId like the given value. |
withoutTenantId |
No |
Boolean |
If |
sort |
Field to sort results on, should be one of |
String |
Success response body:
{
"data":[
{
"id":"13",
"url":"http://localhost:8182/management/jobs/13",
"processInstanceId":"5",
"processInstanceUrl":"http://localhost:8182/runtime/process-instances/5",
"processDefinitionId":"timerProcess:1:4",
"processDefinitionUrl":"http://localhost:8182/repository/process-definitions/timerProcess%3A1%3A4",
"executionId":"12",
"executionUrl":"http://localhost:8182/runtime/executions/12",
"retries":0,
"exceptionMessage":"Can't find scripting engine for 'unexistinglanguage'",
"dueDate":"2013-06-07T10:00:24.653+0000",
"tenantId":null
}
],
"total":2,
"start":0,
"sort":"id",
"order":"asc",
"size":2
}| Response code | Description |
|---|---|
200 |
Indicates the requested jobs were returned. |
400 |
Indicates an illegal value has been used in a url query parameter or the both |
15.13.6. Get a single deadletter job
GET management/deadletter-jobs/{jobId}
| Parameter | Required | Value | Description |
|---|---|---|---|
jobId |
Yes |
String |
The id of the dead letter job to get. |
Success response body:
{
"id":"8",
"url":"http://localhost:8182/management/jobs/8",
"processInstanceId":"5",
"processInstanceUrl":"http://localhost:8182/runtime/process-instances/5",
"processDefinitionId":"timerProcess:1:4",
"processDefinitionUrl":"http://localhost:8182/repository/process-definitions/timerProcess%3A1%3A4",
"executionId":"7",
"executionUrl":"http://localhost:8182/runtime/executions/7",
"retries":0,
"exceptionMessage":"Can't find scripting engine for 'unexistinglanguage'",
"dueDate":"2013-06-04T22:05:05.474+0000",
"tenantId":null
}| Response code | Description |
|---|---|
200 |
Indicates the dead letter job exists and is returned. |
404 |
Indicates the requested dead letter job does not exist. |
15.13.7. Delete a dead letter job
DELETE management/deadletter-jobs/{jobId}
| Parameter | Required | Value | Description |
|---|---|---|---|
jobId |
Yes |
String |
The id of the dead letter job to delete. |
| Response code | Description |
|---|---|
204 |
Indicates the dead letter job was found and has been deleted. Response-body is intentionally empty. |
404 |
Indicates the requested dead letter job was not found. |
15.13.8. Resume and execute a dead letter job
POST management/deadletter-jobs/{jobId}
Body JSON:
{
"action" : "move"
}| Parameter | Description | Required |
|---|---|---|
action |
Action to perform. Only |
Yes |
| Response code | Description |
|---|---|
204 |
Indicates the dead letter job was executed. Response-body is intentionally empty. |
404 |
Indicates the requested dead letter job was not found. |
500 |
Indicates the an exception occurred while executing the dead letter job. The status-description contains additional detail about the error. The full error-stacktrace can be fetched later on if needed. |
15.13.9. Get the exception stacktrace for a deadletter job
GET management/deadletter-jobs/{jobId}/exception-stacktrace
| Parameter | Description | Required |
|---|---|---|
jobId |
Id of the dead letter job to get the stacktrace for. |
Yes |
| Response code | Description |
|---|---|
200 |
Indicates the requested dead letter job was not found and the stacktrace has been returned. The response contains the raw stacktrace and always has a Content-type of |
404 |
Indicates the requested dead letter job was not found or the job doesn’t have an exception stacktrace. Status-description contains additional information about the error. |
15.13.10. Get a list of dead letterjobs
GET management/deadletter-jobs
| Parameter | Description | Type |
|---|---|---|
id |
Only return job with the given id |
String |
processInstanceId |
Only return jobs part of a process with the given id |
String |
executionId |
Only return jobs part of an execution with the given id |
String |
processDefinitionId |
Only return jobs with the given process definition id |
String |
executable |
If |
Boolean |
timersOnly |
If |
Boolean |
messagesOnly |
If |
Boolean |
withException |
If |
Boolean |
dueBefore |
Only return jobs which are due to be executed before the given date. Jobs without duedate are never returned using this parameter. |
Date |
dueAfter |
Only return jobs which are due to be executed after the given date. Jobs without duedate are never returned using this parameter. |
Date |
withException |
If |
Boolean |
tenantId |
String |
Only return jobs with exception. |
tenantIdLike |
String |
Only return jobs with a tenantId like the given value. |
withoutTenantId |
Boolean |
If |
locked |
Boolean |
If |
unlocked |
Boolean |
If |
sort |
Field to sort results on, should be one of |
String |
Success response body:
{
"data":[
{
"id":"13",
"url":"http://localhost:8182/management/jobs/13",
"processInstanceId":"5",
"processInstanceUrl":"http://localhost:8182/runtime/process-instances/5",
"processDefinitionId":"timerProcess:1:4",
"processDefinitionUrl":"http://localhost:8182/repository/process-definitions/timerProcess%3A1%3A4",
"executionId":"12",
"executionUrl":"http://localhost:8182/runtime/executions/12",
"retries":0,
"withException":"Can't find scripting engine for 'unexistinglanguage'",
"dueDate":"2013-06-07T10:00:24.653+0000",
"createTime":"2013-06-06T08:08:24.007+0000"
"tenantId":null
}
],
"total":2,
"start":0,
"sort":"id",
"order":"asc",
"size":2
}| Response code | Description |
|---|---|
200 |
Indicates the requested jobs were returned. |
400 |
Indicates an illegal value has been used in a url query parameter or the both |
15.14. Users
15.14.1. Get a single user
GET identity/users/{userId}
| Parameter | Required | Value | Description |
|---|---|---|---|
userId |
Yes |
String |
The id of the user to get. |
Success response body:
{
"id":"testuser",
"firstName":"Fred",
"lastName":"McDonald",
"url":"http://localhost:8182/identity/users/testuser",
"email":"no-reply@flowable.org"
}| Response code | Description |
|---|---|
200 |
Indicates the user exists and is returned. |
404 |
Indicates the requested user does not exist. |
15.14.2. Get a list of users
GET identity/users
| Parameter | Description | Type |
|---|---|---|
id |
Only return user with the given id |
String |
firstName |
Only return users with the given firstname |
String |
lastName |
Only return users with the given lastname |
String |
Only return users with the given email |
String |
|
firstNameLike |
Only return users with a firstname like the given value. Use |
String |
lastNameLike |
Only return users with a lastname like the given value. Use |
String |
emailLike |
Only return users with an email like the given value. Use |
String |
memberOfGroup |
Only return users which are a member of the given group. |
String |
potentialStarter |
Only return users which are potential starters for a process-definition with the given id. |
String |
sort |
Field to sort results on, should be one of |
String |
Success response body:
{
"data":[
{
"id":"anotherUser",
"firstName":"Tijs",
"lastName":"Barrez",
"url":"http://localhost:8182/identity/users/anotherUser",
"email":"no-reply@flowable.org"
},
{
"id":"kermit",
"firstName":"Kermit",
"lastName":"the Frog",
"url":"http://localhost:8182/identity/users/kermit",
"email":null
},
{
"id":"testuser",
"firstName":"Fred",
"lastName":"McDonald",
"url":"http://localhost:8182/identity/users/testuser",
"email":"no-reply@flowable.org"
}
],
"total":3,
"start":0,
"sort":"id",
"order":"asc",
"size":3
}| Response code | Description |
|---|---|
200 |
Indicates the requested users were returned. |
15.14.3. Update a user
PUT identity/users/{userId}
Body JSON:
{
"firstName":"Tijs",
"lastName":"Barrez",
"email":"no-reply@flowable.org",
"password":"pass123"
}All request values are optional. For example, you can only include the firstName attribute in the request body JSON-object, only updating the firstName of the user, leaving all other fields unaffected. When an attribute is explicitly included and is set to null, the user-value will be updated to null. Example: {"firstName" : null} will clear the firstName of the user).
| Response code | Description |
|---|---|
200 |
Indicates the user was updated. |
404 |
Indicates the requested user was not found. |
409 |
Indicates the requested user was updated simultaneously. |
Success response body: see response for identity/users/{userId}.
15.14.4. Create a user
POST identity/users
Body JSON:
{
"id":"tijs",
"firstName":"Tijs",
"lastName":"Barrez",
"email":"no-reply@flowable.org",
"password":"pass123"
}
| Response code | Description |
|---|---|
201 |
Indicates the user was created. |
400 |
Indicates the id of the user was missing. |
Success response body: see response for identity/users/{userId}.
15.14.5. Delete a user
DELETE identity/users/{userId}
| Parameter | Required | Value | Description |
|---|---|---|---|
userId |
Yes |
String |
The id of the user to delete. |
| Response code | Description |
|---|---|
204 |
Indicates the user was found and has been deleted. Response-body is intentionally empty. |
404 |
Indicates the requested user was not found. |
15.14.6. Get a user’s picture
GET identity/users/{userId}/picture
| Parameter | Required | Value | Description |
|---|---|---|---|
userId |
Yes |
String |
The id of the user to get the picture for. |
Response Body:
The response body contains the raw picture data, representing the user’s picture. The Content-type of the response corresponds to the mimeType that was set when creating the picture.
| Response code | Description |
|---|---|
200 |
Indicates the user was found and has a picture, which is returned in the body. |
404 |
Indicates the requested user was not found or the user does not have a profile picture. Status-description contains additional information about the error. |
15.14.7. Updating a user’s picture
GET identity/users/{userId}/picture
| Parameter | Required | Value | Description |
|---|---|---|---|
userId |
Yes |
String |
The id of the user to get the picture for. |
Request body:
The request should be of type multipart/form-data. There should be a single file-part included with the binary value of the picture. On top of that, the following additional form-fields can be present:
-
mimeType: Optional mime-type for the uploaded picture. If omitted, the default ofimage/jpegis used as a mime-type for the picture.
| Response code | Description |
|---|---|
200 |
Indicates the user was found and the picture has been updated. The response-body is left empty intentionally. |
404 |
Indicates the requested user was not found. |
15.14.8. List a user’s info
PUT identity/users/{userId}/info
| Parameter | Required | Value | Description |
|---|---|---|---|
userId |
Yes |
String |
The id of the user to get the info for. |
Response Body:
[
{
"key":"key1",
"url":"http://localhost:8182/identity/users/testuser/info/key1"
},
{
"key":"key2",
"url":"http://localhost:8182/identity/users/testuser/info/key2"
}
]| Response code | Description |
|---|---|
200 |
Indicates the user was found and list of info (key and url) is returned. |
404 |
Indicates the requested user was not found. |
15.14.9. Get a user’s info
GET identity/users/{userId}/info/{key}
| Parameter | Required | Value | Description |
|---|---|---|---|
userId |
Yes |
String |
The id of the user to get the info for. |
key |
Yes |
String |
The key of the user info to get. |
Response Body:
{
"key":"key1",
"value":"Value 1",
"url":"http://localhost:8182/identity/users/testuser/info/key1"
}| Response code | Description |
|---|---|
200 |
Indicates the user was found and the user has info for the given key.. |
404 |
Indicates the requested user was not found or the user doesn’t have info for the given key. Status description contains additional information about the error. |
15.14.10. Update a user’s info
PUT identity/users/{userId}/info/{key}
| Parameter | Required | Value | Description |
|---|---|---|---|
userId |
Yes |
String |
The id of the user to update the info for. |
key |
Yes |
String |
The key of the user info to update. |
Request Body:
{
"value":"The updated value"
}Response Body:
{
"key":"key1",
"value":"The updated value",
"url":"http://localhost:8182/identity/users/testuser/info/key1"
}| Response code | Description |
|---|---|
200 |
Indicates the user was found and the info has been updated. |
400 |
Indicates the value was missing from the request body. |
404 |
Indicates the requested user was not found or the user doesn’t have info for the given key. Status description contains additional information about the error. |
15.14.11. Create a new user’s info entry
POST identity/users/{userId}/info
| Parameter | Required | Value | Description |
|---|---|---|---|
userId |
Yes |
String |
The id of the user to create the info for. |
Request Body:
{
"key":"key1",
"value":"The value"
}Response Body:
{
"key":"key1",
"value":"The value",
"url":"http://localhost:8182/identity/users/testuser/info/key1"
}| Response code | Description |
|---|---|
201 |
Indicates the user was found and the info has been created. |
400 |
Indicates the key or value was missing from the request body. Status description contains additional information about the error. |
404 |
Indicates the requested user was not found. |
409 |
Indicates there is already an info-entry with the given key for the user, update the resource instance ( |
15.14.12. Delete a user’s info
DELETE identity/users/{userId}/info/{key}
| Parameter | Required | Value | Description |
|---|---|---|---|
userId |
Yes |
String |
The id of the user to delete the info for. |
key |
Yes |
String |
The key of the user info to delete. |
| Response code | Description |
|---|---|
204 |
Indicates the user was found and the info for the given key has been deleted. Response body is left empty intentionally. |
404 |
Indicates the requested user was not found or the user doesn’t have info for the given key. Status description contains additional information about the error. |
15.15. Groups
15.15.1. Get a single group
GET identity/groups/{groupId}
| Parameter | Required | Value | Description |
|---|---|---|---|
groupId |
Yes |
String |
The id of the group to get. |
Success response body:
{
"id":"testgroup",
"url":"http://localhost:8182/identity/groups/testgroup",
"name":"Test group",
"type":"Test type"
}| Response code | Description |
|---|---|
200 |
Indicates the group exists and is returned. |
404 |
Indicates the requested group does not exist. |
15.15.2. Get a list of groups
GET identity/groups
| Parameter | Description | Type |
|---|---|---|
id |
Only return group with the given id |
String |
name |
Only return groups with the given name |
String |
type |
Only return groups with the given type |
String |
nameLike |
Only return groups with a name like the given value. Use |
String |
member |
Only return groups which have a member with the given username. |
String |
potentialStarter |
Only return groups which members are potential starters for a process-definition with the given id. |
String |
sort |
Field to sort results on, should be one of |
String |
Success response body:
{
"data":[
{
"id":"testgroup",
"url":"http://localhost:8182/identity/groups/testgroup",
"name":"Test group",
"type":"Test type"
}
],
"total":3,
"start":0,
"sort":"id",
"order":"asc",
"size":3
}| Response code | Description |
|---|---|
200 |
Indicates the requested groups were returned. |
15.15.3. Update a group
PUT identity/groups/{groupId}
Body JSON:
{
"name":"Test group",
"type":"Test type"
}All request values are optional. For example, you can only include the name attribute in the request body JSON-object, only updating the name of the group, leaving all other fields unaffected. When an attribute is explicitly included and is set to null, the group-value will be updated to null.
| Response code | Description |
|---|---|
200 |
Indicates the group was updated. |
404 |
Indicates the requested group was not found. |
409 |
Indicates the requested group was updated simultaneously. |
Success response body: see response for identity/groups/{groupId}.
15.15.4. Create a group
POST identity/groups
Body JSON:
{
"id":"testgroup",
"name":"Test group",
"type":"Test type"
}| Response code | Description |
|---|---|
201 |
Indicates the group was created. |
400 |
Indicates the id of the group was missing. |
Success response body: see response for identity/groups/{groupId}.
15.15.5. Delete a group
DELETE identity/groups/{groupId}
| Parameter | Required | Value | Description |
|---|---|---|---|
groupId |
Yes |
String |
The id of the group to delete. |
| Response code | Description |
|---|---|
204 |
Indicates the group was found and has been deleted. Response-body is intentionally empty. |
404 |
Indicates the requested group was not found. |
15.15.6. Get members in a group
There is no GET allowed on identity/groups/members. Use the identity/users?memberOfGroup=sales URL to get all users that are part of a particular group.
15.15.7. Add a member to a group
POST identity/groups/{groupId}/members
| Parameter | Required | Value | Description |
|---|---|---|---|
groupId |
Yes |
String |
The id of the group to add a member to. |
Body JSON:
{
"userId":"kermit"
}| Response code | Description |
|---|---|
201 |
Indicates the group was found and the member has been added. |
404 |
Indicates the userId was not included in the request body. |
404 |
Indicates the requested group was not found. |
409 |
Indicates the requested user is already a member of the group. |
Response Body:
{
"userId":"kermit",
"groupId":"sales",
"url":"http://localhost:8182/identity/groups/sales/members/kermit"
}15.15.8. Delete a member from a group
DELETE identity/groups/{groupId}/members/{userId}
| Parameter | Required | Value | Description |
|---|---|---|---|
groupId |
Yes |
String |
The id of the group to remove a member from. |
userId |
Yes |
String |
The id of the user to remove. |
| Response code | Description |
|---|---|
204 |
Indicates the group was found and the member has been deleted. The response body is left empty intentionally. |
404 |
Indicates the requested group was not found or that the user is not a member of the group. The status description contains additional information about the error. |
Response Body:
{
"userId":"kermit",
"groupId":"sales",
"url":"http://localhost:8182/identity/groups/sales/members/kermit"
}16. 集成CDI
flowable-cdi模块结合了Flowable的可配置性及CDI(上下文和依赖注入, Contexts and Dependency Injection, J2EE)的可扩展性。flowable-cdi最突出的特点是:
-
支持@BusinessProcessScoped bean(生命周期绑定至流程实例的CDI bean),
-
从流程中解析CDI bean(包括EJB)的自定义El解析器,
-
使用注解对流程实例进行声明式控制,
-
Flowable关联至CDI事件总线,
-
可以与Java EE,Java SE,以及Spring一起工作,
-
支持单元测试。
<dependency>
<groupId>org.flowable</groupId>
<artifactId>flowable-cdi</artifactId>
<version>6.x</version>
</dependency>16.1. 安装flowable-cdi
Flowable CDI可以安装在不同环境中。在这个章节我们主要介绍配置选项。
16.1.1. 查找流程引擎
CDI扩展需要访问流程引擎,在运行时会查找org.flowable.cdi.spi.ProcessEngineLookup接口的实现。CDI模块提供了默认的名为org.flowable.cdi.impl.LocalProcessEngineLookup的实现,使用ProcessEngines-Utility类查找流程引擎,默认配置下用 ProcessEngines#NAME_DEFAULT 查找流程引擎。如果需要使用自定义的名字,需要扩展这个类。请注意:需要将flowable.cfg.xml配置文件放在classpath中。
Flowable cdi使用java.util.ServiceLoader SPI解析org.flowable.cdi.spi.ProcessEngineLookup实例。为了提供接口的自定义实现,需要在部署中添加名为META-INF/services/org.flowable.cdi.spi.ProcessEngineLookup的纯文本文件,并在其中设置实现的全限定类名。
|
如果不提供自定义的 |
16.1.2. 配置流程引擎
配置方式取决于所选用的流程引擎查找策略(上一章节)。这章介绍与LocalProcessEngineLookup一起使用的可用配置选项,并需要在classpath中提供一个Spring flowable.cfg.xml文件。
根据底层事务管理策略的不同,Flowable提供了不同的ProcessEngineConfiguration实现。flowable-cdi模块不关注事务,也就意味着可以使用任何事务管理策略(甚至是Spring抽象事务)。按照约定,CDI模块提供两个自定义的ProcessEngineConfiguration实现:
-
org.flowable.cdi.CdiJtaProcessEngineConfiguration: Flowable JtaProcessEngineConfiguration的子类,可用于Flowable使用JTA管理事务的情况 -
org.flowable.cdi.CdiStandaloneProcessEngineConfiguration: StandaloneProcessEngineConfiguration的子类,可用于Flowable使用简单JDBC事务的情况。
下面是一个JBoss 7的flowable.cfg.xml文件示例:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd">
<!-- 查找JTA事务管理器 -->
<bean id="transactionManager" class="org.springframework.jndi.JndiObjectFactoryBean">
<property name="jndiName" value="java:jboss/TransactionManager"></property>
<property name="resourceRef" value="true" />
</bean>
<!-- 流程定义配置 -->
<bean id="processEngineConfiguration"
class="org.flowable.cdi.CdiJtaProcessEngineConfiguration">
<!-- 查找默认的Jboss数据源 -->
<property name="dataSourceJndiName" value="java:jboss/datasources/ExampleDS" />
<property name="databaseType" value="h2" />
<property name="transactionManager" ref="transactionManager" />
<!-- 使用外部管理事务 -->
<property name="transactionsExternallyManaged" value="true" />
<property name="databaseSchemaUpdate" value="true" />
</bean>
</beans>这是Glassfish 3.1.1中的配置(假设已正确配置了名为jdbc/flowable的数据源):
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd">
<!-- 查找JTA事务管理器 -->
<bean id="transactionManager" class="org.springframework.jndi.JndiObjectFactoryBean">
<property name="jndiName" value="java:appserver/TransactionManager"></property>
<property name="resourceRef" value="true" />
</bean>
<!-- 流程定义配置 -->
<bean id="processEngineConfiguration"
class="org.flowable.cdi.CdiJtaProcessEngineConfiguration">
<property name="dataSourceJndiName" value="jdbc/flowable" />
<property name="transactionManager" ref="transactionManager" />
<!-- 使用外部管理事务 -->
<property name="transactionsExternallyManaged" value="true" />
<property name="databaseSchemaUpdate" value="true" />
</bean>
</beans>请注意上面的配置需要"spring-context"模块:
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-context</artifactId>
<version>4.2.5.RELEASE</version>
</dependency>Java SE环境中的配置与创建流程引擎章节中的示例一样,只是用"CdiStandaloneProcessEngineConfiguration"代替"StandaloneProcessEngineConfiguration"。
16.1.3. 部署流程
可以使用标准的Flowable API(RepositoryService)部署流程。另外,flowable-cdi也提供了自动部署流程的功能,部署classpath中的processes.xml文件提供的流程列表。这是一个processes.xml文件的例子:
<?xml version="1.0" encoding="utf-8" ?>
<!-- 需要部署的流程列表 -->
<processes>
<process resource="diagrams/myProcess.bpmn20.xml" />
<process resource="diagrams/myOtherProcess.bpmn20.xml" />
</processes>16.2. 使用CDI的基于上下文的流程执行
本章节将介绍Flowable CDI扩展使用的基于上下文的流程执行模型(contextual process execution model)。BPMN业务流程通常是一个长期运行的交互动作,包含用户与系统的任务。在运行时,流程分割为独立工作单元的集合,由用户与/或应用逻辑操作。在flowable-cdi中,流程实例可以关联至一个CDI作用域,代表了一个工作单元。在工作单元很复杂的时候特别有用,比如用户任务由多个不同表单的复杂顺序组成,并需要在交互过程中保持"非流程作用域(non-process-scoped)"状态的场景。
16.2.1. 将一个会话关联至一个流程实例
解析@BusinessProcessScoped bean或注入流程变量,都依赖活动的CDI作用域与流程实例的关联。flowable-cdi提供了org.flowable.cdi.BusinessProcess bean用于控制该关联,并提供:
-
startProcessBy(…)方法,镜像了Flowable
RuntimeService服务暴露的对应方法,用于启动并关联一个业务流程, -
resumeProcessById(String processInstanceId),用于将给定id关联至流程实例, -
resumeTaskById(String taskId),用于将给定id关联至任务(以及扩展至相关的流程实例)。
当完成了一个工作单元(例如一个用户任务)时,可以调用completeTask()方法,解除流程实例与会话/请求的关联。这将通知Flowable完成当前任务,并继续运行流程实例。
请注意BusinessProcess bean是一个@Named bean,意味着可以使用表达式(比如在JSF页面中)调用它。下面的JSF2代码片段启动了一个新的会话,并将其关联至一个用户任务实例,其id作为请求参数传递(例如pageName.jsf?taskId=XX):
<f:metadata>
<f:viewParam name="taskId" />
<f:event type="preRenderView" listener="#{businessProcess.startTask(taskId, true)}" />
</f:metadata>16.2.2. 声明式控制流程
Flowable可以使用注解,声明式地启动流程实例以及完成任务。@org.flowable.cdi.annotation.StartProcess注解可以通过"key"或"name"启动一个流程实例。请注意流程实例在注解的方法返回之后启动。例如:
@StartProcess("authorizeBusinessTripRequest")
public String submitRequest(BusinessTripRequest request) {
// 进行一些操作
return "success";
}按照Flowable的配置,被注解的方法代码以及流程实例的启动将处于同一个事务中。@org.flowable.cdi.annotation.CompleteTask的使用方式相同:
@CompleteTask(endConversation=false)
public String authorizeBusinessTrip() {
// 进行一些操作
return "success";
}@CompleteTask注解可以结束当前会话。默认行为是在调用Flowable返回后结束回话。但可以像上面的例子一样,禁用结束会话。
16.2.3. 从流程中引用Bean
flowable-cdi使用自定义解析器,将CDI bean暴露给Flowable El。因此可以像这样在流程中引用bean:
<userTask id="authorizeBusinessTrip" name="Authorize Business Trip"
flowable:assignee="#{authorizingManager.account.username}" />其中"authorizingManager"可以是生产者方法提供的bean:
@Inject @ProcessVariable Object businessTripRequesterUsername;
@Produces
@Named
public Employee authorizingManager() {
TypedQuery<Employee> query = entityManager.createQuery("SELECT e FROM Employee e WHERE e.account.username='"
+ businessTripRequesterUsername + "'", Employee.class);
Employee employee = query.getSingleResult();
return employee.getManager();
}可以使用flowable:expression="myEjb.method()"扩展,在服务任务中调用一个EJB中的业务方法。请注意这需要在MyEjb类上使用@Named注解。
16.2.4. 使用@BusinessProcessScoped bean
可以使用flowable-cdi将一个bean的生命周期绑定在一个流程实例上。为此提供名为BusinessProcessContext的自定义的上下文实现。BusinessProcessScoped bean实例将作为流程变量存储在当前流程实例中。BusinessProcessScoped bean需要是可持久化(PassivationCapable,例如Serializable)的。下面是一个流程作用域bean的例子:
@Named
@BusinessProcessScoped
public class BusinessTripRequest implements Serializable {
private static final long serialVersionUID = 1L;
private String startDate;
private String endDate;
// ...
}有时也需要在没有关联至流程实例的情况下(例如在流程启动前)使用流程作用域bean。如果当前没有激活的流程实例,则BusinessProcessScoped bean的实例将临时存储在本地作用域(也就是会话或请求中,取决于上下文)。如果该作用域之后关联至一个业务流程实例,则会将bean实例刷入该流程实例。
16.2.5. 注入流程变量
flowable-cdi支持以下方式注入流程变量
-
使用
@Inject [additional qualifiers] Type fieldName类型安全地注入@BusinessProcessScopedbean -
使用
@ProcessVariable(name?)限定名不安全地注入其它流程变量:
@Inject @ProcessVariable Object accountNumber;
@Inject @ProcessVariable("accountNumber") Object account要在EL中引用流程变量,有类似的选择:
-
可以直接引用
@Named @BusinessProcessScopedbean, -
可以通过
ProcessVariablesbean引用其它流程变量:
#{processVariables['accountNumber']}
16.2.6. 接收流程事件
Flowable可以关联至CDI事件总线。这样就可以使用标准CDI事件机制获取流程事件。要为Flowable启用CDI事件支持,需要在配置中启用相应的处理监听器:
<property name="postBpmnParseHandlers">
<list>
<bean class="org.flowable.cdi.impl.event.CdiEventSupportBpmnParseHandler" />
</list>
</property>这样Flowable就被配置为使用CDI事件总线发布事件。下面介绍如何在CDI bean中接收流程事件。事件通知是类型安全的。流程事件的类型是org.flowable.cdi.BusinessProcessEvent。
下面是一个简单的事件观察者方法的例子:
public void onProcessEvent(@Observes BusinessProcessEvent businessProcessEvent) {
// 处理事件
}所有事件都会通知观察者。如果需要限制观察者接收的事件,可以添加限定注解:
-
@BusinessProcess: 限制事件为特定的流程定义。例如:@Observes @BusinessProcess("billingProcess") BusinessProcessEvent evt -
@StartActivity: 使用特定的活动限制事件。例如:@Observes @StartActivity("shipGoods") BusinessProcessEvent evt将在进入id为"shipGoods"的活动时调用。 -
@EndActivity: 使用特定的活动限制事件。例如:@Observes @EndActivity("shipGoods") BusinessProcessEvent evt将在离开id为"shipGoods"的活动时调用。 -
@TakeTransition: 使用特定的路径限制事件。 -
@CreateTask: 使用特定任务的创建限制事件。 -
@DeleteTask: 使用特定任务的删除限制事件。 -
@AssignTask: 使用特定任务的指派限制事件。 -
@CompleteTask: 使用特定任务的完成限制事件。
上面的限定名可以自由组合。例如,要接收离开"shipmentProcess"中的"shipGoods"活动时生成的所有事件,可以撰写下面的观察者方法:
public void beforeShippingGoods(@Observes @BusinessProcess("shippingProcess") @EndActivity("shipGoods") BusinessProcessEvent evt) {
// 处理事件
}在默认配置下,事件监听器将在上下文相同的事务中同步调用。CDI事务性观察者(CDI transactional observer,只能与JavaEE/EJB一起使用)可以在将事件交给观察者方法时进行控制。使用事务性观察者,可以保证比如只在触发事件的事务成功时才通知观察者:
public void onShipmentSuceeded(@Observes(during=TransactionPhase.AFTER_SUCCESS) @BusinessProcess("shippingProcess") @EndActivity("shipGoods") BusinessProcessEvent evt) {
// 给客户发送邮件。
}16.2.7. 其他功能
-
可以注入流程引擎与服务:
@Inject ProcessEngine, RepositoryService, TaskService, … -
可以注入当前的流程实例与任务:
@Inject ProcessInstance, Task, -
可以注入当前的businessKey:
@Inject @BusinessKey String businessKey, -
可以注入当前的流程实例id:
@Inject @ProcessInstanceId String pid+
16.3. 已知限制
尽管flowable-cdi遵循SPI,并设计为“可插拔扩展”,但只在Weld下进行了测试。
17. 集成LDAP
很多公司使用LDAP(Lightweight Directory Access Protocol,轻量级目录访问协议)系统管理用户与组。Flowable提供了一个开箱即用的解决方案,简单配置即可将Flowable与LDAP系统连接起来。
早期版本就可以集成LDAP。之后大幅简化了配置,但“老”的LDAP配置方式仍然可用。实际上,简化配置只是对“老”框架进行的包装。
17.1. 使用
在pom.xml中添加下列依赖,为项目中添加LDAP集成代码:
<dependency>
<groupId>org.flowable</groupId>
<artifactId>flowable-ldap-configurator</artifactId>
<version>latest.version</version>
</dependency>17.2. 用途
目前LDAP集成有两大作用:
-
通过IdentityService进行认证。用于由IdentityService处理所有认证业务的场景。
-
获取一个组中的用户。比如,用于查询某用户作为候选组的任务。
17.3. 配置
在流程引擎配置的idmProcessEngineConfigurator小节添加org.flowable.ldap.LDAPConfigurator的实现,进行Flowable与LDAP系统的集成配置。这是个高度可扩展的类:如果默认实现不能满足使用场景,可以轻松地覆盖方法,许多依赖的bean也是可插拔的。
这是一个示例配置(在代码方式创建引擎时完全类似)。目前不需要太关注这些参数,我们会在下一章节详细介绍。
<bean id="processEngineConfiguration" class="...SomeProcessEngineConfigurationClass">
...
<property name="idmProcessEngineConfigurator">
<bean class="org.flowable.ldap.LDAPConfigurator">
<property name="ldapConfiguration">
<bean class="org.flowable.ldap.LDAPConfiguration">
<!-- 服务器连接参数 -->
<property name="server" value="ldap://localhost" />
<property name="port" value="33389" />
<property name="user" value="uid=admin, ou=users, o=flowable" />
<property name="password" value="pass" />
<!-- 查询参数 -->
<property name="baseDn" value="o=flowable" />
<property name="queryUserByUserId" value="(&(objectClass=inetOrgPerson)(uid={0}))" />
<property name="queryUserByFullNameLike" value="(&(objectClass=inetOrgPerson)(|({0}=*{1}*)({2}=*{3}*)))" />
<property name="queryAllUsers" value="(objectClass=inetOrgPerson)" />
<property name="queryGroupsForUser" value="(&(objectClass=groupOfUniqueNames)(uniqueMember={0}))" />
<property name="queryAllGroups" value="(objectClass=groupOfUniqueNames)" />
<!-- 属性配置 -->
<property name="userIdAttribute" value="uid" />
<property name="userFirstNameAttribute" value="cn" />
<property name="userLastNameAttribute" value="sn" />
<property name="userEmailAttribute" value="mail" />
<property name="groupIdAttribute" value="cn" />
<property name="groupNameAttribute" value="cn" />
</bean>
</property>
</bean>
</property>
</bean>17.4. 参数
org.flowable.ldap.LDAPConfiguration使用下列参数:
| 参数名 | 描述 | 类型 | 默认值 |
|---|---|---|---|
server |
LDAP系统的服务器。例如ldap://localhost:33389 |
String |
|
port |
LDAP系统的端口 |
int |
|
user |
LDAP系统的用户id |
String |
|
password |
LDAP系统的密码 |
String |
|
initialContextFactory |
连接LDAP所用的InitialContextFactory |
String |
com.sun.jndi.ldap.LdapCtxFactory |
securityAuthentication |
连接LDAP系统所用的java.naming.security.authentication |
String |
simple |
customConnectionParameters |
用于设置没有配置setter的LDAP连接参数。例如 http://docs.oracle.com/javase/tutorial/jndi/ldap/jndi.html 中的自定义参数,用于配置连接池、安全等。连接LDAP系统时会使用这些参数。 |
Map<String, String> |
|
baseDn |
查询用户及组的基础标识名(distinguished name, DN) |
String |
|
userBaseDn |
查询用户的基础标识名。不设置则使用baseDn(见上) |
String |
|
groupBaseDn |
查询组的基础标识名。不设置则使用baseDn(见上) |
String |
|
searchTimeLimit |
查询LDAP的超时时间,以毫秒计 |
long |
一小时 |
queryUserByUserId |
通过ID查询用户所用的语句。
比如: |
string |
|
queryUserByFullNameLike |
通过全名查询用户所用的语句。
比如: |
string |
|
queryAllUsers |
不使用过滤条件,查询所有用户所用的语句。
比如: |
string |
|
queryGroupsForUser |
查询给定用户所在组所用的语句。
比如: |
string |
|
queryAllGroups |
查询所有组所用的语句。
比如: |
string |
|
userIdAttribute |
代表用户ID的LDAP属性名。用于查询并将LDAP用户对象映射至Flowable用户对象。 |
string |
|
userFirstNameAttribute |
代表用户名字的LDAP属性名。用于查询并将LDAP用户对象映射至Flowable用户对象。 |
string |
|
userLastNameAttribute |
代表用户姓的LDAP属性名。用于查询并将LDAP用户对象映射至Flowable用户对象。 |
string |
|
groupIdAttribute |
代表用户组ID的LDAP属性名。用于查询并将LDAP用户组对象映射至Flowable用户组对象。 |
string |
|
groupNameAttribute |
代表用户组名称的LDAP属性名。用于查询并将LDAP用户组对象映射至Flowable用户组对象。 |
String |
|
groupTypeAttribute |
代表用户组类型的LDAP属性名。用于查询并将LDAP用户组对象映射至Flowable用户组对象 |
String |
下面的参数用于修改默认行为及缓存组:
| 参数名 | 描述 | 类型 | 默认值 |
|---|---|---|---|
ldapUserManagerFactory |
如果默认实现不符合要求,可以设置一个自定义的LDAPUserManagerFactory实现。 |
LDAPUserManagerFactory的实例 |
|
ldapGroupManagerFactory |
如果默认实现不符合要求,可以设置一个自定义的LDAPGroupManagerFactory实现。 |
LDAPGroupManagerFactory的实例 |
|
ldapMemberShipManagerFactory |
如果默认实现不符合要求,可以设置一个自定义的LDAPMembershipManagerFactory实现。请注意很少出现这种情况,一般都使用LDAP系统管理成员信息。 |
LDAPMembershipManagerFactory的实例 |
|
ldapQueryBuilder |
如果默认实现不符合要求,可以设置一个自定义的查询构建器。使用LDAPUserManager或LDAPGroupManage进行LDAP查询时,会使用LDAPQueryBuilder的实例。默认会使用在本实例中设置的参数,例如queryGroupsForUser与queryUserById |
org.flowable.ldap.LDAPQueryBuilder的实例 |
|
groupCacheSize |
设置用户组缓存的尺寸。 这是用户所在组的LRU缓存。避免每次需要查询用户所在组时都访问LDAP系统。 若值小于0,则不会启用缓存。默认值为-1,所以不会进行缓存。 |
int |
-1 |
groupCacheExpirationTime |
设置用户组缓存的过期时间,以毫秒计。如果设置了用户组缓存,在查询了用户所在组后,会缓存用户组关系,持续本参数设置的时间。也就是说,如果在00:00进行了用户所在组查询,过期时间为30分钟,则在00:00 - 00:30间会使用该惠存,00:30之后进行的查询不会使用该缓存,而是会重新查询LDAP系统。 |
long |
一个小时 |
使用活动目录(Active Directory)时请注意:用户报告在使用活动目录时,需要将InitialDirContext设置为Context.REFERRAL。可以通过customConnectionParameters map设置这个参数。
18. 高级
本章介绍的Flowable的高级使用技巧,超出了一般的执行BPMN 2.0流程的范畴。因此,要理解这里讨论的主题,需要对Flowable足够熟练与精通。
18.1. 异步执行器
Flowable V5版本中,在之前的作业执行器(job executor)之外,还提供了异步执行器(async executor)。异步执行器已被许多Flowable的用户及我们自己的跑分证明,性能比老的作业执行器好。
从Flowable V6起,将只提供异步执行器。在V6中,对异步执行器进行了完全的重构,以提升性能及易用性。当然仍然与已有的API兼容。
18.1.1. 异步执行器的设计
Flowable有两种作业类型:定时器(例如边界事件或用户任务中的定时器)以及异步操作(带有flowable:async="true"属性的服务任务)。
定时器很容易理解:保存在ACT_RU_TIMER_JOB表中,并带有给定的到期日期。异步执行器中有一个线程,周期性地检查是否有需要触发的定时器(也就是说,到期日期在当前时间“之前”)。当需要触发定时器时,从JOB表中移除该定时器,并创建一个异步作业(async job)。
异步作业在执行流程实例(即调用API)时插入数据库。如果当前Flowable引擎启用了异步执行器,则该异步作业将被锁定(locked)。即在ACT_RU_JOB表中插入一个作业条目,并设置其lock owner(锁持有人)与lock expiration time(锁到期时间)。在API调用成功后触发的事务监听器(transaction commit listener),将会触发同一引擎中的异步执行器,让其执行该作业(因此可以保证数据库中已经保存了数据)。为此,异步执行器使用(可配置的)线程池,从其中取出线程用于执行作业,并使流程可以异步进行。如果Flowable引擎未启用异步执行器,则异步作业仍会插入ACT_RU_JOB表,但不会被锁定。
与检查定时器的线程类似,异步执行器中也有一个用于“获取”新的异步作业的线程。这里的异步作业,指的是表中存储但未被锁定的作业。这个线程会将这些作业锁定给当前Flowable引擎,并发送至异步执行器。
用于执行作业的线程池从一个内存队列中获取作业。当队列满了时(可配置),作业将会被解锁,并重新存回数据库。这样,其他的异步执行器就可以重新操作它们。
如果在执行作业期间发生了异常,这个异步作业将会转化为一个定时器作业,并带有一个到期日期。之后,它将会像普通定时器作业一样被获取,并重新变回异步作业,以实现重试。当一个作业已经重试了(可配置)几次,仍然失败,则作业被视为“死亡(dead)”,并被移至ACT_RU_DEADLETTER_JOB表。“死信(deadletter)”的概念在各种其他系统中也广泛使用。管理员需要检查失败作业的异常信息,并进行相应操作。
流程定义与流程实例都可以被暂停。这些定义或实例所关联的暂停作业,将被移至ACT_RU_SUSPENDED_JOB表,以确保用于获取作业的查询语句中的where条件尽量少。
综上所述:对于熟悉作业/异步执行器的旧实现的人来说,主要目标是让查询尽可能简单。在过去(V6以前),所有作业类型/状态使用一张表。为了满足所有使用场景,导致“where”条件十分庞大。现在已经解决了这个问题,我们的跑分也证明这个新设计带来了更好的性能,也更有弹性。
18.1.2. 配置异步执行器
异步执行器是一个高度可配置的组件。建议先查看异步执行器的默认配置,检查它们是否符合你的流程的要求。
另外,也可以扩展默认的实现,或者替换为你自己实现的org.flowable.engine.impl.asyncexecutor.AsyncExecutor接口。
可以在流程引擎配置中使用setter设置下列参数:
| 名称 | 默认值 | 描述 |
|---|---|---|
asyncExecutorThreadPoolQueueSize |
100 |
在获取待执行的作业之后,线程池中某个线程实际执行作业之前,放置这些作业的队列的长度。 |
asyncExecutorCorePoolSize |
8 |
用于执行作业的线程池中,最小的活动(kept alive)线程数量。 |
asyncExecutorMaxPoolSize |
8 |
用于执行作业的线程池中,创建线程的最大数量。 |
asyncExecutorThreadKeepAliveTime |
5000 |
在销毁执行作业所用的线程前,需要保持活动的时间(以毫秒计)。设置为>0的值会消耗资源,但在有大量执行作业的时候,可以避免总是创建新线程。如果设置为0,则线程会在执行完作业后立刻被销毁。 |
asyncExecutorNumberOfRetries |
3 |
作业被移入“死信”表之前的最大重试次数。 |
asyncExecutorMaxTimerJobsPerAcquisition |
1 |
在一次获取定时器作业的查询中,获取作业的数量。默认值为1,因为这样可以降低潜在的乐观锁异常情况。较大的数值性能较好,但在不同的引擎间发生乐观锁异常的几率也会变大。 |
asyncExecutorMaxAsyncJobsDuePerAcquisition |
1 |
在一次获取异步作业的查询中,获取作业的数量。默认值为1,因为这样可以降低潜在的乐观锁异常情况。较大的数值性能较好,但在不同的引擎间发生乐观锁异常的几率也会变大。 |
asyncExecutorDefaultTimerJobAcquireWaitTime |
10000 |
获取定时器作业的线程在两次获取作业的查询之间等待的时间(以毫秒记)。只在上一次查询未找到新的定时器作业,或者获取的作业数量少于asyncExecutorMaxTimerJobsPerAcquisition中设置的值时才会等待。 |
asyncExecutorDefaultAsyncJobAcquireWaitTime |
10000 |
获取异步作业的线程在两次获取作业的查询之间等待的时间(以毫秒记)。只在上一次查询未找到新的异步作业,或者获取的作业数量少于asyncExecutorMaxAsyncJobsDuePerAcquisition中设置的值时才会等待。 |
asyncExecutorDefaultQueueSizeFullWaitTime |
0 |
在内部作业队列已满之后,执行下一次查询之前,获取作业(包括定时器作业及异步作业)的线程将等待的时间(以毫秒记)。默认值为0(为保证向后兼容性)。设置为较大的值,可以让异步执行器有机会多执行掉一些队列作业,腾出队列空间。 |
asyncExecutorTimerLockTimeInMillis |
5分钟 |
异步执行器获取定时器作业之后锁定的时间(以毫秒记)。在这段时间内,其它异步执行器不会尝试获取或锁定这个作业。 |
asyncExecutorAsyncJobLockTimeInMillis |
5分钟 |
异步执行器获取异步作业之后锁定的时间(以毫秒记)。在这段时间内,其它异步执行器不会尝试获取或锁定这个作业。 |
asyncExecutorSecondsToWaitOnShutdown |
60 |
当请求关闭执行器(或流程引擎)后,等待执行作业的线程池安全关闭的时间(以秒记)。 |
asyncExecutorResetExpiredJobsInterval |
60秒 |
在两次超时作业(expired job)检查之间等待的时间(以毫秒记)。超时作业指的是已经锁定(某个执行器已经为其写入了锁持有人以及超时时间),但一直没有完成的作业。在检查中,会解锁超时作业,即移除其锁持有人以及超时时间。这样其他执行器就可以重新获取它。作业的锁超时时间在当前时间之前则视作超时。 |
asyncExecutorResetExpiredJobsPageSize |
3 |
异步执行器的超时重置(reset expired)检查线程一次获取的作业数量。 |
18.1.3. 基于消息队列的异步执行器
阅读异步执行器的设计章节之后,很明显架构的灵感来自消息队列。异步执行器设计思路保证了可以很轻松地用消息队列代替线程池的工作,处理异步作业。
跑分显示,相比基于线程池的异步执行器,消息队列性能出众,吞吐量大。但需要额外的中间件,当然也就增加了安装配置、维护及监控的复杂度。对于多数用户来说,基于线程池的异步执行器性能已经足够用了。但能够知道在性能要求增长之后,仍有改进方案,也是挺好的。
目前,唯一直接可用的是带有JMS的Spring。选择首先支持Spring的原因是,Spring提供了非常好的功能,解决了使用线程以及处理多个消息消费者造成的麻烦。但是其实集成也很简单,因此可以轻松改用任何其他消息队列实现或协议(Stomp、AMPQ等等)。我们欢迎用户反馈下一个应该支持什么消息队列。
使用消息队列后,当引擎创建新的异步作业时,会在消息队列中放入一条包含有作业标识的消息(处在一个事务提交监听器中,这样就可以确保该作业条目已经提交至数据库)。之后消息消费者可以获取作业标识,并获取及执行该作业。异步执行器不再创建线程池,而是会在另一个单独线程中插入及查询定时器。当定时器到时触发时,将会被移至异步作业表,同时向消息队列发送一条消息。消息队列也可能失败,所以超时重置线程会按照原逻辑处理。只不过不是解锁作业,而是重发消息。异步执行器不再轮询异步作业。
主要由两个类实现:
-
org.flowable.engine.impl.asyncexecutor.JobManager接口的实现,将消息发送至消息队列而不是线程池。
-
javax.jms.MessageListener接口的实现。从消息队列中消费消息,并使用消息中的作业标识获取及执行该作业。
首先添加flowable-jms-spring-executor依赖:
<dependency>
<groupId>org.flowable</groupId>
<artifactId>flowable-jms-spring-executor</artifactId>
<version>${flowable.version}</version>
</dependency>在流程引擎配置中进行如下设置启用基于消息队列的异步执行器:
-
asyncExecutorActivate为true
-
asyncExecutorMessageQueueMode为true
-
org.flowable.spring.executor.jms.MessageBasedJobManager注入为JobManager
下面是一个基于Java配置的完整例子,使用ActiveMQ作为消息中间件。
请注意:
-
需要为MessageBasedJobManager注入一个配置了正确的connectionFactory的JMSTemplate。
-
我们使用Spring的MessageListenerContainer,因为它大幅简化了线程与多消费者的使用。
@Configuration
public class SpringJmsConfig {
@Bean
public DataSource dataSource() {
// 略
}
@Bean(name = "transactionManager")
public PlatformTransactionManager transactionManager(DataSource dataSource) {
DataSourceTransactionManager transactionManager = new DataSourceTransactionManager();
transactionManager.setDataSource(dataSource);
return transactionManager;
}
@Bean
public SpringProcessEngineConfiguration processEngineConfiguration(DataSource dataSource, PlatformTransactionManager transactionManager,
JobManager jobManager) {
SpringProcessEngineConfiguration configuration = new SpringProcessEngineConfiguration();
configuration.setDataSource(dataSource);
configuration.setTransactionManager(transactionManager);
configuration.setDatabaseSchemaUpdate(SpringProcessEngineConfiguration.DB_SCHEMA_UPDATE_TRUE);
configuration.setAsyncExecutorMessageQueueMode(true);
configuration.setAsyncExecutorActivate(true);
configuration.setJobManager(jobManager);
return configuration;
}
@Bean
public ProcessEngine processEngine(ProcessEngineConfiguration processEngineConfiguration) {
return processEngineConfiguration.buildProcessEngine();
}
@Bean
public MessageBasedJobManager jobManager(JmsTemplate jmsTemplate) {
MessageBasedJobManager jobManager = new MessageBasedJobManager();
jobManager.setJmsTemplate(jmsTemplate);
return jobManager;
}
@Bean
public ConnectionFactory connectionFactory() {
ActiveMQConnectionFactory activeMQConnectionFactory = new ActiveMQConnectionFactory("tcp://localhost:61616");
activeMQConnectionFactory.setUseAsyncSend(true);
activeMQConnectionFactory.setAlwaysSessionAsync(true);
return new CachingConnectionFactory(activeMQConnectionFactory);
}
@Bean
public JmsTemplate jmsTemplate(ConnectionFactory connectionFactory) {
JmsTemplate jmsTemplate = new JmsTemplate();
jmsTemplate.setDefaultDestination(new ActiveMQQueue("flowable-jobs"));
jmsTemplate.setConnectionFactory(connectionFactory);
return jmsTemplate;
}
@Bean
public MessageListenerContainer messageListenerContainer(JobMessageListener jobMessageListener) {
DefaultMessageListenerContainer messageListenerContainer = new DefaultMessageListenerContainer();
messageListenerContainer.setConnectionFactory(connectionFactory());
messageListenerContainer.setDestinationName("flowable-jobs");
messageListenerContainer.setMessageListener(jobMessageListener);
messageListenerContainer.setConcurrentConsumers(2);
messageListenerContainer.start();
return messageListenerContainer;
}
@Bean
public JobMessageListener jobMessageListener(ProcessEngineConfiguration processEngineConfiguration) {
JobMessageListener jobMessageListener = new JobMessageListener();
jobMessageListener.setProcessEngineConfiguration(processEngineConfiguration);
return jobMessageListener;
}
}在上面的代码中,flowable-jms-spring-executor模块提供的只有JobMessageListener与MessageBasedJobManager两个类。其他的所有代码都来自Spring。因此,如果想要替换为其他的队列/协议,就需要替换这些类。
18.2. 深入流程解析
BPMN 2.0 XML需要解析为Flowable的内部模型,才能在Flowable引擎中执行。部署流程时,或是在内存中找不到流程时,会从数据库中读取XML并进行解析。
BpmnParser类会为每个流程创建一个BpmnParser实例,作为解析过程的容器。解析本身很简单:引擎对于每一个BPMN 2.0元素都有一个对应的org.flowable.engine.parse.BpmnParseHandler的实例,解析器将BPMN 2.0元素类映射至BpmnParseHandler实例。默认情况下,Flowable使用BpmnParseHandler实例处理所有支持的元素,并为流程的步骤附加执行监听器,以创建历史。
可以在Flowable引擎中添加org.flowable.engine.parse.BpmnParseHandler的自定义实例。比如常见使用场景是,为特定步骤添加执行监听器,向某个事件处理队列发送事件。Flowable处理历史就使用的是这种方式。要添加这种自定义处理器,需要调整Flowable配置:
<property name="preBpmnParseHandlers">
<list>
<bean class="org.flowable.parsing.MyFirstBpmnParseHandler" />
</list>
</property>
<property name="postBpmnParseHandlers">
<list>
<bean class="org.flowable.parsing.MySecondBpmnParseHandler" />
<bean class="org.flowable.parsing.MyThirdBpmnParseHandler" />
</list>
</property>在preBpmnParseHandlers参数中配置的BpmnParseHandler实例将添加在默认处理器之前。类似的,postBpmnParseHandlers中实例将添加在默认处理器之后。有时顺序会影响自定义解析处理器中包含的逻辑,需要特别注意。
org.flowable.engine.parse.BpmnParseHandler是一个简单的接口:
public interface BpmnParseHandler {
Collection<Class>? extends BaseElement>> getHandledTypes();
void parse(BpmnParse bpmnParse, BaseElement element);
}getHandledTypes()方法返回该解析器处理的所有类型的集合。集合的泛型提示,可用的类型是BaseElement的子类。也可以扩展AbstractBpmnParseHandler类,并覆盖getHandledType()方法,它只返回一个类而不是一个集合。这个类也包含了一些默认解析处理器通用的辅助方法。当解析器遇到匹配该方法的返回类型的元素时,将调用这个BpmnParseHandler实例进行解析。在下面的例子里,当遇到BPMN 2.0 XML中的流程元素时,就会执行其executeParse方法(这是一个类型转换方法,替代BpmnParseHandler接口中的普通parse方法)中的逻辑。
public class TestBPMNParseHandler extends AbstractBpmnParseHandler<Process> {
protected Class<? extends BaseElement> getHandledType() {
return Process.class;
}
protected void executeParse(BpmnParse bpmnParse, Process element) {
..
}
}重要提示:在实现自定义解析处理器时,不要使用任何用于解析BPMN 2.0结构的内部类。否则会很难查找bug。安全的做法是实现BpmnParseHandler接口,或扩展内部抽象类org.flowable.engine.impl.bpmn.parser.handler.AbstractBpmnParseHandler。
可以(但不常用)替换默认用于将BPMN 2.0元素解析为Flowable内部模型的BpmnParseHandler实例。可以通过下面的代码片段实现:
<property name="customDefaultBpmnParseHandlers">
<list>
...
</list>
</property>简单的例子,强制所有服务任务都异步执行:
public class CustomUserTaskBpmnParseHandler extends ServiceTaskParseHandler {
protected void executeParse(BpmnParse bpmnParse, ServiceTask serviceTask) {
// 进行常规操作
super.executeParse(bpmnParse, serviceTask);
// 保证异步执行
serviceTask.setAsynchronous(true);
}
}18.3. 高并发下使用的UUID ID生成器
在某些(非常)高并发负载的情况下,默认的ID生成器可能会由于不能足够快地获取新的id块而产生异常。每个流程引擎都有一个ID生成器。默认的ID生成器会在数据库中保存一块ID,这样其他引擎就不能使用同一个块中的ID。引擎运行时,当ID生成器发现ID块已经用完,就会启动一个新的事务,来获取一个新的块。在(非常)有限的使用场景下,当负载非常高时可能导致问题。对于大多数用例来说,默认的ID生成器已经足够使用了。默认的org.flowable.engine.impl.db.DbIdGenerator也有一个idBlockSize参数,用于配置保留的ID块的大小,调整获取ID的行为。
可以使用org.flowable.engine.impl.persistence.StrongUuidGenerator替换默认的ID生成器。它会在本地生成唯一的UUID,并将其用于所有实体的标识符。因为UUID不需要访问数据库就能生成,因此在非常高并发的使用场景下更合适。请注意取决于机器,性能可能与默认的ID生成器不同(更好更坏都有可能)。
可以在flowable配置中,像下面这样配置UUID生成器:
<property name="idGenerator">
<bean class="org.flowable.engine.impl.persistence.StrongUuidGenerator" />
</property>使用UUID id生成器需要添加下列额外依赖:
<dependency>
<groupId>com.fasterxml.uuid</groupId>
<artifactId>java-uuid-generator</artifactId>
<version>3.1.3</version>
</dependency>18.4. 多租户
总的来说,多租户是指一个软件为多个不同组织提供服务。其核心是数据隔离,一个组织不能看到其他组织的数据。在这个语境中,一个这样的组织(或部门、团队,等等)被称为一个租户(tenant)。
请注意它与多实例部署有本质区别。多实例部署是指每一个组织都分别运行一个Flowable流程引擎实例(且使用不同的数据库账户)。尽管Flowable比较轻量级,运行一个流程引擎实例不会花费太多资源,但多实例部署仍然增加了复杂度与维护量。但是,在某些使用场景中,多实例部署可能是正确的解决方案。
Flowable中的多租户主要围绕着隔离数据实现。要注意Flowable并不强制多租户规则。换句话说,查询与使用数据时,不会验证进行操作的用户是否属于正确的租户。这应该在调用Flowable引擎的层次实现。Flowable负责确保可以存储租户信息,并可在获取流程数据时使用。
在Flowable流程引擎中部署流程定义时,可以传递一个租户标识符(tenant identifier)。这是一个字符串(可以是UUID,部门id,等等……),限制为256个字符长,唯一标识一个租户:
repositoryService.createDeployment()
.addClassPathResource(...)
.tenantId("myTenantId")
.deploy();在部署时传入一个租户ID意味着:
-
部署中包含的所有流程定义都将从该部署继承租户标识符。
-
从这些流程定义启动的所有流程实例都将从流程定义继承租户标识符。
-
在执行流程实例时,创建所有任务都将从流程实例继承租户标识符。独立任务也可以有租户标识符。
-
执行流程实例时,创建的所有执行都将从流程实例继承租户标识符。
-
(在流程内或通过API)触发信号抛出事件时可以提供租户标识符。这个信号将只在该租户的上下文中执行。也就是说,如果有多个使用相同名字的信号捕获事件,只会触发带有正确租户标识符的捕获事件。
-
所有作业(定时器与异步操作)要么从流程定义(如定时器启动事件),要么从流程实例(运行时创建的作业,如异步操作)继承租户标识符。这样就可以在自定义作业执行器中,为租户设置优先级。
-
所有历史实体(历史流程实例、任务与活动)都从其对应的运行时对象继承租户标识符。
-
另外,模型也可以有租户标识符(模型用于Flowable Modeler存储BPMN 2.0)。
所有查询API都可以通过租户标识符进行过滤。例如(也可以换成其他实体的查询):
runtimeService.createProcessInstanceQuery()
.processInstanceTenantId("myTenantId")
.processDefinitionKey("myProcessDefinitionKey")
.variableValueEquals("myVar", "someValue")
.list()查询API也可以使用like语义通过租户标识符过滤,也可以过滤掉没有租户标识符的实体。
重要的实现细节:由于数据库的原因(更确切地说,对唯一约束中null的处理),默认的代表没有租户的租户标识符为空字符串。这是因为(流程定义key,流程定义版本,租户标识符)的组合需要是唯一的(由数据库约束保证)。也请注意租户标识符不能设置为null,不然会影响查询,因为某些数据库(Oracle)会将空字符串当做null值处理(这也就是为什么.withoutTenantId查询不检查空字符串还是null)。所以可以为多个租户部署(有相同的流程定义key的)同一个流程定义,并且每一个租户都有他们自己的版本。不影响未使用租户时的使用方式。
请注意,集群运行多个Flowable实例与上面所说不冲突。
[实验性] 可以调用repositoryService的changeDeploymentTenantId(String deploymentId, String newTenantId)方法修改租户标识符。并将连带修改每一处之前继承的租户标识符。在从非多租户环境迁移至多租户部署时很有用。查看该方法的Javadoc了解更多信息。
18.5. 执行自定义SQL
Flowable提供了与数据库交互的高级API。例如,要获取数据,查询API与原生(Native)查询API各有用武之地。但有时会需要更高的灵活性。下面介绍如何在Flowable流程引擎范围内(所以可以使用相同的事务设置等)的数据存储中,执行完全自定义的SQL语句(select、insert、update与delete都可以)。
Flowable引擎使用其底层框架MyBatis的功能自定义SQL语句。可以在MyBatis用户手册找到更多信息。
18.5.1. 基于注解的映射语句
使用基于注解的映射语句(Annotation based Mapped Statement)时,首先要做的是创建一个MyBatis映射类。例如,假设在某个用例中,不需要完整的任务数据,而只需要其中很少一部分,就可以通过映射类(Mapper)完成,像是这样:
public interface MyTestMapper {
@Select("SELECT ID_ as id, NAME_ as name, CREATE_TIME_ as createTime FROM ACT_RU_TASK")
List<Map<String, Object>> selectTasks();
}必须像下面这样为流程引擎配置映射类:
...
<property name="customMybatisMappers">
<set>
<value>org.flowable.standalone.cfg.MyTestMapper</value>
</set>
</property>
...请注意这是一个接口。底层的MyBatis框架会构造一个它的实例,并在运行时使用。也请注意方法的返回值没有类型,而只是一个map的list(代表了带有列数据的行的列表)。如果需要,可以通过MyBatis映射类设置类型。
使用managementService.executeCustomSql方法执行上面的查询。这个方法使用CustomSqlExecution的实例作为包装器,将引擎需要处理的内部数据隐藏起来。
不幸的是,Java泛型降低了可读性。下面的两个泛型类是映射类与其返回类型类。只是简单的调用映射方法,并返回其结果(若有)。
CustomSqlExecution<MyTestMapper, List<Map<String, Object>>> customSqlExecution =
new AbstractCustomSqlExecution<MyTestMapper, List<Map<String, Object>>>(MyTestMapper.class) {
public List<Map<String, Object>> execute(MyTestMapper customMapper) {
return customMapper.selectTasks();
}
};
List<Map<String, Object>> results = managementService.executeCustomSql(customSqlExecution);在这个例子里,上面列出的Map只包含id, name与创建时间,而不是完整的任务对象。
按照上面的方法可以使用任何SQL。另一个更复杂的例子:
@Select({
"SELECT task.ID_ as taskId, variable.LONG_ as variableValue FROM ACT_RU_VARIABLE variable",
"inner join ACT_RU_TASK task on variable.TASK_ID_ = task.ID_",
"where variable.NAME_ = #{variableName}"
})
List<Map<String, Object>> selectTaskWithSpecificVariable(String variableName);任务表join变量表,只选择变量有特定名字的记录,并返回任务id与对应的数字值。
请参考单元测试org.flowable.standalone.cfg.CustomMybatisMapperTest及src/test/java/org/flowable/standalone/cfg/与src/test/resources/org/flowable/standalone/cfg/目录中的其它类与资源,了解基于注解的映射语句的更多使用例子。
18.5.2. 基于XML的映射语句
可以使用基于XML的映射语句(XML based Mapped Statement),在XML文件中定义语句。对于不需要完整的任务数据,而只需要其中很少一部分数据的用例,XML文件像是下面这样:
<mapper namespace="org.flowable.standalone.cfg.TaskMapper">
<resultMap id="customTaskResultMap" type="org.flowable.standalone.cfg.CustomTask">
<id property="id" column="ID_" jdbcType="VARCHAR"/>
<result property="name" column="NAME_" jdbcType="VARCHAR"/>
<result property="createTime" column="CREATE_TIME_" jdbcType="TIMESTAMP" />
</resultMap>
<select id="selectCustomTaskList" resultMap="customTaskResultMap">
select RES.ID_, RES.NAME_, RES.CREATE_TIME_ from ACT_RU_TASK RES
</select>
</mapper>结果映射为如下的org.flowable.standalone.cfg.CustomTask类的实例:
public class CustomTask {
protected String id;
protected String name;
protected Date createTime;
public String getId() {
return id;
}
public String getName() {
return name;
}
public Date getCreateTime() {
return createTime;
}
}必须像下面这样为流程引擎配置提供映射XML文件:
...
<property name="customMybatisXMLMappers">
<set>
<value>org/flowable/standalone/cfg/custom-mappers/CustomTaskMapper.xml</value>
</set>
</property>
...这样执行语句:
List<CustomTask> tasks = managementService.executeCommand(new Command<List<CustomTask>>() {
@SuppressWarnings("unchecked")
@Override
public List<CustomTask> execute(CommandContext commandContext) {
return (List<CustomTask>) CommandContextUtil.getDbSqlSession().selectList("selectCustomTaskList");
}
});XML映射语句在需要更复杂语句的时候很好用。Flowable内部就使用XML映射语句,所以能使用底层功能。
假设某个用例下,需要基于id、name、type、userId等字段,查询附件数据。要实现这个用例,可以创建下面这样的扩展了org.flowable.engine.impl.AbstractQuery的查询类AttachmentQuery:
public class AttachmentQuery extends AbstractQuery<AttachmentQuery, Attachment> {
protected String attachmentId;
protected String attachmentName;
protected String attachmentType;
protected String userId;
public AttachmentQuery(ManagementService managementService) {
super(managementService);
}
public AttachmentQuery attachmentId(String attachmentId){
this.attachmentId = attachmentId;
return this;
}
public AttachmentQuery attachmentName(String attachmentName){
this.attachmentName = attachmentName;
return this;
}
public AttachmentQuery attachmentType(String attachmentType){
this.attachmentType = attachmentType;
return this;
}
public AttachmentQuery userId(String userId){
this.userId = userId;
return this;
}
@Override
public long executeCount(CommandContext commandContext) {
return (Long) CommandContextUtil.getDbSqlSession()
.selectOne("selectAttachmentCountByQueryCriteria", this);
}
@Override
public List<Attachment> executeList(CommandContext commandContext, Page page) {
return CommandContextUtil.getDbSqlSession()
.selectList("selectAttachmentByQueryCriteria", this);
}请注意在扩展AbstractQuery时,子类需要为super构造函数传递一个ManagementService的实例,并需要实现executeCount与executeList来调用映射语句。
包含映射语句的XML文件如下:
<mapper namespace="org.flowable.standalone.cfg.AttachmentMapper">
<select id="selectAttachmentCountByQueryCriteria" parameterType="org.flowable.standalone.cfg.AttachmentQuery" resultType="long">
select count(distinct RES.ID_)
<include refid="selectAttachmentByQueryCriteriaSql"/>
</select>
<select id="selectAttachmentByQueryCriteria" parameterType="org.flowable.standalone.cfg.AttachmentQuery" resultMap="org.flowable.engine.impl.persistence.entity.AttachmentEntity.attachmentResultMap">
${limitBefore}
select distinct RES.* ${limitBetween}
<include refid="selectAttachmentByQueryCriteriaSql"/>
${orderBy}
${limitAfter}
</select>
<sql id="selectAttachmentByQueryCriteriaSql">
from ${prefix}ACT_HI_ATTACHMENT RES
<where>
<if test="attachmentId != null">
RES.ID_ = #{attachmentId}
</if>
<if test="attachmentName != null">
and RES.NAME_ = #{attachmentName}
</if>
<if test="attachmentType != null">
and RES.TYPE_ = #{attachmentType}
</if>
<if test="userId != null">
and RES.USER_ID_ = #{userId}
</if>
</where>
</sql>
</mapper>可以在语句中使用例如分页、排序、表名前缀等功能(因为parameterType为AbstractQuery的子类)。可以使用引擎定义的org.flowable.engine.impl.persistence.entity.AttachmentEntity.attachmentResultMap来映射结果。
最后,可以这样使用AttachmentQuery:
....
// 获取附件的总数
long count = new AttachmentQuery(managementService).count();
// 获取id为10025的附件
Attachment attachment = new AttachmentQuery(managementService).attachmentId("10025").singleResult();
// 获取前10个附件
List<Attachment> attachments = new AttachmentQuery(managementService).listPage(0, 10);
// 获取用户kermit上传的所有附件
attachments = new AttachmentQuery(managementService).userId("kermit").list();
....请参考单元测试org.flowable.standalone.cfg.CustomMybatisXMLMapperTest_及src/test/java/org/flowable/standalone/cfg/与src/test/resources/org/flowable/standalone/cfg/目录中的其它类与资源,了解基于XML的映射语句的更多使用例子。
18.6. 使用ProcessEngineConfigurator进行高级流程引擎配置
深入控制流程引擎配置的高级方法是使用ProcessEngineConfigurator。创建一个org.flowable.engine.cfg.ProcessEngineConfigurator接口的实现,并将它注入到流程引擎配置中:
<bean id="processEngineConfiguration" class="...SomeProcessEngineConfigurationClass">
...
<property name="configurators">
<list>
<bean class="com.mycompany.MyConfigurator">
...
</bean>
</list>
</property>
...
</bean>这个接口需要实现两个方法。configure方法,使用一个ProcessEngineConfiguration实例作为参数。可以使用这个方式添加自定义配置,并且这个方法会保证在流程引擎创建之前,所有默认配置已经完成之后被调用。另一个方法是getPriority方法,可以指定配置器的顺序,以备某些配置器对其他的有依赖。
这种配置器的一个例子是集成LDAP,使用配置器将默认的用户与组管理类替换为可以处理LDAP用户的实现。可见配置器可以相当大程度地改变及调整流程引擎,以适应非常高级的使用场景。另一个例子是使用自定义的缓存替换流程引擎缓存:
public class ProcessDefinitionCacheConfigurator extends AbstractProcessEngineConfigurator {
public void configure(ProcessEngineConfigurationImpl processEngineConfiguration) {
MyCache myCache = new MyCache();
processEngineConfiguration.setProcessDefinitionCache(enterpriseProcessDefinitionCache);
}
}也可以使用ServiceLoader的方法,从classpath中自动发现流程引擎配置器。也就是说必须将包含配置器实现的jar放在classpath下,并且jar的META-INF/services目录下需要有名为org.flowable.engine.cfg.ProcessEngineConfigurator的文件,内容是自定义实现的全限定类名。当流程引擎启动时,日志会提示找到这些配置器:
INFO org.flowable.engine.impl.cfg.ProcessEngineConfigurationImpl - Found 1 auto-discoverable Process Engine Configurators INFO org.flowable.engine.impl.cfg.ProcessEngineConfigurationImpl - Found 1 Process Engine Configurators in total: INFO org.flowable.engine.impl.cfg.ProcessEngineConfigurationImpl - class org.flowable.MyCustomConfigurator
请注意某些环境下可能不能使用ServiceLoader方法。可以通过ProcessEngineConfiguration的enableConfiguratorServiceLoader参数显式禁用(默认为true)。
18.7. 高级查询API:在运行时与历史任务查询间无缝切换
BPM用户界面的核心组件是任务列表。一般来说,最终用户执行待办任务,通过不同方式过滤收件箱中的任务。有时也需要在列表中显示历史任务,并进行类似的过滤。为了简化代码,TaskQuery与HistoricTaskInstanceQuery有共同的父接口,其中包含了所有公共操作(大多数操作都是公共的)。
这个公共接口是org.flowable.engine.task.TaskInfoQuery类。org.flowable.engine.task.Task与org.flowable.engine.task.HistoricTaskInstance都有公共父类org.flowable.engine.task.TaskInfo(并带有公共参数),作为list()等方法的返回值。然而,有时Java泛型会帮倒忙:如果想要直接使用TaskInfoQuery类型,将会像是这样:
TaskInfoQuery<? extends TaskInfoQuery<?,?>, ? extends TaskInfo> taskInfoQuery呃……好吧。为了“解决”这个问题,可以使用org.flowable.engine.task.TaskInfoQueryWrapper类来避免泛型(下面的代码来自REST的代码,将返回一个任务列表,且用户可以选择查看进行中还是已完成的任务):
TaskInfoQueryWrapper taskInfoQueryWrapper = null;
if (runtimeQuery) {
taskInfoQueryWrapper = new TaskInfoQueryWrapper(taskService.createTaskQuery());
} else {
taskInfoQueryWrapper = new TaskInfoQueryWrapper(historyService.createHistoricTaskInstanceQuery());
}
List<? extends TaskInfo> taskInfos = taskInfoQueryWrapper.getTaskInfoQuery().or()
.taskNameLike("%k1%")
.taskDueAfter(new Date(now.getTime() + (3 * 24L * 60L * 60L * 1000L)))
.endOr()
.list();18.8. 通过覆盖标准SessionFactory自定义身份管理
如果不想像集成LDAP中那样使用完整的ProcessEngineConfigurator实现,但仍然希望在框架中插入自定义的身份管理,也可以覆盖IdmIdentityServiceImpl类,或者直接实现IdmIdentityService接口,并使用实现类作为ProcessEngineConfiguration中的idmIdentityService参数。在Spring中,可以简单地向ProcessEngineConfigurationbean定义添加下面的代码实现:
<bean id="processEngineConfiguration" class="...SomeProcessEngineConfigurationClass">
...
<property name="idmIdentityService">
<bean class="com.mycompany.IdmIdentityServiceBean"/>
</property>
...
</bean>LDAPIdentityServiceImpl类是一个介绍如何实现IdmIdentityService接口中方法的很好的例子。你需要自行判断需要在自定义身份服务类中实现什么方法。例如下面的调用:
long potentialOwners = identityService.createUserQuery().memberOfGroup("management").count();会调用IdmIdentityService接口的下列成员:
UserQuery createUserQuery();集成LDAP中的代码包含了如何实现这些的完整示例。可以在GitHub查看代码:LDAPIdentityServiceImpl。
18.9. 启用安全BPMN 2.0 XML
在大多数情况下,部署至Flowable引擎的BPMN 2.0流程处在开发团队等的严格控制下。然而,有的时候会希望能够向引擎上传任意的BPMN 2.0 XML。在这种情况下,需要考虑动机不良的用户可能会像这里描述的一样,破坏服务器。
要避免上面链接中描述的攻击,可以在流程引擎配置中设置enableSafeBpmnXml参数:
<property name="enableSafeBpmnXml" value="true"/>默认情况下这个功能是禁用的!原因是它依赖StaxSource类。而不幸的是,某些平台(JDK6,JBoss等)不能使用这个类(由于使用的是过时的XML解析器),因此不能启用安全BPMN 2.0 XML功能。
如果运行Flowable的平台支持,请一定要启用这个功能。
18.10. 事件日志
Flowable引入了事件日志机制。日志机制基于Flowable引擎的事件机制,并默认禁用。总的来说,来源于引擎的事件会被捕获,并创建一个包含了所有事件数据(甚至更多)的map,提供给org.flowable.engine.impl.event.logger.EventFlusher,由它将这些数据保存其他地方。默认情况下,使用简单的基于数据库的事件处理器/保存器,用Jackson将上述map序列化为JSON,并将其作为EventLogEntryEntity实例存入数据库。默认会在数据库中创建ACT_EVT_LOG表保存事件日志。如果不使用事件日志,可以删除这个表。
要启用数据库记录器:
processEngineConfigurationImpl.setEnableDatabaseEventLogging(true);或在运行时:
databaseEventLogger = new EventLogger(processEngineConfiguration.getClock(),
processEngineConfiguration.getObjectMapper());
runtimeService.addEventListener(databaseEventLogger);如果默认的数据库记录不符合要求,可以扩展EventLogger类。createEventFlusher()方法需要返回org.flowable.engine.impl.event.logger.EventFlusher接口的实例。可以使用managementService.getEventLogEntries(startLogNr, size);获取EventLogEntryEntity实例。
显然,这个表中的数据也可以JSON的形式存入NoSQL存储,如MongoDB,Elastic Search等。也容易看出这里使用的类(org.flowable.engine.impl.event.logger.EventLogger/EventFlusher与许多其他EventHandler类)是可插拔的,可以按你的使用场景调整。(比如将JSON直接发送给队列或NoSQL,而不存入数据库)
请注意这个事件日志机制是独立于Flowable的“传统”历史管理器的。尽管所有数据都保存在数据库表中,但并未对查询或快速恢复做优化。实际使用场景主要是审计及存入大数据存储。
18.11. 禁用批量插入
默认情况下,引擎会将对同一个数据库表的多个插入语句组合在一起,作为批量插入。这样能够提高性能,并已在所有支持的数据库中实现及测试。
然而,即使是支持及测试过的数据库,也可能有某个特定版本不支持批量插入(例如有报告说DB2在z/OS上不支持,尽管一般来说DB2是支持的)。这时可以在流程引擎配置中禁用批量插入:
<property name="bulkInsertEnabled" value="false" />18.12. 安全脚本
默认情况下,使用脚本任务时,执行的脚本与Java代码具有相似的能力。可以完全访问JVM,永远运行(无限循环),或占用大量内存。
相较而言,Java代码需要放在classpath的jar中,与流程定义的生命周期不一样。最终用户一般不会撰写Java代码,这基本上是开发者的工作。
而脚本是流程定义的一部分,生命周期一致。脚本任务不需要额外的jar部署步骤,而是在流程部署后就可以执行。有时,脚本任务中的脚本不是由开发者撰写的。所以会产生这个问题:脚本可以完全访问JVM,也可以在执行脚本时阻塞许多系统资源。因此允许执行来自任何人的脚本并不是一个好主意。
可以启用安全脚本功能解决这个问题。目前,这个功能只实现了javascript脚本,在项目中添加flowable-secure-javascript依赖启用。Maven:
<dependency>
<groupId>org.flowable</groupId>
<artifactId>flowable-secure-javascript</artifactId>
<version>${flowable.version}</version>
</dependency>添加这个依赖会同时引入Rhino依赖(参见https://developer.mozilla.org/en-US/docs/Mozilla/Projects/Rhino)。Rhino是一个用于JDK的javascript引擎。过去包含在JDK6与7中,并已被Nashorn引擎取代。然而,Rhino项目仍然在继续开发。许多(包括Flowable用于实现安全脚本的)功能都在之后才加入。在撰写本手册的时候,Nashorn还没有实现安全脚本功能需要的功能。
这意味着脚本可能存在一些(基本很少)区别(例如,Rhino使用importPackage,而Nashorn使用load())。
通过专门的Configurator对象配置安全脚本,并在流程引擎实例化之前将其传递给流程引擎配置:
SecureJavascriptConfigurator configurator = new SecureJavascriptConfigurator()
.setWhiteListedClasses(new HashSet<String>(Arrays.asList("java.util.ArrayList")))
.setMaxStackDepth(10)
.setMaxScriptExecutionTime(3000L)
.setMaxMemoryUsed(3145728L)
.setNrOfInstructionsBeforeStateCheckCallback(10);
processEngineConfig.addConfigurator(configurator);可以使用下列设置:
-
enableClassWhiteListing: 为true时,会将所有类加入黑名单。需要在白名单中添加希望运行的所有类,严格控制暴露给脚本的东西。默认为false。
-
whiteListedClasses: 一个全限定类名字符串的集合,表示允许在脚本中使用的类。例如,要在脚本中使用execution对象,需要在这个集合中添加org.flowable.engine.impl.persistence.entity.ExecutionEntityImpl字符串。默认为空。
-
maxStackDepth: 限制在脚本中调用函数时的最大栈深度。可以用于避免在脚本中递归调用方法而导致的栈溢出异常。默认为-1(禁用)。
-
maxScriptExecutionTime: 脚本允许运行的最大时间。默认为-1(禁用)。
-
maxMemoryUsed: 脚本允许使用的最大内存数量,以字节计。请注意脚本引擎自己也要需要一定量的内存,也会算在这里。默认为-1(禁用)。
-
nrOfInstructionsBeforeStateCheckCallback: 脚本每执行x个指令,就通过回调函数进行一次脚本执行时间与内存检测。请注意这不是指脚本指令,而是指java字节码指令(一行脚本可能有上百行字节码指令)。默认为100。
请注意:maxMemoryUsed设置只能用于支持com.sun.management.ThreadMXBean#getThreadAllocatedBytes()方法的JVM,如Oracle JDK。
ScriptExecutionListener与ScriptTaskListener也有安全形式:org.flowable.scripting.secure.listener.SecureJavascriptExecutionListener与org.flowable.scripting.secure.listener.SecureJavascriptTaskListener。
像这样使用:
<flowable:executionListener event="start" class="org.flowable.scripting.secure.listener.SecureJavascriptExecutionListener">
<flowable:field name="script">
<flowable:string>
<![CDATA[
execution.setVariable('test');
]]>
</flowable:string>
</flowable:field>
<flowable:field name="language" stringValue="javascript" />
</flowable:executionListener>可以通过GitHub上的单元测试, 查看不安全脚本以及通过安全脚本功能将其变得安全的例子,
19. 工具
19.1. JMX
19.1.1. 介绍
可以使用标准Java管理扩展(Java Management Extensions, JMX)技术连接Flowable引擎,查询信息或修改配置。任何符合标准的JMX客户端都可以使用。通过JMX可以完成启用与禁用作业执行器、部署新的流程定义文件或删除流程等操作,而不需要写一行代码。
19.1.2. 快速开始
默认情况下没有启用JMX。用Maven或其他方法将flowable-jmx jar文件加入classpath即可使用默认配置启动JMX。如果使用Maven,可以在pom.xml中添加下列依赖:
<dependency>
<groupId>org.flowable</groupId>
<artifactId>flowable-jmx</artifactId>
<version>latest.version</version>
</dependency>在添加依赖并启动流程引擎后,就可以使用JMX进行连接了。可以使用在标准JDK发行版中提供的jconsole。在本地线程列表中,可以找到运行Flowable的JVM。如果在“本地进程”中没有列出Flowable的JVM,可以尝试使用这个URL从“远程进程”中连接:
service:jmx:rmi:///jndi/rmi://localhost:1099/jmxrmi/flowable
可以在日志文件中找到正确的本地URL。连接成功后,可以看到标准的JVM信息以及MBean。选择MBeans页签,并在右侧面板选择"org.flowable.jmx.Mbeans",查看Flowable的MBean。选择任何MBean,都可以查询相应的信息或修改配置。如下图所示:
不只是jconsole,任何JMX客户端都可以访问MBeans。大多数数据中心的监控工具都会提供连接至JMX MBeans的连接器。
19.1.3. 属性与操作
下表是目前可用的属性与操作的列表。这个列表可能根据需要在未来版本中扩展。
| MBean | 类型 | 名字 | 描述 |
|---|---|---|---|
ProcessDefinitionsMBean |
属性 |
processDefinitions |
已部署流程定义的 |
属性 |
deployments |
当前部署的 |
|
方法 |
getProcessDefinitionById(String id) |
给定id流程定义的 |
|
方法 |
deleteDeployment(String id) |
删除给定 |
|
方法 |
suspendProcessDefinitionById(String id) |
暂停给定 |
|
方法 |
activatedProcessDefinitionById(String id) |
激活给定 |
|
方法 |
suspendProcessDefinitionByKey(String id) |
暂停给定 |
|
方法 |
activatedProcessDefinitionByKey(String id) |
激活给定 |
|
方法 |
deployProcessDefinition(String resourceName, String processDefinitionFile) |
部署流程定义文件 |
|
JobExecutorMBean |
属性 |
isJobExecutorActivated |
返回作业执行器是否在运行 |
方法 |
setJobExecutorActivate(Boolean active) |
启用或停用作业执行器 |
19.1.4. 配置
JMX默认配置为最常使用的配置,以简化部署。但也可以很容易地以代码或配置文件的方式修改默认配置。下列代码展示了如何修改配置文件:
<bean id="processEngineConfiguration" class="...SomeProcessEngineConfigurationClass">
...
<property name="configurators">
<list>
<bean class="org.flowable.management.jmx.JMXConfigurator">
<property name="connectorPort" value="1912" />
<property name="serviceUrlPath" value="/jmxrmi/flowable" />
...
</bean>
</list>
</property>
</bean>下表展示了可配置的参数与其默认值:
| 名字 | 默认值 | 描述 |
|---|---|---|
disabled |
false |
若值为true,即使已添加依赖也不会启动JMX |
domain |
org.flowable.jmx.Mbeans |
MBean的域 |
createConnector |
true |
若值为true,则会创建一个连接器至MbeanServer |
MBeanDomain |
DefaultDomain |
MBean服务器的域 |
registryPort |
1099 |
注册端口,组成服务URL |
serviceUrlPath |
/jmxrmi/flowable |
组成服务URL |
connectorPort |
-1 |
如果大于0,则作为连接端口组成服务URL |
19.1.5. JMX服务URL
JMX服务URL格式如下:
service:jmx:rmi://<hostName>:<connectorPort>/jndi/rmi://<hostName>:<registryPort>/<serviceUrlPath>
hostName自动设置为机器的网络名。可以配置connectorPort、registryPort与serviceUrlPath。
如果connectionPort小于0,则服务URL不包括这部分,简化为:
service:jmx:rmi:///jndi/rmi://:<hostname>:<registryPort>/<serviceUrlPath>
19.2. Maven脚手架
19.2.1. 创建测试用例
在开发过程中,有时会需要在实际实现前,先构建一个小型的测试用例来测试想法或功能。这样可以用测试来明确目标。JUnit测试用例也是沟通功能需求及报告Bug的推荐工具。在一份bug报告或功能需求jira单中附加一个测试用例,可以显著减少修复所用的时间。
用maven脚手架可以快速创建标准测试用例,简化测试用例的创建过程。标准库中应该已经有脚手架了。如果没有,也可以在tooling/archtypes目录下键入mvn install,轻松安装到本地maven仓库目录中。
使用下列命令创建单元测试项目:
mvn archetype:generate \
-DarchetypeGroupId=org.flowable \
-DarchetypeArtifactId=flowable-archetype-unittest \
-DarchetypeVersion=<current version> \
-DgroupId=org.myGroup \
-DartifactId=myArtifact下表介绍每个参数的作用:
行 |
参数 |
说明 |
1 |
archetypeGroupId |
脚手架的Group id。需要为org.flowable |
2 |
archetypeArtifactId |
脚手架Artifact id。需要为flowable-archetype-unittest |
3 |
archetypeVersion |
生成的测试项目中使用的Flowable版本 |
4 |
groupId |
生成的测试项目的Group id |
5 |
artifactId |
生成的测试项目的Artifact id |
生成的项目的目录结构像是这样:
.
├── pom.xml
└── src
└── test
├── java
│ └── org
│ └── myGroup
│ └── MyUnitTest.java
└── resources
├── flowable.cfg.xml
├── log4j.properties
└── org
└── myGroup
└── my-process.bpmn20.xml
可以修改java单元测试用例及相应的流程模型,或者添加新的单元测试用例与流程模型。 如果用该项目来描述bug或功能,测试用例应该在初始时失败,并在修复了bug或实现了预期的功能以后成功。 请确保在发送之前键入mvn clean清理项目。